正则化网络的激活函数
Batch归一化会使你的参数搜索变得很容易,使神经网络对超参数选择变得更加稳定。超参数范围会更庞大,工作效率也会更好。也会让你训练出更为深层次的神经网络。下面我们具体介绍一下Batch归一化
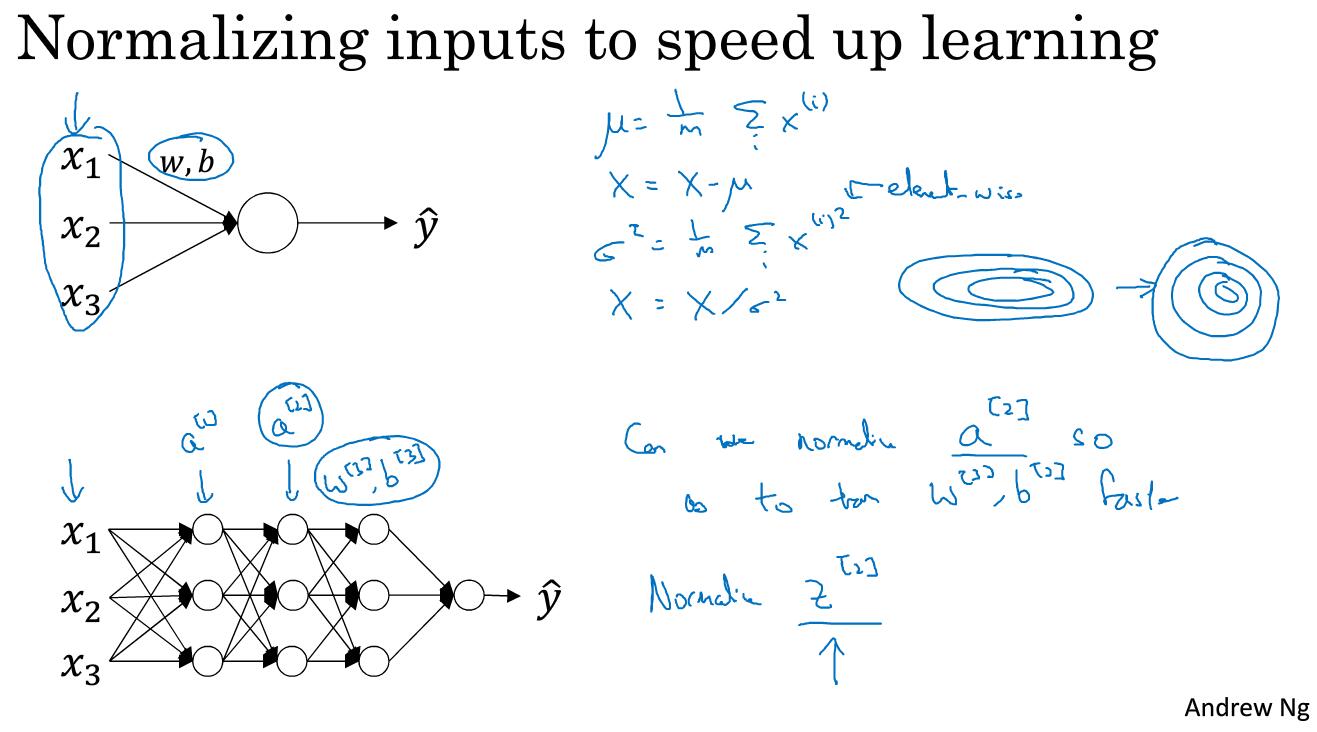
如图右侧的圈圈所示,我们之前已经学过了通过归一化手段如何将扁平的圈圈变成比较一般的圆形,但是这只是对逻辑回归而言的,对于神经网络应该怎么做呢?
我们在归一化的例子中看到了,如果对x1,x2和x3进行归一化,那么可以学到更好地w和b,同样的道理,在神经网络里,我们要想学到不错的w3和b3,那么需要对a2进行归一化处理。
那么问题是对于隐藏层,比如说这里的a2,能否实现归一化呢?
