MobileNet V1
MobileNet主要是针对移动端或者嵌入式设备优化的卷积。
特点:
(1)放弃pooling直接采用stride = 2进行卷积运算。
(2)使用depthwise separable convolutions。
(3)用两个超参数来控制网络计算速度与准确度之间的平衡,宽度调节参数和分辨率参数,主要用于压缩模型。
Depthwise separable convolution 深度级可分离卷积
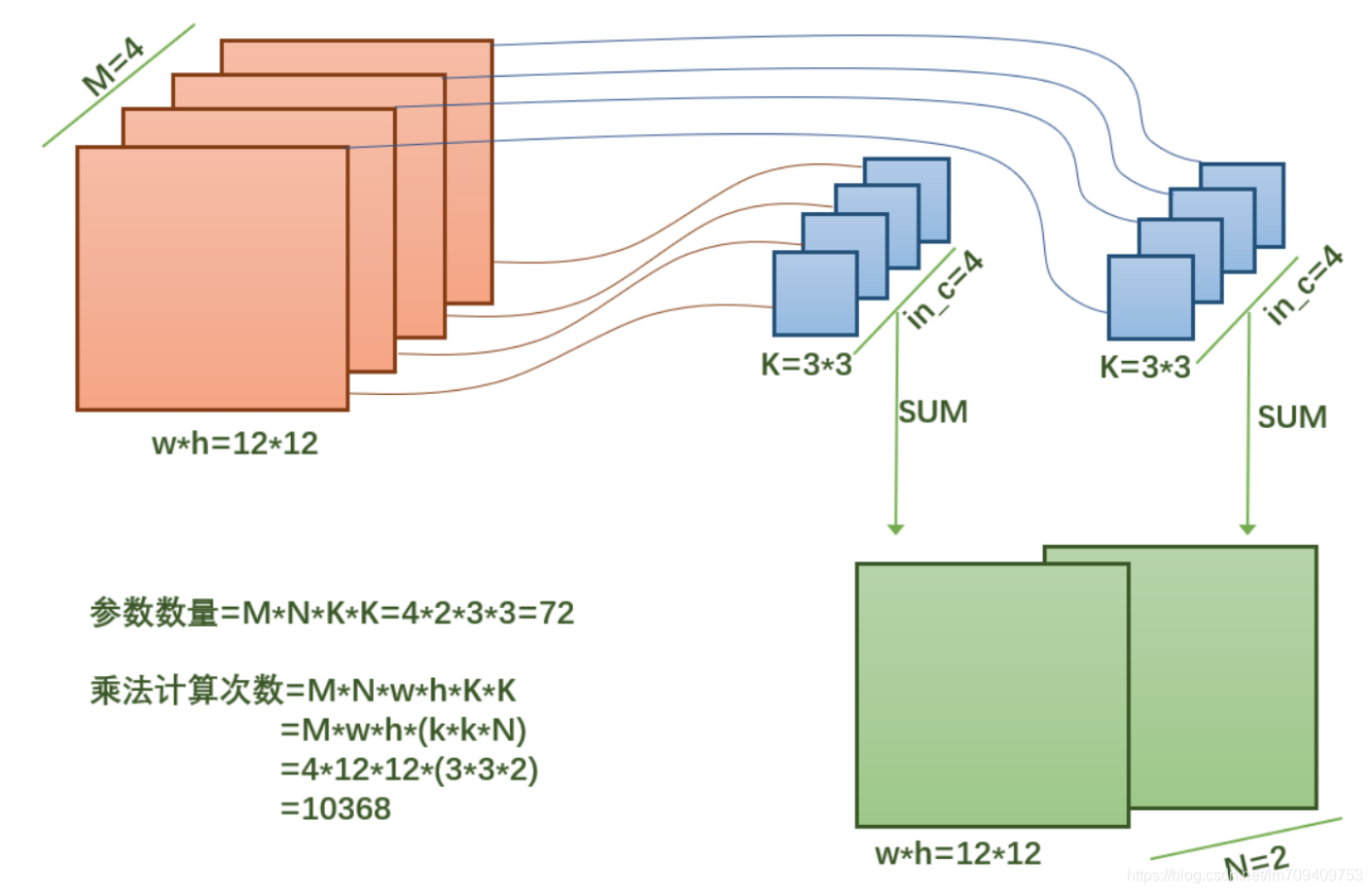
