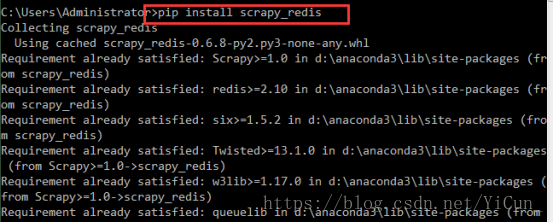
1. 首先使用命令行工具下载工具包 scrapy_redis
(如果使用的是虚拟环境,先进入到虚拟环境)
scrapy-redis:一个三方的基于redis的分布式爬虫框架,配合scrapy使用,让爬虫具有了分布式爬取的功能
github地址: https://github.com/darkrho/scrapy-redis
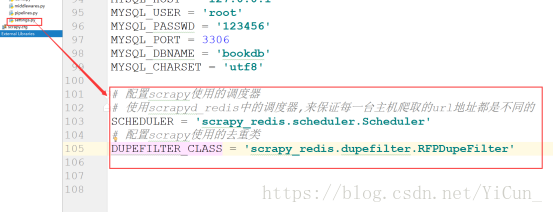
2.打开项目配置settings
找到settings文件,配置scrapy项目使用的调度器及过滤器
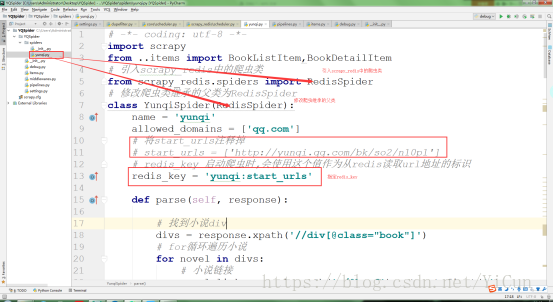
3. 修改爬虫文件
4.如果有连接远程服务,需要将远程服务连接开启
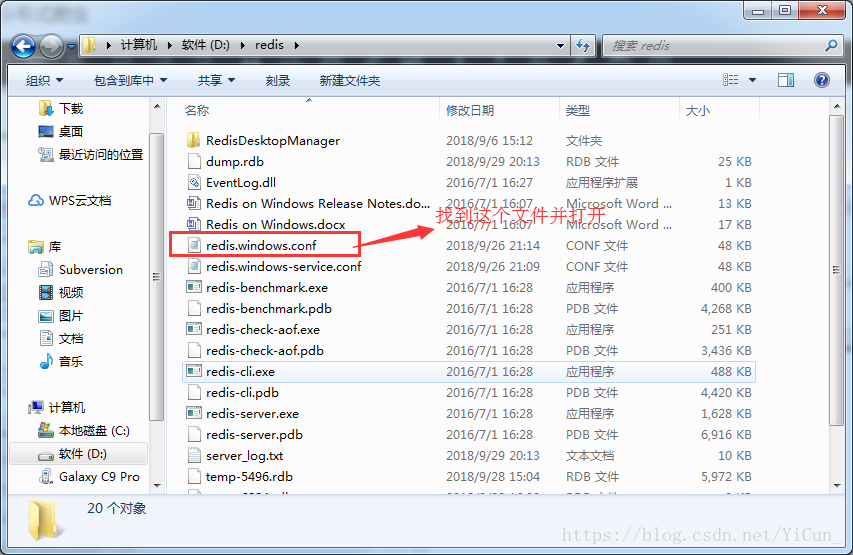
首先找到redis的安装目录
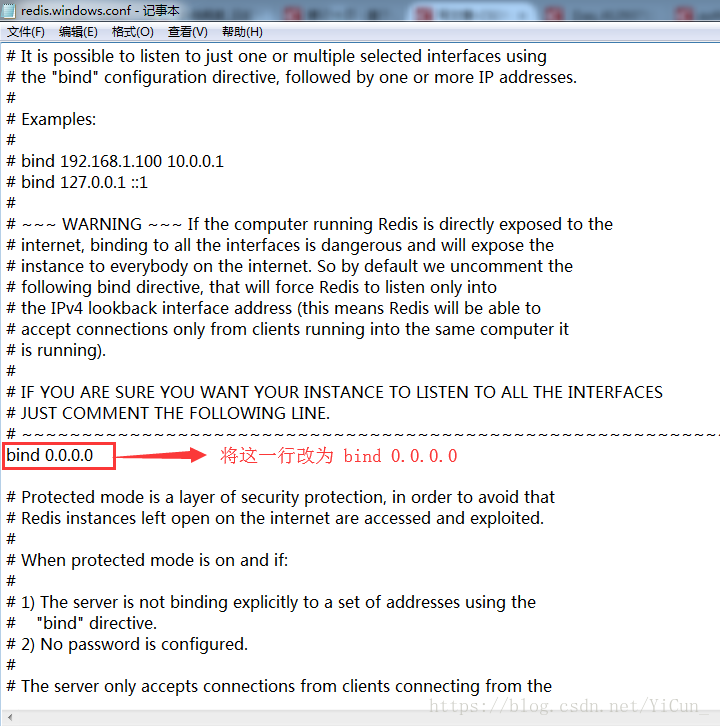
打开redis.windows.conf文件,并将下图一行改为
bind 0.0.0.0
是为了确保其他主机可以连接你的主机
用命令行进去到redis目录下, 输入redis-cli.exe -h + ip地址
可以测试是否可以远程连接redis
5.开启爬虫
测试远程可以连接redis后就可以开启你的爬虫项目
然后你会发现你的项目会进入等待状态
这个时候用命令行工具进入redis目录下 输入redis-cli.exe
然后lpush 输入你再项目中配置的redis_key
再输入你想爬取的第一个url 可以输入多个url 每个url用空格隔开
这样用scrapy_redis部署的分布式爬虫就开始爬取了
效果:所有爬虫都开始运行,并且每台主机爬取的数据还都不一样
最后将数据保存到你这台主机的redis数据库中
基于scrapy_redis部署的scrapy分布式爬虫



猜你喜欢
转载自blog.csdn.net/YiCun_/article/details/82902523
今日推荐
周排行