Batch归一化就可以做到这一点。实际上我们是对Z2进行的归一化而不是对a2进行的归一化。下面我们来介绍一下如何进行归一化

如图所示,假设你又一些隐藏单元,从z1一直到zm,这些都是 层的。
对z实行了正则化之后我们有如下公式:
这里 和 是模型的学习参数。我们可以使用梯度下降或者一些其他的梯度下降法。比如说momentum或者Adam来更新这两个参数,就如同神经网络的权重一样。
事实上,如果 而 那么,实际上这个式子就可以精确地转化为Z_norm的形式。
Batch归一化的好处就是他适用的归一化过程不仅是输入层,同样也适用于隐藏层。
需要注意的是我们通过调节 和 ,可以让正则化后为标准正太分布,也可以不是标准正态分布,这样就像右下图中,我们如果用sigmoid函数来拟合的话,如果是标准正态分布就只能停留在线性段,而如果不是标准正态分布就可以更好的利用非线性区域。这里,均值和方差有 和 这两个参数共同来控制。
将Batch Norm拟合进神经网络
我们之前看了Batch Norm在单一层的神经网络进行正则化,那么现在我们看看在多层是如何实现的。

如图所示,这就是Batch归一化的实践方法。
在现实中,Batch归一化通常是和mini-batch一起使用的。也就是将batch分成mini-batch然后按照上面的步骤进行计算。

需要注意的是,如上图的下半部分所示z=wa+b,但是如果我们对Z进行归一化,比如说零均值和标准方差进行归一化,那么得到的结果是无论b是多少,都要被减去。因为你在计算归一化的过程中你要计算z的均值,然后再减去均值。所以在mini-batch中增加任何常数,值都不会发生改变。因为加的任何常数都会被均值减去所抵消。因此,如果进行归一化的话,可以不写常数b。
最后我们用这个公式,转而就用 和 来控制了。我们不用b而转而用 ,说明控制参数会影响偏置条件。