上图为普通卷积过程。每个卷积核的深度和图像的深度是一样的,每个卷积核的各个层计算之后相加得到最后的结果。卷积核的通道数等于输入特征图的通道数。
相比普通卷积,MobileNet采用的方法是,将卷积分解为2个操作:depthwise和pointwise。pointwise比较容易理解,就是普通的卷积核为1*1的卷积。depthwise卷积核的通道数为1。
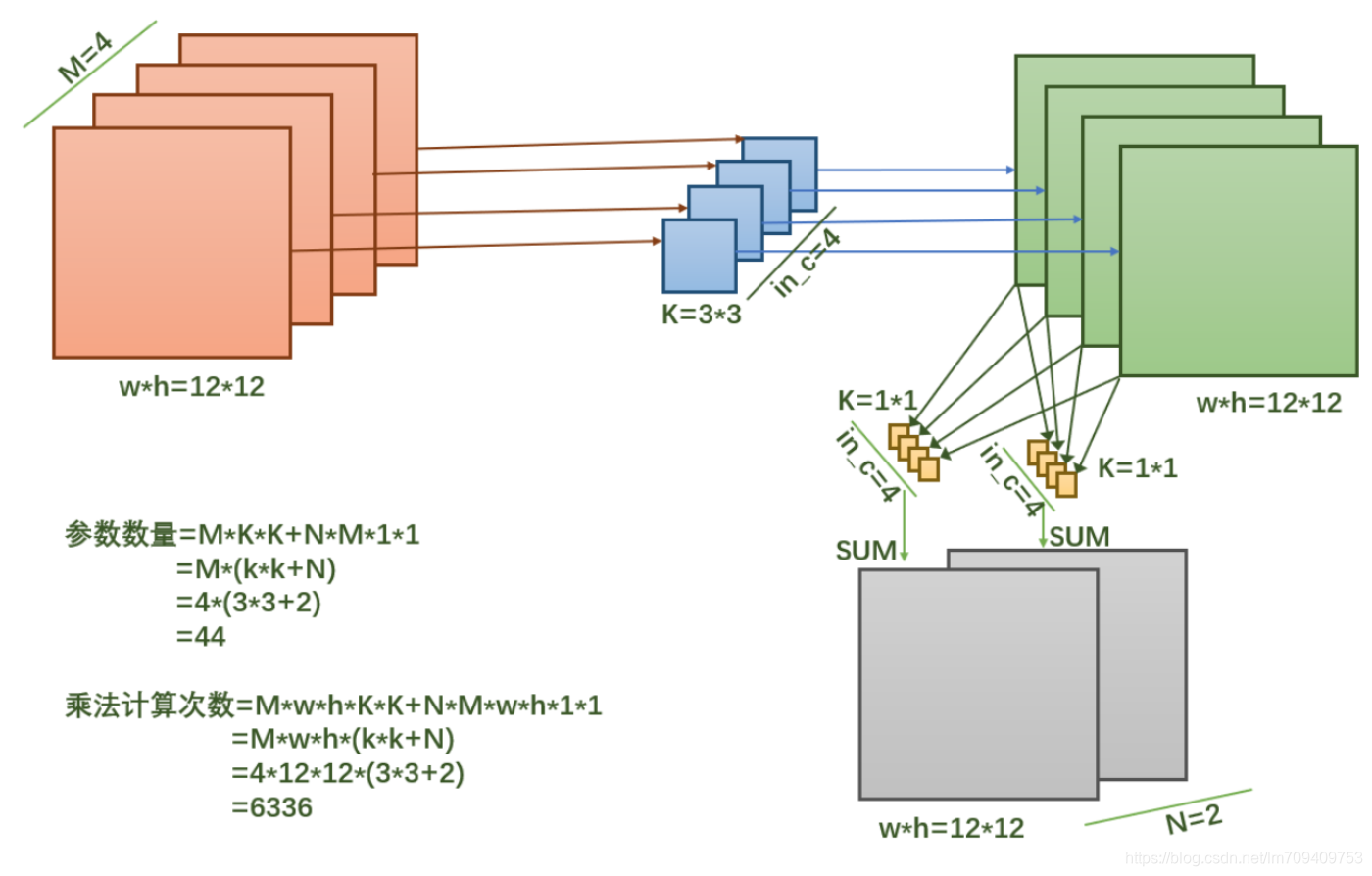
深度可分离卷积将以往普通卷积操作同时考虑通道和区域改变(卷积先只考虑区域,然后再考虑通道),实现了通道和区域的分离。
可以比较depthwise separable convolution和标准卷积计算量的比值:
