(1) softmax函数
 (1)
(1)
其中,zj 是softmax层的bottom输入, f(zj)是softmax层的top输出,C为该层的channel数。
(2) softmax_layer.cpp中的Reshape函数:
1 template <typename Dtype> 2 void SoftmaxLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom, //bottom blob为softmax层的输入,top blob为该层输出。 3 const vector<Blob<Dtype>*>& top) { 4 softmax_axis_ = //softmax_axis_为1 5 bottom[0]->CanonicalAxisIndex(this->layer_param_.softmax_param().axis()); 6 top[0]->ReshapeLike(*bottom[0]); //使用bttom[0]的shape和值去初始化top[0],后面所有的操作基于top[0]
//bottom[0]的shape为[N, C, H, W], bottom[0]->shape(softmax_axis_)的值为C 7 vector<int> mult_dims(1, bottom[0]->shape(softmax_axis_));
//Blob<Dtype> sum_multipiler、Blob<Dtype> scale_、int outer_num_、int inner_num_变量定义在softmax_layer.hpp中
//初始化sum_multiplier, mult_dims的值为C 8 sum_multiplier_.Reshape(mult_dims); 9 Dtype* multiplier_data = sum_multiplier_.mutable_cpu_data();
//设置sum_multiplier的所有元素值为1 10 caffe_set(sum_multiplier_.count(), Dtype(1), multiplier_data);
//blob的shape为[N, C, H, W], 形象点说就是blob->shape[0] = N, blob->shape[1] = C
//blob的count为N*C*H*W,形象点说就是blob->count() = N*C*H*W
//blob->count(0, 2)中的(0, 2)是左闭右开区间,返回的是N*C
//所以就有outer_num_ = bottom[0]->count(0, softmax_axis_) = N
// inner_num_ = bottom[0]->count(softmax_axis_) = H*W 11 outer_num_ = bottom[0]->count(0, softmax_axis_); 12 inner_num_ = bottom[0]->count(softmax_axis_ + 1);
//下面两行scale_dims的shape为[N, 1, H, W] 13 vector<int> scale_dims = bottom[0]->shape(); 14 scale_dims[softmax_axis_] = 1;
//scale_ blob的shape为[N, 1, H, W] 15 scale_.Reshape(scale_dims); 16 }
(3) softmax_layer.cpp中的Forward_cpu函数:
1 template <typename Dtype> 2 void SoftmaxLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, 3 const vector<Blob<Dtype>*>& top) { 4 const Dtype* bottom_data = bottom[0]->cpu_data(); 5 Dtype* top_data = top[0]->mutable_cpu_data(); 6 Dtype* scale_data = scale_.mutable_cpu_data(); 7 int channels = bottom[0]->shape(softmax_axis_); //channels = C 8 int dim = bottom[0]->count() / outer_num_; //dim = N*C*H*W / N = C*H*W 9 caffe_copy(bottom[0]->count(), bottom_data, top_data); //将bottom_data的blob数据复制给top_data的blob. 10 // We need to subtract the max to avoid numerical issues, compute the exp, 11 // and then normalize.
