题目描述
Adrian对单词押韵很感兴趣。如果两个单词的最长公共后缀的长度与两个单词中较长那个的长度一样,或者等于较长单词的长度减一,则这两个单词押韵。换句话说,如果A,B的最长公共后缀LCS(A,B)≥max(|A|,|B|)-1,则A和B押韵。
有一天,在阅读一套短篇小说时,他决定创造出能够使每两个相邻单词押韵的最长的单词序列,序列中的每个单词只能出现一次。但是Adrian已经厌倦了这个任务,所以他决定回去读小说,并要求你代替他解决这个任务。
输入格式
第一行输入包含整数N(1≤N≤5*1e5)。表示单词的个数。
接下来N行每行包含一个只由小写英文字母组成的字符串。表示可以用于组成序列的单词。数据保证每个单词都是不同的,保证所有单词的长度之和不超过3*1e6。
输出格式
输出一个整数。表示单词序列的最长长度。
样例
样例输入1
4 honi toni oni ovi样例输出1
3样例输入2
5 ask psk krafna sk k样例输出2
4样例输入3
5 pas kompas stas s nemarime样例输出3
1
思路详解
首先可以知道要用字典树,将输入的字符串反向插入字典树(这里有个坑“保证所有单词的长度之和不超过3*1e6”,无数次RE的血的教训啊!!!)
for( int i = 1 ; i <= n ; ++ i ) {
string a ;
cin >> a ;
reverse( a.begin() , a.end() );
iinsert(a);
}reverse就是将这个串反向倒置(想了解的点进来)
然后看一下数据,有点大,卡空间啊,字典树不能直接暴力开26来存子节点,用vector来存
vector类型为pair,一个为字符,另一个为子节点编号
struct node {
int sum ;//以该节点为根节点的子树最长序列
bool End ;//是否为终节点
vector< pair< char,int > > to ;// char存该字符,int存子节点编号
}Trie[MAXN];然后就解决了卡空间的问题
求最长序列,不难看出这要树形DP(毒瘤啊)
“换句话说,如果A,B的最长公共后缀LCS(A,B)≥max(|A|,|B|)-1,则A和B押韵。”,可以看出这个序列只能连续包含节点的儿子或兄弟(相差距离为0或1及深度相差为1或0)
然后处理树DP
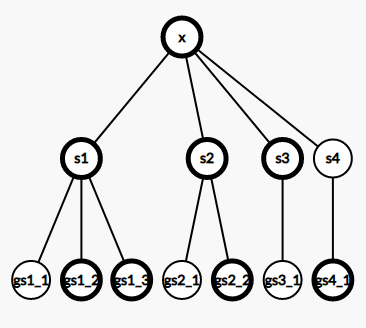
如在x节点(有深色标记的为终节点),不难发现子序列最长为s1的,次长为s2 , x的最长就是s1+s2+s3,而如果又有一个次次小序列,能否把他也加入x的最长序列呢,显然是不能的,因为要每两个相邻,所以如果加上次次小序列会发现有串会不满足条件,即以x为中转点只能连接两个儿子(很难想,要自己去推,不好口述)
要经过自己的一番思考,可以得出x的最长序列为其最长子序列加次长子序列再加上儿子为终结点的个数
max_ans = max1 + max2 + Trie[x].End + max(0,sum_son-2) ;//计算当前的最最长的序列
ans = max( ans , max_ans );//更新答案
//max1为最大子序列,max2为次大子序列
//Trie[x].End表示为该节点是否为终节点,sum_son为子节点为终节点的个数
//max1,max2已经包含了sum_son的两个节点,要减去然后就可以快乐的DP了
代码
代码详解,消化理解。。。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <algorithm>
#include <cmath>
#include <vector>
#define MAXN 3000005
using namespace std;
int n , ans , cnt , p ;
struct node {
int sum ;//以该节点为根节点的子树最长序列
bool End ;//是否为终节点
vector< pair< char,int > > to ;// char存该字符,int存子节点编号
}Trie[MAXN];
void iinsert( string a ) {//字典树插入
int len = a.length() ;
p = 0 ;
for( int i = 0 ; i < len ; ++ i ) {
int get = -5 ;
for( int j = 0 ; j < Trie[p].to.size() ; ++ j ) {//查找是否有路径
if( Trie[p].to[j].first == a[i] ) {//找到
get = Trie[p].to[j].second ;
break ;
}
}
if( get == -5 ) {//没找到
cnt ++ ;
get = cnt ;
Trie[p].to.push_back( make_pair(a[i],cnt) );
}
p = get ;
}
Trie[p].End = 1 ;//标记终节点
}
void DFS( int x ) {//树DP
int sum_son = 0 , max_ans = 0 ;//sum_son为子节点为终节点的个数
int max1 = 0 , max2 = 0 ;//max1为最大的子节点的序列长,max2为次大
for( int i = 0 ; i < Trie[x].to.size() ; ++ i ) {
int s = Trie[x].to[i].second ;
DFS(s);
sum_son += Trie[s].End ;
if( Trie[s].sum > max1 )//更新最大
max2 = max1 , max1 = Trie[s].sum ;
else if( Trie[s].sum > max2 )//更新次大
max2 = Trie[s].sum ;
Trie[x].sum = max( Trie[x].sum , Trie[s].sum );//更新当前节点最长链(此时Trie[s].sum包含一个子节点)
}
if( Trie[x].End )
Trie[x].sum += max(1,sum_son);//加上自己或满足条件的子节点加自己(在Trie[x].sum包含一个子节点)
else Trie[x].sum = 0 ;
max_ans = max1 + max2 + Trie[x].End + max(0,sum_son-2) ;//计算当前的最最长的序列
ans = max( ans , max_ans );//更新答案
}
int main() {
scanf("%d", &n );
for( int i = 1 ; i <= n ; ++ i ) {
string a ;
cin >> a ;
reverse( a.begin() , a.end() );//反向一下
iinsert(a);
}
DFS(0);
printf("%d", ans );
return 0;
}