摘要
最近出了一篇旷视科技的孙剑团队出了一篇关于利用Channel Shuffle实现的卷积网络优化——ShuffleNet。我关注了一下,原理相当简单。它只是为了解决分组卷积时,不同feature maps分组之间的channels信息交互问题,而提出Channel Shuffle操作为不同分组提供channels信息的通信的渠道。然而,当我读到ShuffleNet Unit和Network Architecture的章节,考虑如何复现作者的实验网络时,总感觉看透这个网络的实现,尤其是我验算Table 1的结果时,总出现各种不对。因此我将作者引用的最近几个比较火的网络优化结构(MobileNet,Xception,ResNeXt)学习了一下,终于在ResNeXt的引导下,把作者的整个实现搞清楚了。顺带着,我也把这项技术的发展情况屡了一下,产生了一些个人看法,就写下这篇学习笔记。
关键词
MobileNet,Xception,ResNeXt,ShuffleNet, MobileID
前言
自从2016年3月,谷歌用一场围棋比赛把人工智能(AI, Artificial Intelligence)正式推上了风口。深度学习突然间成为了整个IT行业的必备知识,不掌握也需要去了解。然而,在2014年我刚毕业的时候,这项技术并没有现在那么火。当时概念大家都还是比较模糊,我也只是在实习听报告时,听邵岭博士提了一下,却没想到现在已经成为模式识别界的一枚巨星。尽管我后悔当时没在这块狠下功夫,但庆幸还能赶上末班船的站票。
CNN的提出其实很早,在1985年Hinton就提出了BP(反向传播算法),1998年LeCun就基于这项工作发表了LeNet用于解决手写邮政编码的识别问题。之后这项技术很少人去接触,有观点认为当时并没有资源能承担CNN的计算消耗。而它的转折点却是十多年后,在ImageNet比赛中,Alex在Nvidia的两GPU上跑他设计的AlexNet架构,成功在众人面前秀了一把CNN的并行计算操作并一举夺冠,吸引了少量学者眼球。两年过去,VGG和GoogLeNet在ImageNet上展开冠军争夺战,标志着深度学习正式起跑,业界开始关注并尝试利用CNN解决一些过去的难题,比如目标跟踪,目标检测,人脸识别等,它这些领域也得到了不少突破。
然而,CNN的这些突破大多都是在计算代价巨大的条件下产生的,比方说令人目瞪狗呆的千层网络—ResNet。其实这并不利于深度学习在消费类产业的推广,毕竟消费类产品很多是嵌入式的终端产品,而且嵌入式芯片的计算性能并不很强。即使我们考虑云计算,也需要消耗大量的带宽资源和计算资源。因此,CNN的优化已成为深度学习产品能否在消费市场落脚生根的一个重要课题之一。所以,有不少学者着手研究CNN的网络优化,如韩松的SqueezeNet,Deep Compression,LeCun的SVD,Google的MobileNet以及这个孙剑的ShuffleNet等。