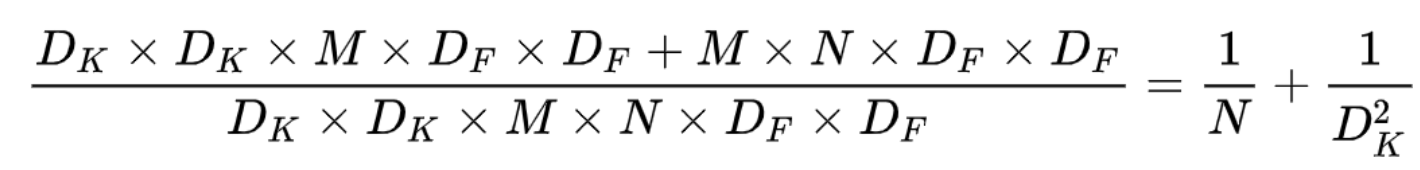
可以看出,使用depthwise separable convolution计算量和参数数量都会减少。
网络结构
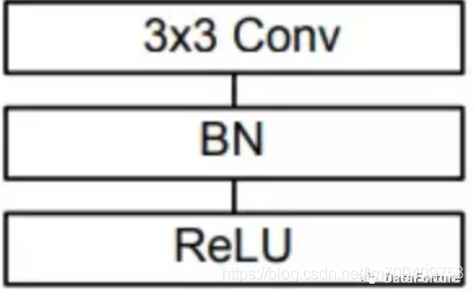
标准卷积结构图
depthwise separable convolution
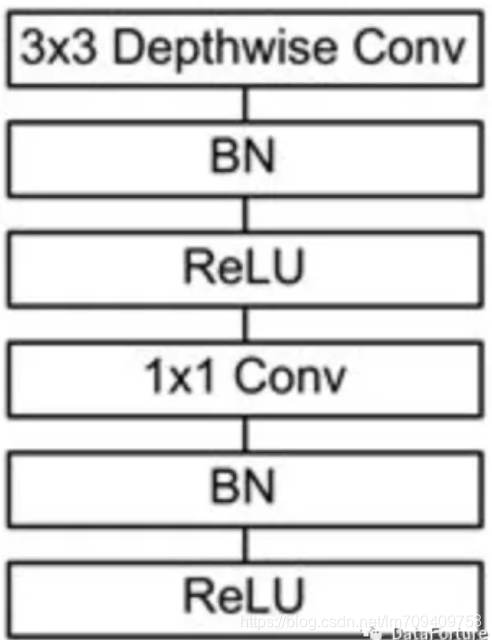
depthwise separable convolution是MobileNet的基本组件,在真正应用中会加入Batch Normalization(BN)。