按理说每一层应该都要求一层梯度,其中包括对权值,对输入数据,对偏置分别求取梯度。但是在softmax with loss layer这一层求取梯度的一些过程被省去了,首先这一次只是一个激活函数层,没有权值和偏置参数,然后我们只需要对输入数据求取梯度,softmax with loss layer的输入数据其实表示的是原始输入数据相对于各个标签的打分,而对于代价函数对这个输入的梯度已经有专门的迭代算法来求解。
一.softmax简介
softmax主要应用的地方是logistic模型对于多分类模型的推广,将多个神经元的输出问题映射到(0,1)区间中,它的公式为
当某个类的预测值很大时该类的分量流趋向于1,其他类的分量值就变得很小。

二.前向传播
在caffe中的softmax layer中它的前向传播过程如下所示
输入的向量经过指数化和归一化后进行输出,这就是softmax layer的前向计算过程,主要代码为

template <typename Dtype>
void SoftmaxLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>>& bottom,const vector<Blob<Dtype>>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
Dtype* scale_data = scale_.mutable_cpu_data();
int channels = bottom[0]->shape(softmax_axis_); //channnel的深度
int dim = bottom[0]->count() / outer_num_; //总的类别的数目,也就是长高channnel
caffe_copy(bottom[0]->count(), bottom_data, top_data); //将底层的数据拷贝到顶层缓冲中
// 我们需要先抽取最大值以防止在指数运算时超过了计算机能表达的最大值
for (int i = 0; i < outer_num_; ++i) {
caffe_copy(inner_num_, bottom_data + i * dim, scale_data);
for (int j = 0; j < channels; j++) {
for (int k = 0; k < inner_num_; k++) {
scale_data[k] = std::max(scale_data[k],
bottom_data[i * dim + j * inner_num_ + k]);//找出了指定num的channnel通道的最大值
}
}
// subtraction
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_,//将输出缓存区的值减去均值
1, -1., sum_multiplier_.cpu_data(), scale_data, 1., top_data);
// exponentiation 求指数
caffe_exp<Dtype>(dim, top_data, top_data);
// sum after exp 求1+exp
caffe_cpu_gemv<Dtype>(CblasTrans, channels, inner_num_, 1.,
top_data, sum_multiplier_.cpu_data(), 0., scale_data);
// division 求softmax的值 即exp/(1+exp)
for (int j = 0; j < channels; j++) {
caffe_div(inner_num_, top_data, scale_data, top_data); //最后的结果存储在top中的
top_data += inner_num_;
}}
}
上述函数的作用就是计算softmax函数的结果并且保存在起初的位置,至于为什么要减去均值视为了放置经过指数化后的值过大无法在计算机中表示而出现上溢的问题,至于下溢的问题对结果无影响所有就不予考虑了。
三.反向梯度计算

if (propagate_down[0]) {
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
const Dtype* prob_data = prob_.cpu_data(); //(softmax 的输出 即下面公式的 aj)
caffe_copy(prob_.count(), prob_data, bottom_diff);
const Dtype* label = bottom[1]->cpu_data();
int dim = prob_.count() / outer_num_;
int count = 0;
for (int i = 0; i < outer_num_; ++i) {
for (int j = 0; j < inner_num_; ++j) {
const int label_value = static_cast<int>(label[i * inner_num_ + j]);
if (has_ignore_label_ && label_value == ignore_label_) {
for (int c = 0; c < bottom[0]->shape(softmax_axis_); ++c) {
bottom_diff[i * dim + c * inner_num_ + j] = 0;
}
} else {
bottom_diff[i * dim + label_value * inner_num_ + j] -= 1;
++count;
}
}
}
// Scale gradient //根据 weight_loss 的权重 来 缩放 梯度
Dtype loss_weight = top[0]->cpu_diff()[0] /
get_normalizer(normalization_, count);
caffe_scal(prob_.count(), loss_weight, bottom_diff);
}
在人工神经网络(ANN)中,Softmax通常被用作输出层的激活函数。这不仅是因为它的效果好,而且因为它使得ANN的输出值更易于理解。同时,softmax配合log似然代价函数,其训练效果也要比采用二次代价函数的方式好。
1. softmax函数及其求导
softmax的函数公式如下:
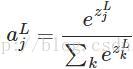
其中,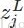
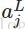
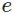
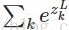
softmax函数最明显的特点在于:它把每个神经元的输入占当前层所有神经元输入之和的比值,当作该神经元的输出。这使得输出更容易被解释:神经元的输出值越大,则该神经元对应的类别是真实类别的可能性更高。
另外,softmax不仅把神经元输出构造成概率分布,而且还起到了归一化的作用,适用于很多需要进行归一化处理的分类问题。
由于softmax在ANN算法中的求导结果比较特别,分为两种情况。希望能帮助到正在学习此类算法的朋友们。求导过程如下所示:
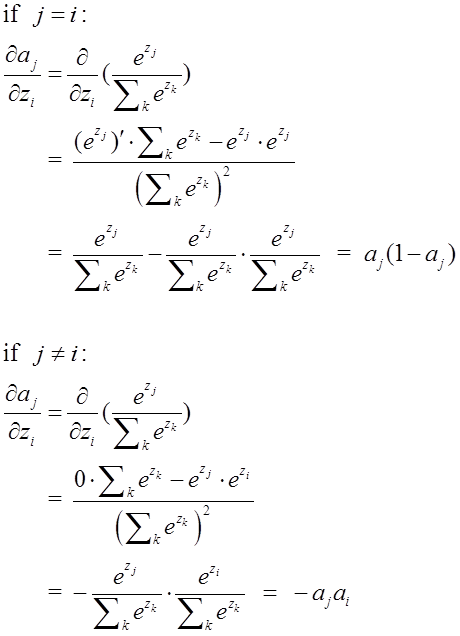
2. softmax配合log似然代价函数训练ANN
在上一篇博文“交叉熵代价函数”中讲到,二次代价函数在训练ANN时可能会导致训练速度变慢的问题。那就是,初始的输出值离真实值越远,训练速度就越慢。这个问题可以通过采用交叉熵代价函数来解决。其实,这个问题也可以采用另外一种方法解决,那就是采用softmax激活函数,并采用log似然代价函数(log-likelihood cost function)来解决。
log似然代价函数的公式为:
其中,
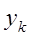
我们来简单理解一下这个代价函数的含义。在ANN中输入一个样本,那么只有一个神经元对应了该样本的正确类别;若这个神经元输出的概率值越高,则按照以上的代价函数公式,其产生的代价就越小;反之,则产生的代价就越高。
为了检验softmax和这个代价函数也可以解决上述所说的训练速度变慢问题,接下来的重点就是推导ANN的权重w和偏置b的梯度公式。以偏置b为例:

同理可得:
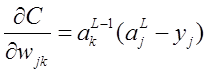
从上述梯度公式可知,softmax函数配合log似然代价函数可以很好地训练ANN,不存在学习速度变慢的问题。