其实,网络压缩优化的方法有两个发展方向,一个是迁移学习,另一个是网络稀疏。迁移学习是指一种学习对另一种学习的影响,好比我们常说的举一反三行为,以减少模型对数据量的依赖。不过,它也可以通过知识蒸馏实现大模型到小模型的迁移,这方面的工作有港中文汤晓鸥组的MobileID。他们运用模型压缩技术和domain knowledge,用小的网络去拟合大量的数据,并以大型teacher network的知识作为监督,训练了一个小而紧凑的student network打算将DeepID迁移到移动终端与嵌入式设备中。本文先不对这项工作进行详细介绍,后面打算再补充一篇相关博文。网络稀疏是现在比较主流的压缩优化方向,这方面的工作主要是以网络结构的剪枝和调整卷积方式为主。比如之前提到深度压缩,它先通过dropout,L1/L2-regularization等能产生权重稀疏性的方法训练体积和密度都很大的网络,然后把网络中贡献小(也就是被稀疏过的)的权重裁剪掉,相当于去除了一些冗余连接,最后对模型做一下fine-tune就得到他所说的30%压缩率的效果。但它在效率上的提高并不适合大多数的通用CPU,因为它的存储不连续,索引权重时容易发生Cache Miss,反而得不偿失。下面介绍的MobileNet在这方面更有优势。
MobileNet
MobileNet的主要工作是用depthwise sparable convolutions替代过去的standard convolutions来解决卷积网络的计算效率和参数量的问题。它默认一个假设,就是常规卷积核在feature maps的channels维度映射中,存在一种类似线性组合的分解特性。我们用K表示一个常规卷积核,则
MobileNet的Sparable Convolutions结构,除了上面提到的核分解压缩参数量,减少计算量的优点以外,它还有另一个很好的亮点就是,这种分离结构对现在绝大多数移动终端的CPU指令加速硬件,是非常友善的。这也是现在移动端的深度学习平台都必须要支持MobileNet(可分离卷积操作)的重要原因。
我大致分析一下这个点,我们先要了解SIMD硬件加速指令的概念。百度百科的概述是,“SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集”,它的硬件是一个大型寄存器,我原来芯片公司的SIMD矢量寄存器是128位,也就是一条指令译码后几个执行部件同时访问内存,一次性获得128位操作数进行运算,比如它能在一个cycle内完成16个8bit类型(128=16×8128=16×8)操作数加法运算。现在大部分ARM的移动终端产品都一套NEON指令集,这是基于ARM的128\256位SIMD寄存器集成的,最近它们还开源了名为ARM ComputeLirary的深度学习计算平台,里面的各种算子大量使用NEON指令和OpenCL库。这似乎意味着,图像处理这种数据密集型运算很适合利用SIMD指令加速来得到很高的效率,然而对于卷积神经网络而言结果并不那么理想。问题的主要原因在于读取内存,朴素的卷积运算是需要跨行取数的。