在每次SGD(随机梯度下降)时,通过mini-batch来对相应的activation做规范化操作,使得输出信号各个维度的均值为0,方差为1。
Mobilenet 网络结构
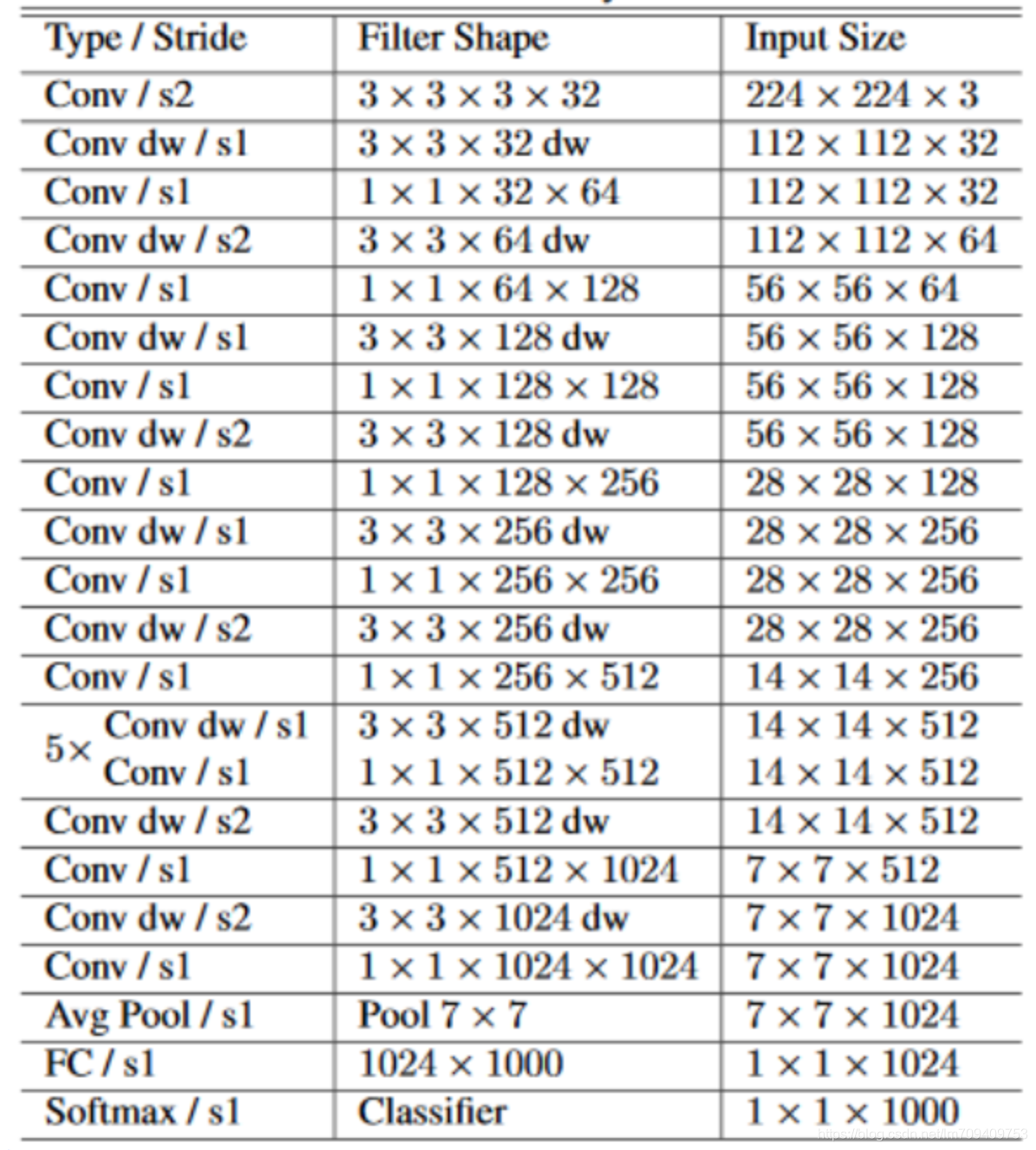
项目中使用MobileNet作为前置网络,主要用于特征特取。
Code
"""MobileNet v1 models for Keras.
MobileNet is a general architecture and can be used for multiple use cases.
