
















































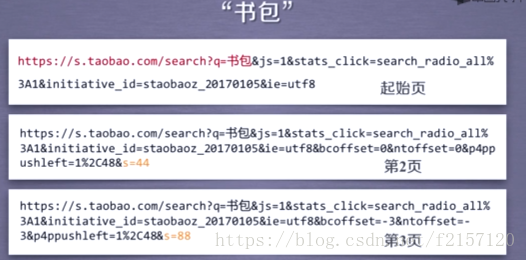
每页44个商品
通过对例子的分析,我们得到了搜索接口和翻页的URL对应属性








/////
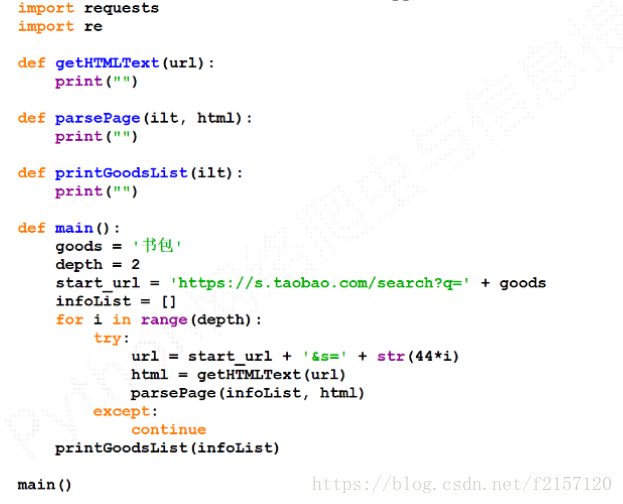
import requests import re def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parsePage(ilt, html): try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price, title]) except: print("") def printGoodsList(ilt): tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号", "价格", "商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count, g[0], g[1])) def main(): goods = 'Python' depth = 3 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44 * i) html = getHTMLText(url) parsePage(infoList, html) except: continue printGoodsList(infoList) main()
C:\Users\Amber\AppData\Local\Programs\Python\Python36\python.exe C:/Users/Amber/PycharmProjects/untitled4/test.py
序号 价格 商品名称
1 8888.00 学Python编程从入门到实战直播视频培训课程
2 10888.00 潭州教育Python编程在线直播培训视频课程从入门到实践小白学习
3 69.80 现货 Python编程从入门到实践python3.5绝技核心编程基础教程网络爬虫入门书籍python视频编程从入门到精通程序设计教材
4 2000.00 方头Fancy Python真蟒蛇皮牛皮底鞋年轻领导礼物意大利固特异手工
5 39.00 天天特价Github程序员Ubuntu极客JAVA码农Python夜光衣男短袖t恤
6 658.00 吹水推荐正品现货 拉思珀蒂瓦La sportiva Python大蟒蛇 攀岩鞋
7 1590.00 GEDEBE皮革女款金属链条单肩包水钻拼接时尚斜挎包CLIKY PYTHON
8 320.00 Ronin "Python"长袖巴西柔术防磨衣 健身MMA训练长袖紧身衣
9 68.00 夏季新款程序员t恤python编程极客男短袖圆领纯棉打底衫半袖体恤
10 59.00 攀威人生苦短我用PYTHON 短袖T恤程序员猿码猴极客geek语言代码农
11 341.60 Lorna Jane|Python 中强度运动内衣健身文胸 带胸垫 0917 44
12 48.00 程序员码农猴PYTHON人生苦短帽子棒球帽gekiux 青少年学生个性潮
13 2058.00 ASH女装2018春季新款PYTHON系列时尚桑蚕丝流苏系带休闲长裤
14 24.88 Github程序员Ubuntu章鱼猫极客JAVA码农Python geek理工男短袖t恤
15 49.00 红韩PYTHON 短袖T恤程序员极客geek编程语言代码农理工IT男棉夏装
16 920.00 La Sportiva Python攀岩鞋魔术贴户外登山抱石男女款攀岩鞋
17 49.00 理工男短袖T恤黑色潮Github Linux程序员猿IT狂人JAVA编程Python
18 9.98 R统计绘图/Python语言指导/英文project作业学习指导/大学教师
19 59.90 范品社 Python 复仇者联盟美国队长蜘蛛侠 工程师文化极客短袖T恤
20 39.00 人生苦短我用PYTHON 程序员IT男源代码极客geek语言夏季短袖T恤男
21 390.40 重塑 Lorna Jane 中强度美背蛇纹印花运动内衣女健身文胸女Python
22 398.00 巴西专柜Melissa梅丽莎Cosmic Python Baja East沙滩拖鞋女
23 49.00 攀威Github程序员Ubuntu极客JAVA码农Python衣服geek IT男短袖t恤
24 49.00 人生苦短我用python短袖T恤男士程序员猿衣服编程IT码农半截袖衫
25 39.00 富苗花程序员码农 人生苦短 我用python 极客geek 纯棉短袖T恤男
26 1550.00 连体泳衣 速比涛SPEEDO 女性泳装 强大PYTHON 竞争系列 蟒蛇蓝红
27 69.00 374路DTS极客geek理工程序员it周边python编程语言短袖宽松T恤棉
28 65.00 美国进口TEC 钥匙扣系统 挂扣 快挂 挂夹 UFO python p-7 开口环
29 59.00 人生苦短我用PYTHON 程序员源代码极客geek语言短袖T恤上衣衣服
30 88.00 人生苦短我用PYTHON程序员猿码猴极客geek语言代码卫衣外套男衣服
31 59.00 络绎机算机程序员python编程短裤夏五分裤纯棉运动休闲裤韩版宽松
32 350.00 美国代购 python quick wraps 手套 拳击 举铁都可以用
33 55.00 短袖T恤男士纯棉宽松上衣人生苦短 我用python印花logo程序员衣服
34 24.88 Github程序员T恤 geek Ubuntu极客JAVA码农Python夜光衣男短袖t恤
35 40.00 全新包邮量化交易之路 用Python做股票量化分析
36 23.75 · 包邮 跟老齐学Python:从入门到精通 电子工业
37 79.00 理工男圆领卫衣黑色潮Github Linux程序员猿IT狂人JAVA编程Python
38 79.00 极客式人生苦短我用python印花程序员t恤长袖男圆领短袖geek纯棉T
39 12.00 Python Testing with pytest Simple
40 12.00 Rapid GUI Programming with Python and Qt
41 43.00 蟒蛇 python 程序员 计算机语言 极客 IT GEEK男女短袖T恤
42 78.00 人生苦短我用Python程序员恶搞系列极客男女秋冬加绒连帽卫衣外套
43 19.80 满三件包邮 OpenCV算法精解 基于Python与C++
44 49.00 夏季人生苦短我用python程序员印花修身t恤男圆领短袖geek棉质潮
45 58.00 人生苦短我用python印花logo程序员短袖T恤男士纯棉宽松上衣衣服
46 45.00 程序员python编程geek极客工程师主题T恤 男士纯棉短袖上衣体恤衫
47 38.00 程序猿码农周边人生苦短我用Python环保购物袋单肩斜挎帆布包女包
48 1846.00 GEDEBE女款单肩斜挎包BRIGITTE PYTHON
49 1722.12 Nike Kobe 8 System "Python" - 555035 300
50 88.00 人生苦短我用python程序员猿连帽衫卫衣服男女码农编程IT加绒外套
51 55.00 PYTHON 短袖T恤程序员极客geek编程语言代码农理工IT男纯棉夏装
52 58.00 Github程序员猿Ubuntu极客JAVA码农Python IT男卫衣外套GEEK
53 63.55 多省包邮 Python编程(第四版) 上下册 两本 中国电力
54 1360.00 GEDEBE女款手提包蛇皮花纹水钻小包包女士晚宴手挽包FLAT PYTHON
55 25.00 · 包邮 跟老齐学Python:从入门到精通 电子工业
56 18.05 满3件包邮Python编程快速上手——让繁琐工作自动化人
57 55.00 Github程序员Ubuntu极客JAVA码农Python衣服geek IT男短袖t恤
58 98.00 Github程序员Ubuntu极客JAVA码农Python衣服geek圆领卫衣外套衣服
59 53.00 Github程序员猿Ubuntu极客JAVA码农Python IT男短袖t恤衫GEEK 夏
60 3.00 python零基础从入门到精通视频教程 爬虫大数据人工智能编程
61 339.00 KITA [Paperplanes] PP1353 Python 时尚界 轻便鞋 休闲 鞋子
62 1142.00 Petite Mendigote LOUISN-PYTHON-GREY 女装休闲时尚连体服
63 752.00 Sperry Top-Sider 女 SEASIDE PYTHON 女鞋
64 1244.00 Petite Mendigote CELESTINE-PYTHON-CHICOREE 女 女装休闲连衣裙
65 893.22 Nike Air Python Lux SP - 632631 601