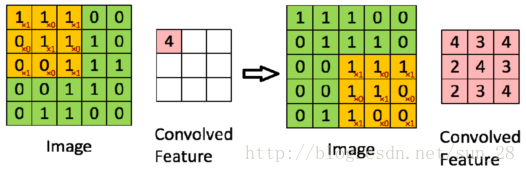
如上图所示,若我想得到Convolved Feature中的4,我需要从Image那里把黄色部分的[1,1,1,0,1,1,0,0,1]取出,并与卷积核[1,0,1,0,1,0,1,0,1]做内积(inner product)才能的到结果4。而Image的存储方式大多是行连续存储的,即Image=[1,1,1,0,0,0,1,1,…,0,0],然后我们就会发现当要取出[0,1,1]时,这个向量在内存上并不是紧接在[1,1,1]后面。我一条指令取出的8个数(假设16bit类型),其中就需要扔掉两个,这个例子是Image比较小的情况,实践中除前3个数以外,后面所有数都要丢弃。这种数据带宽的利用率很低,并且很容易引发Cache Miss问题,毕竟CPU都会做Cache数据预取控制,不连续的内存访问会影响这种控制的效果。CPU也会经常空闲,不会被有效利用。虽然也有不少人在卷积算子实现上下功夫缓解这个问题,但是也无非只是时间与空间上的妥协,难以真正克服这一矛盾。
MobileNet的可分离卷积结构对这个矛盾很有效果。

上图右边是一个可分离卷积模块,左边是常规卷积模块。如果它们的Input Channels数是nn Conv在实现当中仅是一个数乘向量运算,这相当适合SIMD的大数据访存机制,使得带宽和CPU能被有效利用。

简言之,正因为MobileNet的可分离卷积模块在压缩参数同时还压缩了计算量,还能充分发挥现代CPU计算能力与数据读取效率,再加上这些优化还不影响准确率,所以它被移动终端领域广泛应用。从下面的数据对比,我们可以看到参数和准确率差不多的情况下,MobileNet的计算量远小于SqueezeNet。而且SqueezeNet的Fire module实际上只是bottle neck module的变形与InceptionV1模块区别不大,只是少做了几种尺度的卷积而已。

Xception
Xception的主要工作是解释常规卷积(regular convolution
)如何从Inception模块过渡到可分离卷积(depthwise separable convolution)。它认为Inception模块背后有一个基本假设,就是输入通道间的相关性和空间相关性是可以退耦合的,即使不把它俩连接起来映射,也能达到很好的效果。它的提出背景是把一个卷积层看作三维空间的滤波器(2维平面空间+1维feature map通道),其中一个卷积核需要同时对通道间的相关性和空间相关性联合做映射。
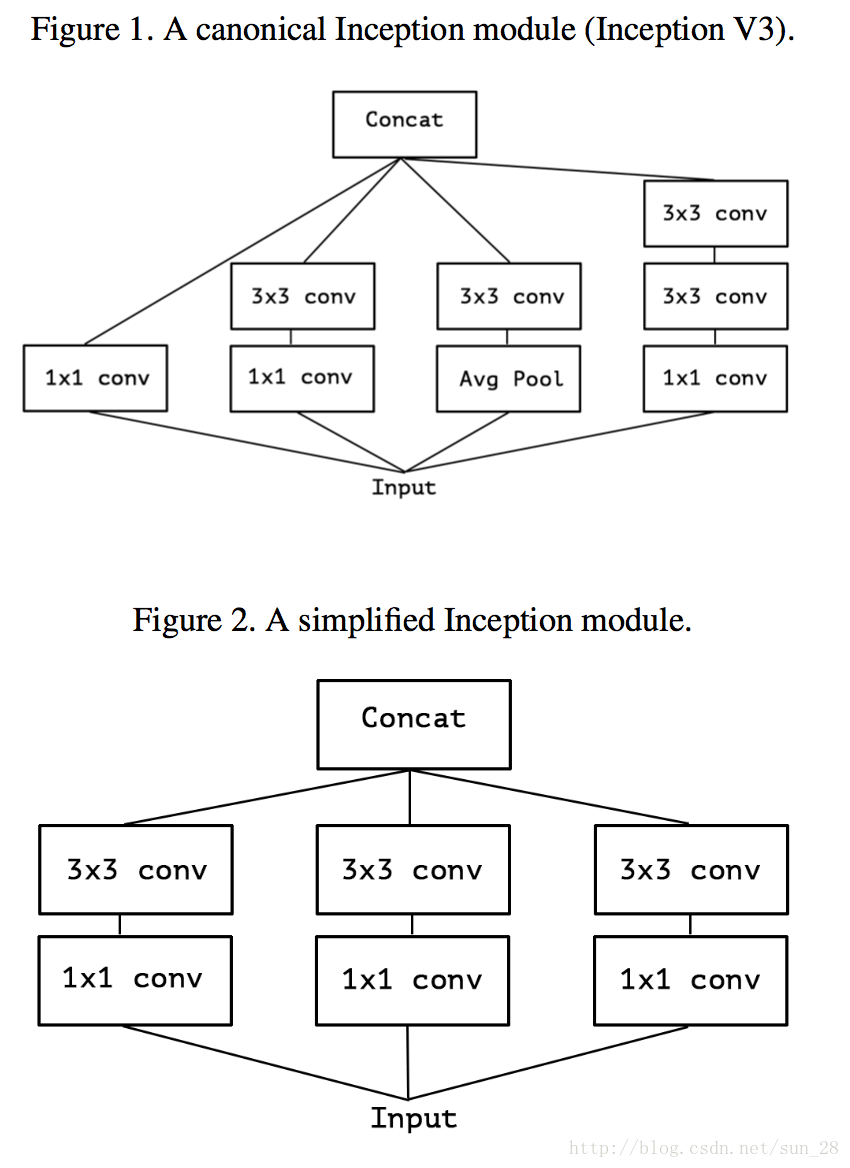
我们可以看到上图Figure 1是典型的Inception模块,它先在通道相关性上利用一些 1×11×1卷积核的等效。
