版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
scrapy之分布式爬虫:
修改该settings中的配置信息:
替换scrapy调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
添加pipeline
如果添加这行配置,每次爬取的数据也都会入到redis数据库中,所以一般这里不做这个配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
共享的爬取队列,这里用需要redis的连接信息
这里的user:pass表示用户名和密码,如果没有则为空就可以
REDIS_URL = 'redis://user:pass@hostname:9001'
设置为为True则不会清空redis里的dupefilter和requests队列
这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置
SCHEDULER_PERSIST = True
设置重启爬虫时是否清空爬取队列
这样每次重启爬虫都会清空指纹和请求队列,一般设置为False
SCHEDULER_FLUSH_ON_START=True

扫描二维码关注公众号,回复:
7607020 查看本文章

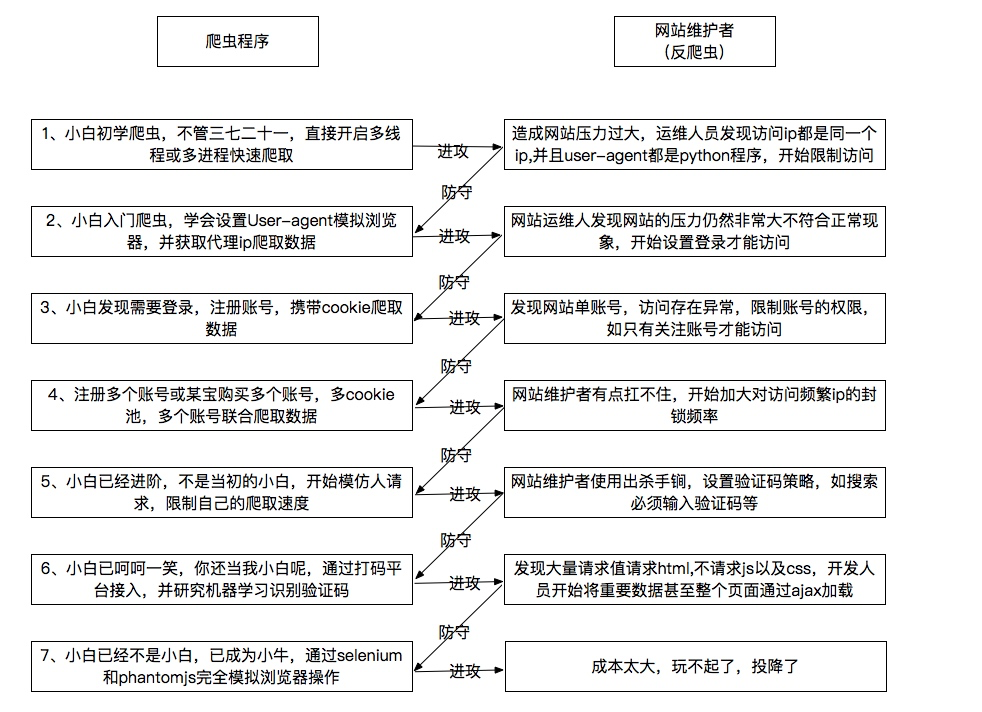
爬虫与反爬虫的乐趣: