1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
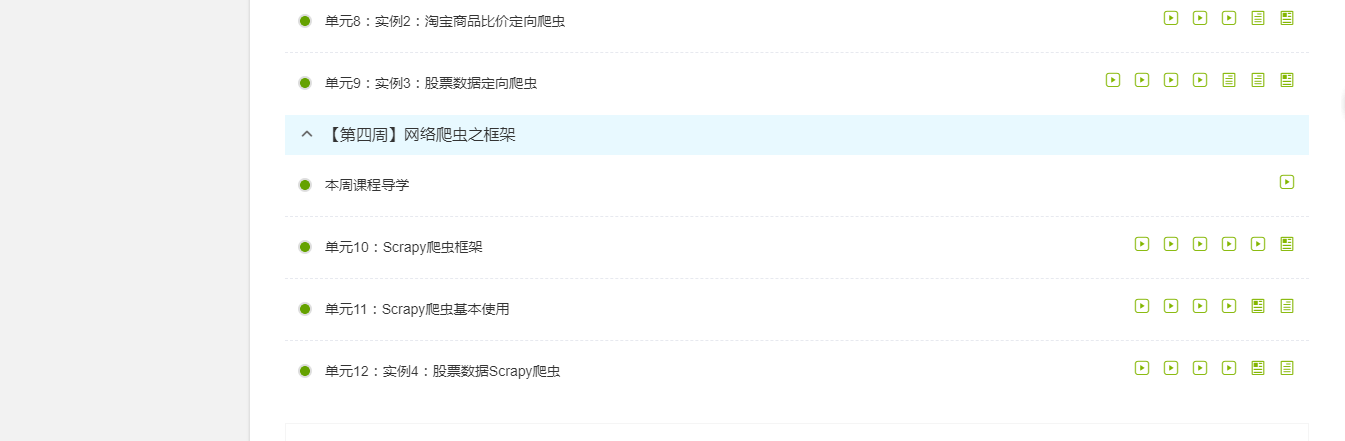
3.学习完成第0周至第4周的课程内容,并完成各周作业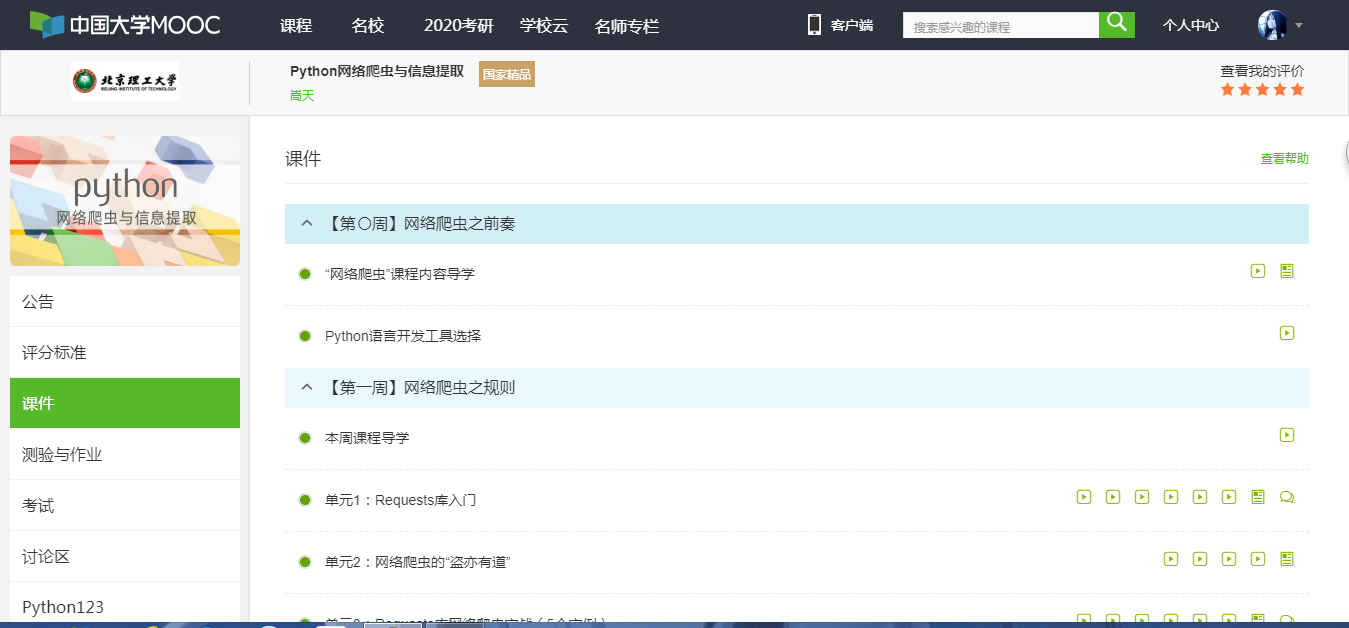

4.提供图片或网站显示的学习进度,证明学习的过程。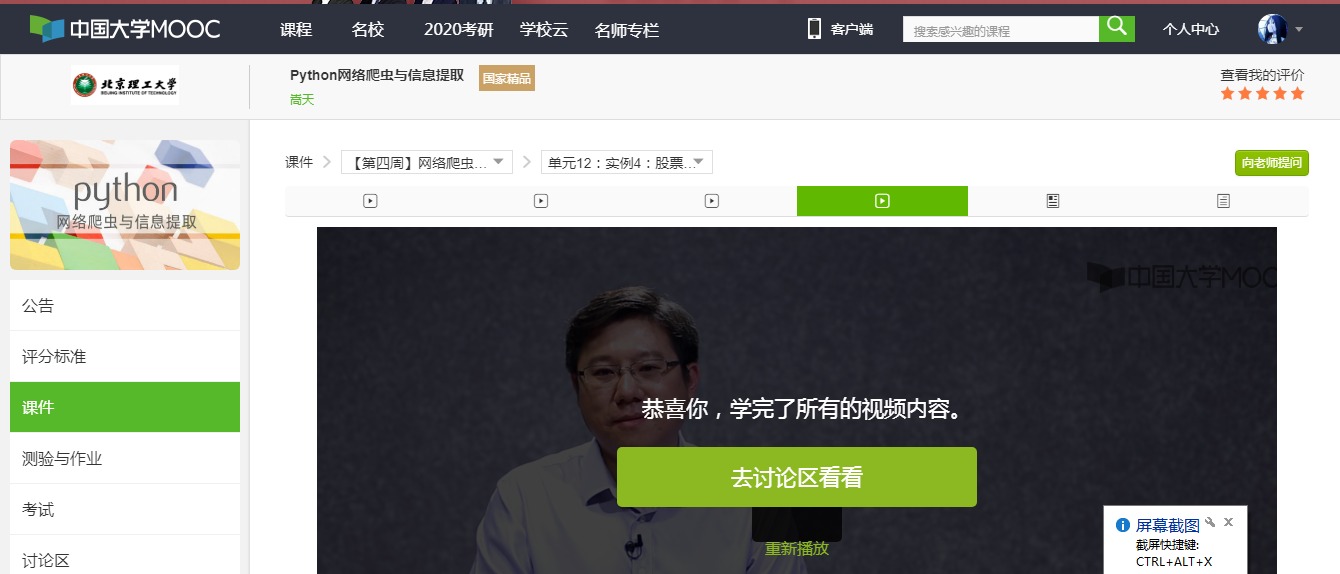
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
学习了嵩天老师的《Python网络爬虫与信息提取》的课程中0-4周的任务,让我受益匪浅。首先从整个教学视频的角度来说简短而精致,不会给人带来视觉上的疲劳和大脑的使用过度。整体上采取了理论与实例相结合的教育模式,所得到的效果也是极佳。接下来,我就对我学习的情况进行分析总结。
第0周的网络爬虫之前奏中,嵩天老师给我们讲诉了好几种Python语言开发工具的选择,而我选择了Python自带的IDLE。
第1周的网络爬虫之规则中,嵩天老师讲诉了Requests库的安装,以及Requests库的两个重要对象Response和Request.然后详细讲了Requests库的7个主要方法。然后通过5个Requests库网络爬取实战:实例1京东商品页面的爬取、实例2亚马逊商品页面的爬取、实例3百度/360搜索关键字提交、实例4网络图片的爬取和存储、实例5IP地址归属地的自动查询,对Requests库的方法进行了实践。并且还留下了源代码供学生课下进行操作,真的是在十分严谨的教学任务中,透露出一股对学生们的贴心。
第2周的网络爬虫之提取中,嵩天老师详细给我们介绍了Beautiful Soup库。我在自己电脑的cmd中用pip install beautifulsoup4 命令安装了Beautiful Soup库。通过学习我明白了Beautiful Soup库是解析、遍历、维护“标签树”的功能库,而标签树即HTML。在这个周的视频中嵩天老师给我们讲诉了一个较为复杂的实例-中国大学排名定向爬虫,通过这个实例让我们对Beautiful Soup库有了更加深刻的了解和认识,也从中知道了爬虫也有必须遵守的协议Robots协议。
第3周的网络爬虫之实战,在这周中嵩天老师详细向我们介绍了正则表达式,正则表达式是用来简洁表达一组字符串的表达式。使用正则表达式的优势就是简洁。可能正是正则表达式的这种化复为简,让我学起来倍感困难,很多时候都搞不清楚这个表达式所表示的意思或者不太正确的认识表达式。总而言之这是个难点,需要我自己付出时间和实践才能掌握的东西,所以需要自己的努力。嵩天老师在这里讲了两个实例--淘宝商品比价定向爬虫和股票数据定向爬虫,来帮助我们了解正则表达式。
第4周的网络爬虫之框架,在这里老师向我们介绍了和Requests库相对应的Scrapy爬虫框架。Scrapy不是一个函数功能库而是一个爬虫框架,是实现爬虫功能的一个软件结构和功能结构的集合,是一个半成品,能帮助用户实现专业网络爬虫。Requests库是页面级爬虫,Scrapy是网站级爬虫。在这里嵩天老师用实例股票数据scrapy爬虫对Scrapy爬虫框架有了一个详细的介绍,其中同样运用到正则表达式,对数据进行优化,同时也是对上一节的正则表达式进行简单的复习。
通过这段时间对嵩天老师的《Python网络爬虫与信息提取》课程的学习,让我学到了很多的知识,让我第一次认识到什么是爬虫、怎么爬虫、爬虫有什么好处等等。同时也让我认识到了python这门语言的魅力,可以用它来实现很多东西。同时也让我清楚了自己知识面的单薄,所以接下来的日子,要更加努力学习,丰富我的知识面,提高我的专业能力。