Depending on the use case, it can use different input layer size and
different width factors. This allows different width models to reduce
the number of multiply-adds and thereby
reduce inference cost on mobile devices.
MobileNets support any input size greater than 32 x 32, with larger image sizes
offering better performance.
The number of parameters and number of multiply-adds
can be modified by using the `alpha` parameter,
which increases/decreases the number of filters in each layer.
By altering the image size and `alpha` parameter,
all 16 models from the paper can be built, with ImageNet weights provided.
The paper demonstrates the performance of MobileNets using `alpha` values of
1.0 (also called 100 % MobileNet), 0.75, 0.5 and 0.25.
For each of these `alpha` values, weights for 4 different input image sizes
are provided (224, 192, 160, 128).
The following table describes the size and accuracy of the 100% MobileNet
on size 224 x 224:
----------------------------------------------------------------------------
Width Multiplier (alpha) | ImageNet Acc | Multiply-Adds (M) | Params (M)
----------------------------------------------------------------------------
| 1.0 MobileNet-224 | 70.6 % | 529 | 4.2 |
| 0.75 MobileNet-224 | 68.4 % | 325 | 2.6 |
| 0.50 MobileNet-224 | 63.7 % | 149 | 1.3 |
| 0.25 MobileNet-224 | 50.6 % | 41 | 0.5 |
----------------------------------------------------------------------------
The following table describes the performance of
the 100 % MobileNet on various input sizes:
------------------------------------------------------------------------
Resolution | ImageNet Acc | Multiply-Adds (M) | Params (M)
------------------------------------------------------------------------
| 1.0 MobileNet-224 | 70.6 % | 529 | 4.2 |
| 1.0 MobileNet-192 | 69.1 % | 529 | 4.2 |
| 1.0 MobileNet-160 | 67.2 % | 529 | 4.2 |
| 1.0 MobileNet-128 | 64.4 % | 529 | 4.2 |
------------------------------------------------------------------------
The weights for all 16 models are obtained and translated
from TensorFlow checkpoints found at
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md
# Reference
- [MobileNets: Efficient Convolutional Neural Networks for
Mobile Vision Applications](https://arxiv.org/pdf/1704.04861.pdf))
"""
from __future__ import print_function
from __future__ import absolute_import
from __future__ import division
import os
import warnings
from . import get_submodules_from_kwargs
from . import imagenet_utils
from .imagenet_utils import decode_predictions
from .imagenet_utils import _obtain_input_shape
BASE_WEIGHT_PATH = ('https://github.com/fchollet/deep-learning-models/'
'releases/download/v0.6/')
backend = None
layers = None
models = None
keras_utils = None
def preprocess_input(x, **kwargs):
"""Preprocesses a numpy array encoding a batch of images.
# Arguments
x: a 4D numpy array consists of RGB values within [0, 255].
# Returns
Preprocessed array.
"""
return imagenet_utils.preprocess_input(x, mode='tf', **kwargs)
def MobileNet(input_shape=None,
alpha=1.0,
depth_multiplier=1,
dropout=1e-3,
include_top=True,
weights='imagenet',
input_tensor=None,
pooling=None,
classes=1000,
**kwargs):
"""Instantiates the MobileNet architecture.
# Arguments
input_shape: optional shape tuple, only to be specified
if `include_top` is False (otherwise the input shape
has to be `(224, 224, 3)`
(with `channels_last` data format)
or (3, 224, 224) (with `channels_first` data format).
It should have exactly 3 inputs channels,
and width and height should be no smaller than 32.
E.g. `(200, 200, 3)` would be one valid value.
alpha: controls the width of the network. This is known as the
width multiplier in the MobileNet paper.
- If `alpha` < 1.0, proportionally decreases the number
of filters in each layer.
- If `alpha` > 1.0, proportionally increases the number
of filters in each layer.