最后我们来做一个总结

Batch Norm为什么奏效
Batch归一化起作用的一个原因是通过归一化输入特征值x可以获得范围内的值,起到加速学习的作用。但是还有更深层次的原因,我们一起来看一下:
batch归一化有效的另外一个原因是他可以使网络中比较深层次的网络更能经受住变化。
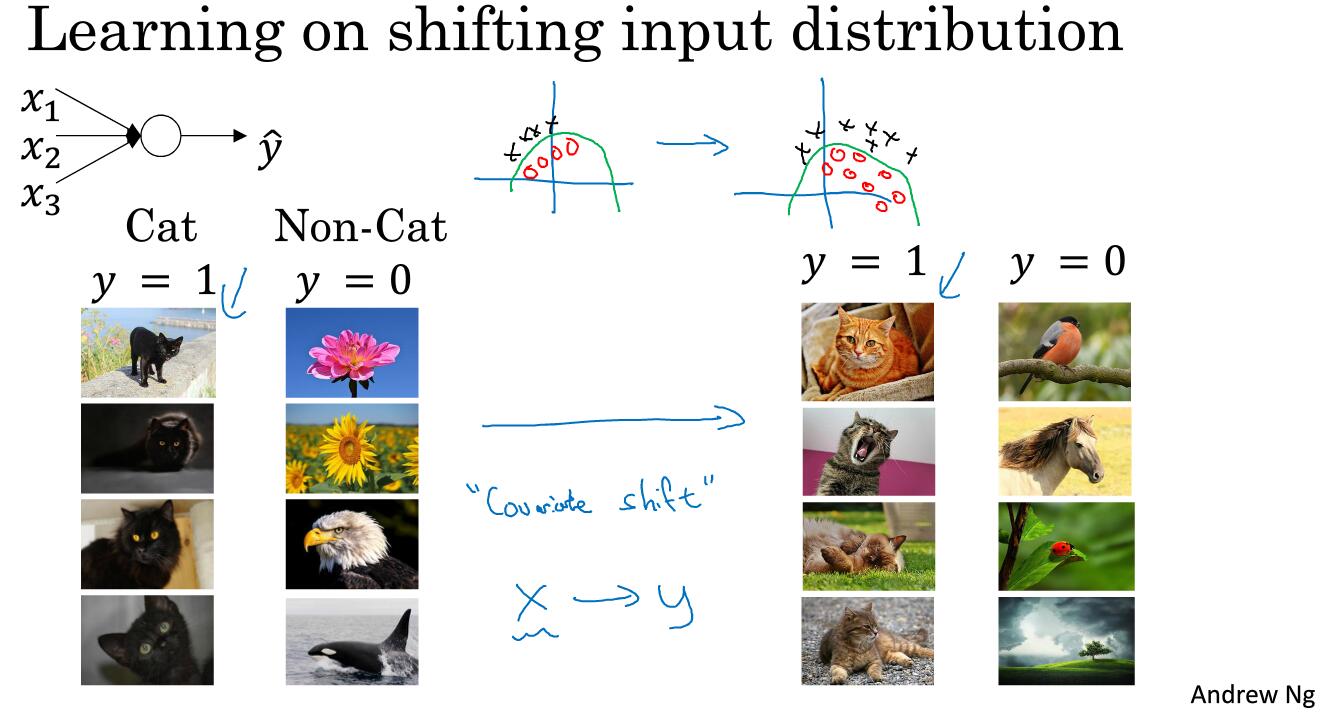
如图所示,我们执行猫的图片分类任务,那么可能左侧用黑猫训练的结果,并不能用于很好的识别其他啊颜色的猫。
使你的数据改变分布(就是上面说的用黑猫也能识别其他猫)这种事情有一个奇怪的名字叫covariate shift这个想法就是如果你学到了x到y的映射,此时如果x的分布发生了改变,那么可能需要重新训练你的算法了。那么这个问题如何应用到神经网络中?
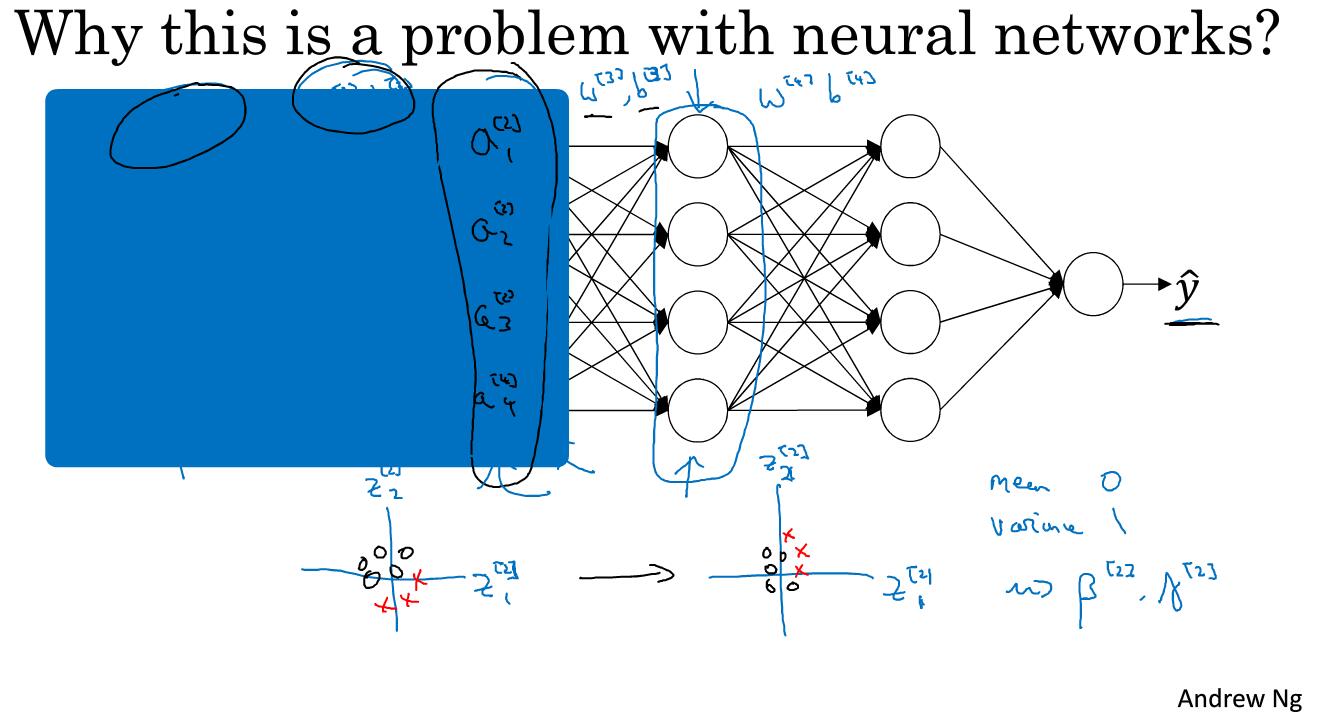
如图所示的一个神经网络,我们遮住前面的部分,只从第三层开始。如果我们只看第三层的话,我们希望学出w和b来很好的拟合将输入a映射到y。然而事实上是前面还有两层w和b,如果前面两层的w和b发生了变化,那么输入的a也会发生变化,这就会影响到第三层的w和b,于是我们可以说,a是在不断变化过程中,是一个covariate shift问题。
batch归一化做的,就是减少这些隐藏层值分布变化数量。如上图的下部分所示,我们绘制了z1和z2的平面图。batch归一化说的是z1和z2的值可以改变,而这两个数的确会变化,只要神经网络一更新参数,这两个数就会发生变化。而batch归一化可以保证,无论z1和z2怎么变化,他们的均值和方差保持不变。
batch归一化做的是限制前层的更新,会影响数值的分布情况。它的作用是减弱前层参数的作用与后层参数作用之间的联系,他使得网络中每一层都可以自己学习,稍稍独立于其它层,有助于更好的进行学习。因为他们被同一个均值和方差限制,导致后面的层学起来会更容易一些。