//求channel最大值,存放在scale_ blob中。 12 for (int i = 0; i < outer_num_; ++i) { 13 // initialize scale_data to the first plane 14 caffe_copy(inner_num_, bottom_data + i * dim, scale_data); 15 for (int j = 0; j < channels; j++) { 16 for (int k = 0; k < inner_num_; k++) { 17 scale_data[k] = std::max(scale_data[k], 18 bottom_data[i * dim + j * inner_num_ + k]); 19 } 20 } 21 // subtraction
//bottom blob数据减去对应channel的最大值 22 caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_, 23 1, -1., sum_multiplier_.cpu_data(), scale_data, 1., top_data); 24 // exponentiation
//对每个样本的每个channel数据取e. 25 caffe_exp<Dtype>(dim, top_data, top_data); 26 // sum after exp
// 下面的代码实现的是公式(1) 27 caffe_cpu_gemv<Dtype>(CblasTrans, channels, inner_num_, 1., 28 top_data, sum_multiplier_.cpu_data(), 0., scale_data); 29 // division 30 for (int j = 0; j < channels; j++) { 31 caffe_div(inner_num_, top_data, scale_data, top_data);
//指针指向下一个数据 32 top_data += inner_num_; 33 } 34 } 35 }
该函数分为下面几个步骤:
<1> 求每个样本channel的最大值;
<2> softmax的每个输入减去其所在channel的最大值,即caffe_cpu_gemm函数的功能,该函数的原型为:
1 void caffe_cpu_gemm<float>(const CBLAS_TRANSPOSE TransA, const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const float alpha, const float *A, const float *B, const float beta, float *C){ 2 int lda = (TransA == CblasNoTrans) ? K : M; 3 int ldb = (TransB == CblasNoTrans) ? N : K; 4 cblas_sgemm(CblasRowMajor, TransA, TransB, M, N, K, alpha, A, lda, B, ldb, beta, C, N); 5 }
cblas_sgemm函数作用为实现矩阵间的乘法,原型为:
//该函数实现的运算为:C = alpha*A*B + beta*C
//cblasTrans/cblasNoTrans表示对输入矩阵是否转置
//M为矩阵A,C的行数,若转置,则表示转置后的行数
//N为矩阵B、C的列数,若转置,则表示转置后的列数
//K为矩阵A的列数,或B的行数,若转置,则为转置后的列数和行数
//alpha, beta为系数
//A'cols为矩阵A的列数,与是否转置无关
//B'cols为矩阵B的列数,与是否转置无关
1 cblas_sgemm(cblasRowMajor, cblasNoTrans cblasNoTrans, M, N, K, alpha, A, A'cols, B, B'cols, beta, C, C'cols)
形象点说,caffe_cpu_gemm实现的功能为:
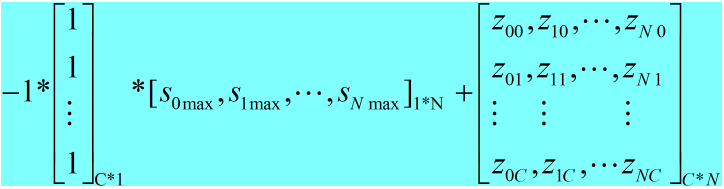
<3> 对top blob中的每个数据取e.
<4> 对每个样本的channel求和,与caffe_cpu_gemm不同的是,caffe_cpu_gemv实现的是矩阵与向量的乘法,具体的相乘过程和上面<2>中一样;
<5> 对每个样本而言,其channel的每个值除以该channel的和,也就是caffe_div完成的功能。
(4) softmax_layer.cpp中的Backward_cpu函数:
因为该函数在实际中没有用到,所以没有作过多阅读。
1 template <typename Dtype> 2 void SoftmaxLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, 3 const vector<bool>& propagate_down, 4 const vector<Blob<Dtype>*>& bottom) { 5 const Dtype* top_diff = top[0]->cpu_diff(); 6 const Dtype* top_data = top[0]->cpu_data(); 7 Dtype* bottom_diff = bottom[0]->mutable_cpu_diff(); 8 Dtype* scale_data = scale_.mutable_cpu_data(); 9 int channels = top[0]->shape(softmax_axis_); 10 int dim = top[0]->count() / outer_num_; 11 caffe_copy(top[0]->count(), top_diff, bottom_diff); 12 for (int i = 0; i < outer_num_; ++i) { 13 // compute dot(top_diff, top_data) and subtract them from the bottom diff 14 for (int k = 0; k < inner_num_; ++k) { 15 scale_data[k] = caffe_cpu_strided_dot<Dtype>(channels, 16 bottom_diff + i * dim + k, inner_num_, 17 top_data + i * dim + k, inner_num_); 18 } 19 // subtraction 20 caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_, 1, 21 -1., sum_multiplier_.cpu_data(), scale_data, 1., bottom_diff + i * dim); 22 } 23 // elementwise multiplication 24 caffe_mul(top[0]->count(), bottom_diff, top_data, bottom_diff); 25 }