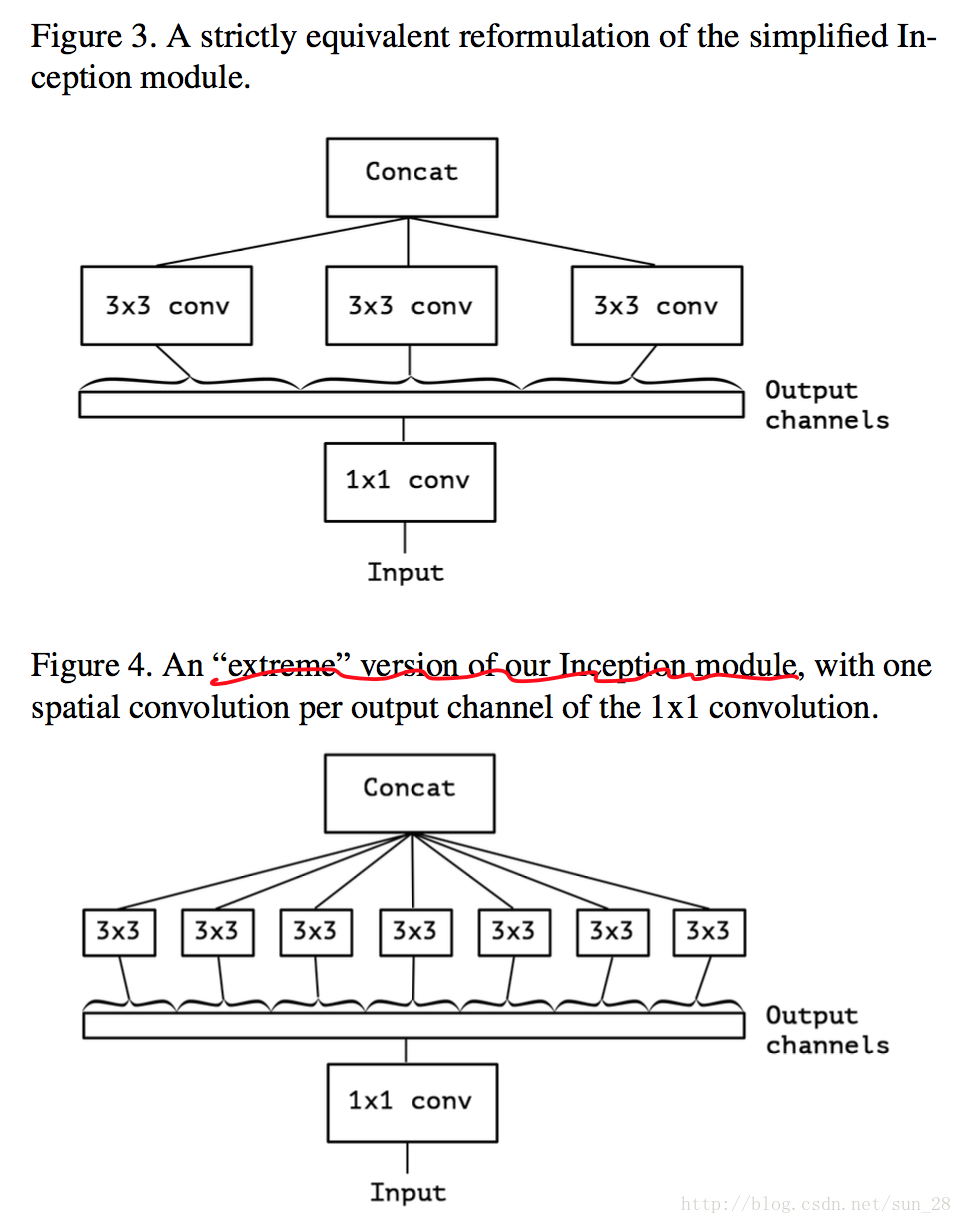
然后,考虑一下Inception简化情形,将所有分支统一到最简瓶颈模块的形式(图Figure 2)。基于Inception的简化情形,可以将所有1×11×1的通道相关映射,在分别对应每个channel的Feature Map做空间相关映射,可以等同于前面MobileNet章节所题到depthwise separable convolution,因此可分离卷积(MobileNet类网络)可以完全代替过去的常规卷积网络,Inception是这个替代过渡的重要桥梁。
可是,Xception发现这个“极限”Inception模块与可分离卷积模块有两大区别:
1、可分离卷积模块是先做3×33×3之间会有ReLU非线性激活,而可分离卷积没有。
对于区别1,前文已经介绍 Xception 认为两者是可以相互认同的,它当然不会自相矛盾,因此Xception认为区别1并不重要。所以Xception的后续论证与实验部分基本都是在讨论非线性激活、残差连接等因素非但不会影响可分离卷积模块的发挥,而且在模型参数大小相当时,可分离卷积的效果还比Inception好。以此可以论证出Inception基本进入历史,以可分离卷积为基础的Xception开始接班。
虽然Xception认为它的工作是解释可分离卷积如何从Inception发展过来的,但是我认为它的贡献只是在实验数据上验证了可分离卷积模块的有效性,这是我从MobileNet的角度看所得到的结论,我甚至还认为Xception只是补充了MobileNet论文的一些在效果方面的实验。因为Xception论文只是在文中提到了MobileNet,而并没有跟它做直接对比,毕竟二者太相近,所以我猜可能是有意规避的。下面我想从两个方面简单讨论一下Xception的理论问题,一个方面是“极限”Inception模块与可分离卷积模块区别1的重要性,另一方面是MobileNet与Xception的区别,其实也就只是“极限”Inception模块与可分离卷积的区别2。
我先讨论MobileNet与Xception的区别。这个区别是MobileNet的 3×33×3 的 point-wise 之间会有ReLU非线性激活与Batch Normalization计算。我认为Batch Normalization是可以忽略的,因为这在Inference阶段只是一个线性运算,可以优化到weights和biases当中,我也验证过这个结论。至于ReLU非线性,Xception的4.7实验表示在训练阶段中间没有任何激活函数比有激活函数要好,但我认为在inference阶段没有太大贡献。所以Xception与MobileNet相比可能在训练效果上,会有更好的收敛,因此在MobileNet优化上可以考虑去掉中间的一些冗余的ReLU激活。
而“极限”Inception模块与可分离卷积模块是否相互认同,我认为这件事情需要满足某个条件。这条件我用式(11能满足式(