1. batch norm
输入batch norm层的数据为[N, C, H, W], 该层计算得到均值为C个,方差为C个,输出数据为[N, C, H, W].
<1> 形象点说,均值的计算过程为:
 (1)
(1)
即对batch中相同索引的通道数取平均值,所以最终计算得到的均值为C个,方差的计算过程与此相同。
<2> batch norm层的作用:
a. 均值: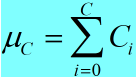 (2)
(2)
b. 方差: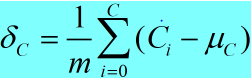 (3)
(3)
c. 归一化: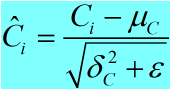 (4)
(4)

2. caffe中batch_norm_layer.cpp中的LayerSetUp函数:
1 template <typename Dtype> 2 void BatchNormLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom, 3 const vector<Blob<Dtype>*>& top) { 4 BatchNormParameter param = this->layer_param_.batch_norm_param();
//读取deploy中moving_average_fraction参数值 5 moving_average_fraction_ = param.moving_average_fraction();
//改变量在batch_norm_layer.hpp中的定义为bool use_global_stats_ 6 use_global_stats_ = this->phase_ == TEST;
//channel在batch_norm_layer.hpp中的定义为int channels_ 7 if (param.has_use_global_stats()) 8 use_global_stats_ = param.use_global_stats(); 9 if (bottom[0]->num_axes() == 1) 10 channels_ = 1; 11 else 12 channels_ = bottom[0]->shape(1); 13 eps_ = param.eps(); 14 if (this->blobs_.size() > 0) { 15 LOG(INFO) << "Skipping parameter initialization"; 16 } else {
//blobs的个数为三个,其中:
//blobs_[0]的尺寸为channels_,保存输入batch中各通道的均值;
//blobs_[1]的尺寸为channels_,保存输入batch中各通道的方差;
//blobs_[2]的尺寸为1, 保存moving_average_fraction参数;
//对上面三个blobs_初始化为0. 17 this->blobs_.resize(3); 18 vector<int> sz; 19 sz.push_back(channels_); 20 this->blobs_[0].reset(new Blob<Dtype>(sz)); 21 this->blobs_[1].reset(new Blob<Dtype>(sz)); 22 sz[0] = 1; 23 this->blobs_[2].reset(new Blob<Dtype>(sz)); 24 for (int i = 0; i < 3; ++i) { 25 caffe_set(this->blobs_[i]->count(), Dtype(0), 26 this->blobs_[i]->mutable_cpu_data()); 27 } 28 } 29 // Mask statistics from optimization by setting local learning rates 30 // for mean, variance, and the bias correction to zero. 31 for (int i = 0; i < this->blobs_.size(); ++i) { 32 if (this->layer_param_.param_size() == i) { 33 ParamSpec* fixed_param_spec = this->layer_param_.add_param(); 34 fixed_param_spec->set_lr_mult(0.f); 35 } else { 36 CHECK_EQ(this->layer_param_.param(i).lr_mult(), 0.f) 37 << "Cannot configure batch normalization statistics as layer " 38 << "parameters."; 39 } 40 } 41 }
3. caffe中batch_norm_layer.cpp中的Reshape函数:
1 void BatchNormLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom, 2 const vector<Blob<Dtype>*>& top) { 3 if (bottom[0]->num_axes() >= 1) 4 CHECK_EQ(bottom[0]->shape(1), channels_); 5 top[0]->ReshapeLike(*bottom[0]);
//batch_norm_layer.hpp对如下变量进行了定义:
//Blob<Dtype> mean_, variance_, temp_, x_norm_;
//blob<Dtype> batch_sum_multiplier_;
//blob<Dtype> sum_by_chans_;
//blob<Dtype> spatial_sum_multiplier_; 6 vector<int> sz; 7 sz.push_back(channels_);
//mean blob和variance blob的尺寸为channel 8 mean_.Reshape(sz); 9 variance_.Reshape(sz);
//temp_ blob和x_norm_ blob的尺寸、数据和输入blob相同 10 temp_.ReshapeLike(*bottom[0]); 11 x_norm_.ReshapeLike(*bottom[0]);
//sz[0]的值为N,batch_sum_multiplier_ blob的尺寸为N 12 sz[0] = bottom[0]->shape(0); 13 batch_sum_multiplier_.Reshape(sz);
//spatial_dim = N*C*H*W / C*N = H*W 14 int spatial_dim = bottom[0]->count()/(channels_*bottom[0]->shape(0)); 15 if (spatial_sum_multiplier_.num_axes() == 0 || 16 spatial_sum_multiplier_.shape(0) != spatial_dim) { 17 sz[0] = spatial_dim;