- If `alpha` = 1, default number of filters from the paper
are used at each layer.
depth_multiplier: depth multiplier for depthwise convolution. This
is called the resolution multiplier in the MobileNet paper.
dropout: dropout rate
include_top: whether to include the fully-connected
layer at the top of the network.
weights: one of `None` (random initialization),
'imagenet' (pre-training on ImageNet),
or the path to the weights file to be loaded.
input_tensor: optional Keras tensor (i.e. output of
`layers.Input()`)
to use as image input for the model.
pooling: Optional pooling mode for feature extraction
when `include_top` is `False`.
- `None` means that the output of the model
will be the 4D tensor output of the
last convolutional block.
- `avg` means that global average pooling
will be applied to the output of the
last convolutional block, and thus
the output of the model will be a
2D tensor.
- `max` means that global max pooling will
be applied.
classes: optional number of classes to classify images
into, only to be specified if `include_top` is True, and
if no `weights` argument is specified.
# Returns
A Keras model instance.
# Raises
ValueError: in case of invalid argument for `weights`,
or invalid input shape.
RuntimeError: If attempting to run this model with a
backend that does not support separable convolutions.
"""
global backend, layers, models, keras_utils
backend, layers, models, keras_utils = get_submodules_from_kwargs(kwargs)
if not (weights in {'imagenet', None} or os.path.exists(weights)):
raise ValueError('The `weights` argument should be either '
'`None` (random initialization), `imagenet` '
'(pre-training on ImageNet), '
'or the path to the weights file to be loaded.')
if weights == 'imagenet' and include_top and classes != 1000:
raise ValueError('If using `weights` as `"imagenet"` with `include_top` '
'as true, `classes` should be 1000')
# Determine proper input shape and default size.
if input_shape is None:
default_size = 224
else:
if backend.image_data_format() == 'channels_first':
rows = input_shape[1]
cols = input_shape[2]
else:
rows = input_shape[0]
cols = input_shape[1]
if rows == cols and rows in [128, 160, 192, 224]:
default_size = rows
else:
default_size = 224
input_shape = _obtain_input_shape(input_shape,
default_size=default_size,
min_size=32,
data_format=backend.image_data_format(),
require_flatten=include_top,
weights=weights)
if backend.image_data_format() == 'channels_last':
row_axis, col_axis = (0, 1)
else:
row_axis, col_axis = (1, 2)
rows = input_shape[row_axis]
cols = input_shape[col_axis]
if weights == 'imagenet':
if depth_multiplier != 1:
raise ValueError('If imagenet weights are being loaded, '
'depth multiplier must be 1')
if alpha not in [0.25, 0.50, 0.75, 1.0]:
raise ValueError('If imagenet weights are being loaded, '
'alpha can be one of'
'`0.25`, `0.50`, `0.75` or `1.0` only.')
if rows != cols or rows not in [128, 160, 192, 224]:
if rows is None:
rows = 224
warnings.warn('MobileNet shape is undefined.'
' Weights for input shape '
'(224, 224) will be loaded.')
else:
raise ValueError('If imagenet weights are being loaded, '
'input must have a static square shape '
'(one of (128, 128), (160, 160), '
'(192, 192), or (224, 224)). '
'Input shape provided = %s' % (input_shape,))
if backend.image_data_format() != 'channels_last':
warnings.warn('The MobileNet family of models is only available '
'for the input data format "channels_last" '
'(width, height, channels). '
'However your settings specify the default '
'data format "channels_first" (channels, width, height).'
' You should set `image_data_format="channels_last"` '
'in your Keras config located at ~/.keras/keras.json. '
'The model being returned right now will expect inputs '
'to follow the "channels_last" data format.')
