layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
Local Response Normalization (LRN)层
此层是对一个输入的局部区域进行归一化,达到“侧抑制”的效果。
可去搜索AlexNet或GoogLenet,里面就用到了这个功能
网络结构显示工具

name: "CaffeNet"
layers {
name: "data"
type: DATA
top: "data"
top: "label"
data_param {
source: "/home/ubuntu/AdienceFaces/lmdb/Test_fold_is_3/gender_train_lmdb"
backend: LMDB
batch_size: 50
}
transform_param {
crop_size: 227
mean_file: "/home/ubuntu/AdienceFaces/mean_image/Test_folder_is_3/mean.binaryproto"
mirror: true
}
include: { phase: TRAIN }
}
layers {
name: "data"
type: DATA
top: "data"
top: "label"
data_param {
source: "/home/ubuntu/AdienceFaces/lmdb/Test_fold_is_3/gender_val_lmdb"
backend: LMDB
batch_size: 50
}
transform_param {
crop_size: 227
mean_file: "/home/ubuntu/AdienceFaces/mean_image/Test_folder_is_3/mean.binaryproto"
mirror: false
}
include: { phase: TEST }
}
layers {
name: "conv1"
type: CONVOLUTION
bottom: "data"
top: "conv1"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 7
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
name: "relu1"
type: RELU
bottom: "conv1"
top: "conv1"
}
layers {
name: "pool1"
type: POOLING
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layers {
name: "conv2"
type: CONVOLUTION
bottom: "norm1"
top: "conv2"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layers {
name: "relu2"
type: RELU
bottom: "conv2"
top: "conv2"
}
layers {
name: "pool2"
type: POOLING
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
name: "norm2"
type: LRN
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layers {
name: "conv3"
type: CONVOLUTION
bottom: "norm2"
top: "conv3"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers{
name: "relu3"
type: RELU
bottom: "conv3"
top: "conv3"
}
layers {
name: "pool5"
type: POOLING
bottom: "conv3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
name: "fc6"
type: INNER_PRODUCT
bottom: "pool5"
top: "fc6"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
inner_product_param {
num_output: 512
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layers {
name: "relu6"
type: RELU
bottom: "fc6"
top: "fc6"
}
layers {
name: "drop6"
type: DROPOUT
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layers {
name: "fc7"
type: INNER_PRODUCT
bottom: "fc6"
top: "fc7"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
inner_product_param {
num_output: 512
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layers {
name: "relu7"
type: RELU
bottom: "fc7"
top: "fc7"
}
layers {
name: "drop7"
type: DROPOUT
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layers {
name: "fc8"
type: INNER_PRODUCT
bottom: "fc7"
top: "fc8"
blobs_lr: 10
blobs_lr: 20
weight_decay: 1
weight_decay: 0
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
name: "accuracy"
type: ACCURACY
bottom: "fc8"
bottom: "label"
top: "accuracy"
include: { phase: TEST }
}
layers {
name: "loss"
type: SOFTMAX_LOSS
bottom: "fc8"
bottom: "label"
top: "loss"
}
层类型:LRN
参数:全部为可选,没有必须
local_size: 默认为5。如果是跨通道LRN,则表示求和的通道数;如果是在通道内LRN,则表示求和的正方形区域长度。
alpha: 默认为1,归一化公式中的参数。
beta: 默认为5,归一化公式中的参数。
norm_region: 默认为ACROSS_CHANNELS。有两个选择,ACROSS_CHANNELS表示在相邻的通道间求和归一化。WITHIN_CHANNEL表示在一个通道内部特定的区域内进行求和归一化。与前面的local_size参数对应。
归一化公式:对于每一个输入, 去除以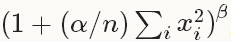 ,得到归一化后的输出
,得到归一化后的输出
,得到归一化后的输出