//spatial_sum_multiplier_的尺寸为H*W, 并且初始化为1 18 spatial_sum_multiplier_.Reshape(sz); 19 Dtype* multiplier_data = spatial_sum_multiplier_.mutable_cpu_data(); 20 caffe_set(spatial_sum_multiplier_.count(), Dtype(1), multiplier_data); 21 }
//numbychans = C*N 22 int numbychans = channels_*bottom[0]->shape(0); 23 if (num_by_chans_.num_axes() == 0 || 24 num_by_chans_.shape(0) != numbychans) { 25 sz[0] = numbychans;
//num_by_chans_的尺寸为C*N,并且初始化为1 26 num_by_chans_.Reshape(sz); 27 caffe_set(batch_sum_multiplier_.count(), Dtype(1), 28 batch_sum_multiplier_.mutable_cpu_data()); 29 } 30 }
形象点说上面各blob变量的尺寸:
mean_和variance_:元素个数为channel的向量
temp_和x_norm_: 和输入blob的尺寸相同,为N*C*H*W
batch_sum_multiplier_: 元素个数为N的向量
spatial_sum_multiplier_: 元素个数为H*W的矩阵,并且每个元素的值为1
num_by_chans_:元素个数为C*N的矩阵,并且每个元素的值为1
4. caffe中batch_norm_layer.cpp中的Forward_cpu函数:
1 void BatchNormLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, 2 const vector<Blob<Dtype>*>& top) { 3 const Dtype* bottom_data = bottom[0]->cpu_data(); 4 Dtype* top_data = top[0]->mutable_cpu_data();
//num = N 5 int num = bottom[0]->shape(0);
//spatial_dim = N*C*H*W/N*C = H*W 6 int spatial_dim = bottom[0]->count()/(bottom[0]->shape(0)*channels_); 7 8 if (bottom[0] != top[0]) { 9 caffe_copy(bottom[0]->count(), bottom_data, top_data); 10 } 11 12 if (use_global_stats_) { 13 // use the stored mean/variance estimates.
//在测试模式下,scale_factor=1/this->blobs_[2]->cpu_data()[0] 14 const Dtype scale_factor = this->blobs_[2]->cpu_data()[0] == 0 ? 15 0 : 1 / this->blobs_[2]->cpu_data()[0];
//mean_ blob = scale_factor * this->blobs_[0]->cpu_data()
//variance_ blob = scale_factor * this_blobs_[1]->cpu_data()
//因为blobs_变量定义在类中,所以每次调用某一batch norm层时,blobs_[0], blobs_[1], blobs_[2]都会更新 16 caffe_cpu_scale(variance_.count(), scale_factor, 17 this->blobs_[0]->cpu_data(), mean_.mutable_cpu_data()); 18 caffe_cpu_scale(variance_.count(), scale_factor, 19 this->blobs_[1]->cpu_data(), variance_.mutable_cpu_data()); 20 } else { 21 // compute mean
//在训练模式下计算一个batch的均值 22 caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim, 23 1. / (num * spatial_dim), bottom_data, 24 spatial_sum_multiplier_.cpu_data(), 0., 25 num_by_chans_.mutable_cpu_data()); 26 caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1., 27 num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0., 28 mean_.mutable_cpu_data()); 29 } 30 //由上面两步可以得到:无论是训练,还是测试模式下输入batch的均值
//对batch中的每个数据减去对应通道的均值 31 // subtract mean 32 caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1, 33 batch_sum_multiplier_.cpu_data(), mean_.cpu_data(), 0., 34 num_by_chans_.mutable_cpu_data()); 35 caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num, 36 spatial_dim, 1, -1, num_by_chans_.cpu_data(), 37 spatial_sum_multiplier_.cpu_data(), 1., top_data); 38 39 if (!use_global_stats_) {
//计算训练模式下的方差 40 // compute variance using var(X) = E((X-EX)^2) 41 caffe_sqr<Dtype>(top[0]->count(), top_data, 42 temp_.mutable_cpu_data()); // (X-EX)^2 43 caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim, 44 1. / (num * spatial_dim), temp_.cpu_data(), 45 spatial_sum_multiplier_.cpu_data(), 0., 46 num_by_chans_.mutable_cpu_data()); 47 caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1., 48 num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0., 49 variance_.mutable_cpu_data()); // E((X_EX)^2) 50 51 // compute and save moving average