backend.set_image_data_format('channels_last')
old_data_format = 'channels_first'
else:
old_data_format = None
if input_tensor is None:
img_input = layers.Input(shape=input_shape)
else:
if not backend.is_keras_tensor(input_tensor):
img_input = layers.Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
x = _conv_block(img_input, 32, alpha, strides=(2, 2))
x = _depthwise_conv_block(x, 64, alpha, depth_multiplier, block_id=1)
x = _depthwise_conv_block(x, 128, alpha, depth_multiplier,
strides=(2, 2), block_id=2)
x = _depthwise_conv_block(x, 128, alpha, depth_multiplier, block_id=3)
x = _depthwise_conv_block(x, 256, alpha, depth_multiplier,
strides=(2, 2), block_id=4)
x = _depthwise_conv_block(x, 256, alpha, depth_multiplier, block_id=5)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier,
strides=(2, 2), block_id=6)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=7)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=8)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=9)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=10)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=11)
x = _depthwise_conv_block(x, 1024, alpha, depth_multiplier,
strides=(2, 2), block_id=12)
x = _depthwise_conv_block(x, 1024, alpha, depth_multiplier, block_id=13)
if include_top:
if backend.image_data_format() == 'channels_first':
shape = (int(1024 * alpha), 1, 1)
else:
shape = (1, 1, int(1024 * alpha))
x = layers.GlobalAveragePooling2D()(x)
x = layers.Reshape(shape, name='reshape_1')(x)
x = layers.Dropout(dropout, name='dropout')(x)
x = layers.Conv2D(classes, (1, 1),
padding='same',
name='conv_preds')(x)
x = layers.Activation('softmax', name='act_softmax')(x)
x = layers.Reshape((classes,), name='reshape_2')(x)
else:
if pooling == 'avg':
x = layers.GlobalAveragePooling2D()(x)
elif pooling == 'max':
x = layers.GlobalMaxPooling2D()(x)
# Ensure that the model takes into account
# any potential predecessors of `input_tensor`.
if input_tensor is not None:
inputs = keras_utils.get_source_inputs(input_tensor)
else:
inputs = img_input
# Create model.
model = models.Model(inputs, x, name='mobilenet_%0.2f_%s' % (alpha, rows))
# Load weights.
if weights == 'imagenet':
if backend.image_data_format() == 'channels_first':
raise ValueError('Weights for "channels_first" format '
'are not available.')
if alpha == 1.0:
alpha_text = '1_0'
elif alpha == 0.75:
alpha_text = '7_5'
elif alpha == 0.50:
alpha_text = '5_0'
else:
alpha_text = '2_5'
if include_top:
model_name = 'mobilenet_%s_%d_tf.h5' % (alpha_text, rows)
weight_path = BASE_WEIGHT_PATH + model_name
weights_path = keras_utils.get_file(model_name,
weight_path,
cache_subdir='models')
else:
model_name = 'mobilenet_%s_%d_tf_no_top.h5' % (alpha_text, rows)
weight_path = BASE_WEIGHT_PATH + model_name
weights_path = keras_utils.get_file(model_name,
weight_path,
cache_subdir='models')
model.load_weights(weights_path)
elif weights is not None:
model.load_weights(weights)
if old_data_format:
backend.set_image_data_format(old_data_format)
return model
def _conv_block(inputs, filters, alpha, kernel=(3, 3), strides=(1, 1)):
"""Adds an initial convolution layer (with batch normalization and relu6).
# Arguments
inputs: Input tensor of shape `(rows, cols, 3)`
(with `channels_last` data format) or
(3, rows, cols) (with `channels_first` data format).
It should have exactly 3 inputs channels,
and width and height should be no smaller than 32.
E.g. `(224, 224, 3)` would be one valid value.
filters: Integer, the dimensionality of the output space
(i.e. the number of output filters in the convolution).
alpha: controls the width of the network.
- If `alpha` < 1.0, proportionally decreases the number
of filters in each layer.
- If `alpha` > 1.0, proportionally increases the number
of filters in each layer.
- If `alpha` = 1, default number of filters from the paper
are used at each layer.
kernel: An integer or tuple/list of 2 integers, specifying the
width and height of the 2D convolution window.
Can be a single integer to specify the same value for
all spatial dimensions.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution
along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
Specifying any stride value != 1 is incompatible with specifying
any `dilation_rate` value != 1.