batch归一化还有一个作用,他有一点正则化的效果

在mini-batch上计算均值和方差而不是在整个数据集上计算均值和方差的话容易会引起一点噪音。所以缩放从 到 也有一定的噪音。Dropout有噪音的原因是因为它随机加了一些0.batch的话,计算的均值和偏差也都是有噪音的。
所以batch有轻微的正则化效果(regularization)效果。因为给隐藏层增加了噪音,这迫使后部单元不过分依赖于任何一个隐藏单元。当然,如果你用较大的mini-batch,比如说512的话,减少了噪音,也就减少了正则化效果。
测试时的Batch Norm
Batch归一化将你的数据以mini-batch的形式进行处理。但在测试时你可能需要对每一个样本逐一进行处理。我们看一下如何通过调整网络来做到这一点。

如图所示,左侧是我们在训练集中的每一个mini-batch所用的公式,然而在测试集的时候,我们不能这么做。
如图右侧所示,在测试集中你需要用一个指数加权平均来估计。这个平均函数涵盖了所有的mini-batch。假设对于L层,我们有mini-batch X1,X2等等,在L层训练X1的时候,你就得到了 ,其他训练也是这样的。正如我们之前计算温度得到的指数加权平均 等,你会得到这些稳定向量的最新平均值。用同样的方法,我们也可以得到 和 的每一层的值。
总结一下, 和 是在整个mini-batch上计算出来的,但是在测试时,你可能需要逐一处理样本,方法是根据你的训练集估计 和 。方法有很多种,理论上你可以在网络上运行整个训练集来得到 和 ,但实际操作中我们通常用到指数加权平均来追踪训练过程中看到的 和 ,也会用指数加权平均来估计 和 。然后用测试集的 和 来进行你所需单元的z的值得调整。