//在训练阶段,由以上计算步骤可以得到:batch中每个channel的均值和方差
//blobs_[2] = 1 + blobs_[2]*moving_average_fraction_
//第一个batch时,blobs_[2]=0, 计算后的blobs_[2] = 1
//第二个batch时,blobs_[2]=1, 计算后的blobs_[2] = 1 + 1*moving_average_fraction_ = 1.9 52 this->blobs_[2]->mutable_cpu_data()[0] *= moving_average_fraction_; 53 this->blobs_[2]->mutable_cpu_data()[0] += 1;
//blobs_[0] = 1 * mean_ + moving_average_fraction_ * blobs_[0]
//其中mean_是本次batch的均值,blobs_[0]是上次batch的均值 54 caffe_cpu_axpby(mean_.count(), Dtype(1), mean_.cpu_data(), 55 moving_average_fraction_, this->blobs_[0]->mutable_cpu_data());
//m = N*C*H*W/C = N*H*W 56 int m = bottom[0]->count()/channels_;
//bias_correction_factor = m/m-1 57 Dtype bias_correction_factor = m > 1 ? Dtype(m)/(m-1) : 1;
//blobs_[1] = bias_correction_factor * variance_ + moving_average_fraction_ * blobs_[1] 58 caffe_cpu_axpby(variance_.count(), bias_correction_factor, 59 variance_.cpu_data(), moving_average_fraction_, 60 this->blobs_[1]->mutable_cpu_data()); 61 } 62 //给上一步计算得到的方差加上一个常数eps_,防止方差作为分母在归一化的时候值出现为0的情况,同时开方
63 // normalize variance 64 caffe_add_scalar(variance_.count(), eps_, variance_.mutable_cpu_data()); 65 caffe_sqrt(variance_.count(), variance_.cpu_data(), 66 variance_.mutable_cpu_data()); 67 68 // replicate variance to input size
//top_data目前保存的是输入blobs - mean的值,下面几行代码的意思是给每个元素除以对应方差 69 caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1, 70 batch_sum_multiplier_.cpu_data(), variance_.cpu_data(), 0., 71 num_by_chans_.mutable_cpu_data()); 72 caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num, 73 spatial_dim, 1, 1., num_by_chans_.cpu_data(), 74 spatial_sum_multiplier_.cpu_data(), 0., temp_.mutable_cpu_data()); 75 caffe_div(temp_.count(), top_data, temp_.cpu_data(), top_data); 76 // TODO(cdoersch): The caching is only needed because later in-place layers 77 // might clobber the data. Can we skip this if they won't? 78 caffe_copy(x_norm_.count(), top_data, 79 x_norm_.mutable_cpu_data()); 80 }
caffe_cpu_gemv的原型为:
1 caffe_cpu_gemv<float>(const CBLAS_TRANSPOSE TransA, const int M, const int N, const float alpha, const float *A, const float *x, const float beta, float *y)
实现的功能是矩阵和向量相乘:Y = alpha * A * x + beta * Y
其中,A矩阵的维度为M*N, x向量的维度为N*1, Y向量的维度为M*1.
在训练阶段,forward cpu函数执行如下步骤:
(1) 均值计算,均值计算的过程如下,分为两步:
<1> 计算batch中每个元素的每个channel通道的和;
1 caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim, 1. / (num * spatial_dim), bottom_data, spatial_sum_multiplier_.cpu_data(), 0., num_by_chans_.mutable_cpu_data());

其中:xN-1,C-1,H-1,W-1表示的含义为:N-1表示batch中的第N-1个样本,C-1表示该样本对应的第C-1个通道,H-1表示该通道中第H-1行,W-1表示该通道中第W-1列;
sumN-1,C-1表示的含义为:batch中第N-1个样本的第C-1个通道中所有元素之和。
<2> 计算batch中每个通道的均值:
1 caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1., num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0., mean_.mutable_cpu_data());

(2) 对batch中的每个数据减去其对应通道的均值;
<1> 得到均值矩阵
1 caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1, batch_sum_multiplier_.cpu_data(), mean_.cpu_data(), 0., num_by_chans_.mutable_cpu_data());

<2> 每个元素减去对应均值
1 caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num, spatial_dim, 1, -1, num_by_chans_.cpu_data(), spatial_sum_multiplier_.cpu_data(), 1., top_data);

(3) 每个通道的方差计算,计算方式和均值的计算方式相同;
(4) 输入blob除以对应方差,得到归一化后的值。