# Input shape
4D tensor with shape:
`(samples, channels, rows, cols)` if data_format='channels_first'
or 4D tensor with shape:
`(samples, rows, cols, channels)` if data_format='channels_last'.
# Output shape
4D tensor with shape:
`(samples, filters, new_rows, new_cols)`
if data_format='channels_first'
or 4D tensor with shape:
`(samples, new_rows, new_cols, filters)`
if data_format='channels_last'.
`rows` and `cols` values might have changed due to stride.
# Returns
Output tensor of block.
"""
channel_axis = 1 if backend.image_data_format() == 'channels_first' else -1
filters = int(filters * alpha)
x = layers.ZeroPadding2D(padding=((0, 1), (0, 1)), name='conv1_pad')(inputs)
x = layers.Conv2D(filters, kernel,
padding='valid',
use_bias=False,
strides=strides,
name='conv1')(x)
x = layers.BatchNormalization(axis=channel_axis, name='conv1_bn')(x)
return layers.ReLU(6., name='conv1_relu')(x)
def _depthwise_conv_block(inputs, pointwise_conv_filters, alpha,
depth_multiplier=1, strides=(1, 1), block_id=1):
"""Adds a depthwise convolution block.
A depthwise convolution block consists of a depthwise conv,
batch normalization, relu6, pointwise convolution,
batch normalization and relu6 activation.
# Arguments
inputs: Input tensor of shape `(rows, cols, channels)`
(with `channels_last` data format) or
(channels, rows, cols) (with `channels_first` data format).
pointwise_conv_filters: Integer, the dimensionality of the output space
(i.e. the number of output filters in the pointwise convolution).
alpha: controls the width of the network.
- If `alpha` < 1.0, proportionally decreases the number
of filters in each layer.
- If `alpha` > 1.0, proportionally increases the number
of filters in each layer.
- If `alpha` = 1, default number of filters from the paper
are used at each layer.
depth_multiplier: The number of depthwise convolution output channels
for each input channel.
The total number of depthwise convolution output
channels will be equal to `filters_in * depth_multiplier`.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution
along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
Specifying any stride value != 1 is incompatible with specifying
any `dilation_rate` value != 1.
block_id: Integer, a unique identification designating
the block number.
# Input shape
4D tensor with shape:
`(batch, channels, rows, cols)` if data_format='channels_first'
or 4D tensor with shape:
`(batch, rows, cols, channels)` if data_format='channels_last'.
# Output shape
4D tensor with shape:
`(batch, filters, new_rows, new_cols)`
if data_format='channels_first'
or 4D tensor with shape:
`(batch, new_rows, new_cols, filters)`
if data_format='channels_last'.
`rows` and `cols` values might have changed due to stride.
# Returns
Output tensor of block.
"""
channel_axis = 1 if backend.image_data_format() == 'channels_first' else -1
pointwise_conv_filters = int(pointwise_conv_filters * alpha)
if strides == (1, 1):
x = inputs
else:
x = layers.ZeroPadding2D(((0, 1), (0, 1)),
name='conv_pad_%d' % block_id)(inputs)
x = layers.DepthwiseConv2D((3, 3),
padding='same' if strides == (1, 1) else 'valid',
depth_multiplier=depth_multiplier,
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(x)
x = layers.BatchNormalization(
axis=channel_axis, name='conv_dw_%d_bn' % block_id)(x)
x = layers.ReLU(6., name='conv_dw_%d_relu' % block_id)(x)
x = layers.Conv2D(pointwise_conv_filters, (1, 1),
padding='same',
use_bias=False,
strides=(1, 1),
name='conv_pw_%d' % block_id)(x)
x = layers.BatchNormalization(axis=channel_axis,
name='conv_pw_%d_bn' % block_id)(x)
return layers.ReLU(6., name='conv_pw_%d_relu' % block_id)(x)
⚠️总结项目涉及的知识点,学会总结。
参考博客:
https://cuijiahua.com/blog/2018/02/dl_6.html
https://blog.csdn.net/huachao1001/article/details/79171447
欢迎关注个人微信公众号