66 725.00 Bolle Python 11333 男士蓝色镜片 黑色镜框矩形全框偏光太阳镜
67 79.00 卡荷薄卫衣计算机程序员python编程语言技术男士学生情侣装外套潮
68 79.00 卡荷程序员python编程语言男女学生青少年束脚收口小脚裤运动长裤
69 59.00 人生苦短我用python程序员印花修身t恤男圆领修身长袖geek棉质潮
70 88.00 人生苦短我用 PYTHON 程序员源代码 极客geek 语言卫衣 学生衣服
71 78.00 人生苦短我用python程序员印花卫衣外套衣服圆领卫衣
72 88.00 人生苦短PYTHON当歌 程序员源代码极客geek语言卫衣
73 78.00 Github程序员猿Ubuntu极客JAVA码农Python IT男卫衣外套GEEK
74 13.50 纯英文绘本 贪婪的蟒蛇The Greedy python 幼儿童英语图画故事书
75 62.50 PYTHON3网络爬虫开发实战 崔庆才 著作 程序设计(新)专业科技 新华书店正版图书籍 人民邮电出版社
76 8888.00 潭州教育Python编程从入门到实践人工智能课程在线直播视频学习
77 144.30 Python编程入门 全3册 Python编程从入门到实践 零基础学习Python Python基础教程程序设计教材计算机程序设计 Python语言入门
78 24.75 零基础入门学习Python 小甲鱼计算机/网络 pyhton3.0从入门到精通python语言程序设计基础核心教程 python编程 从入门到实践书籍
79 53.40 【官方正版】Python编程从入门到实践 python3.5核心编程基础教程快速上手 3.0零基础笨办法学网络爬虫程序设计算机教材书籍
80 59.40 正版现货 Python基础教程第3版 Python编程从入门到实践 head first python学习手册 零基础入门学习Python基础教程3第三版书籍
81 99.00 【2本套】Python编程-从入门到实践+Python网络爬虫 核心编程语言书籍 计算机程序设计从零到精通 游戏开发应用学习手册
82 62.50 新书现货Python3网络爬虫开发实战从入门到精通基于Python3.6网络爬虫技术Scrapy数据分析处理手册Python3数据抓取技术指南书籍
83 28.80 正版现货 python语言程序设计基础第二版嵩天python编程入门Python编程从入门到实践python基础教程第2版python书籍高等教育出版社
84 29.00 Python3 Python视频教程自动化运维 爬虫 大数据分析 全栈工程师
85 59.40 现货【赠400元电子书】Python基础教程(第3版) python3.5核心编程从入门到实践网络爬虫 计算机视频从入门到精通程序设计书籍
86 280.00 传智播客Python程序设计从入门到实践套装8本 零基础机器学习人工智能程序设计基础教程+核心编程黑马程序员 赠全套学习视频课程
87 80.00 python人工智能深度学习机器学习视频教程Tensorflow/Caffe
88 57.50 PYTHON3网络爬虫开发实战 崔庆才 著作 程序设计(新)专业科技 新华书店正版图书籍 人民邮电出版社
89 59.63 利用Python进行数据分析(美)麦金尼著 python基础教程/python数据分析/计算机网络程序/程序设计编程 机械工业出版社
90 29.50 【赠400元电子书】Python 3.5从零开始学 python基础教程3.0核心编程从入门到实践网络爬虫 计算机视频从入门到精通程序设计书籍
91 66.90 现货正版Python3网络爬虫开发实战 崔庆才Scrapy数据分析处理手册数据抓取指南基于python3.6的爬虫图书籍人民邮电出版社图灵原创
92 53.40 正版包邮 Python编程从入门到实践 python3.0绝技核心编程基础教程 网络爬虫入门书籍 python 视频编程从入门到精通 程序设计教材
93 599.90 Python深度学习机器学习神经网络量化投资caffe tensorflow框架学
94 71.40 python学习手册 第四版 学习python运维实践/计算机网络/程序设计/计算机教材 从入门到精通Python程序设计教程新华书店上海书城
95 61.50 【现货速发】Python编程从入门到实践python3.0*技核心基础教程网络爬虫书籍计算机python视频编程从入门到精通程序设计教材
96 67.00 正版包邮 Python基础教程第3版 Python编程从入门到实践 head first python学习手册 零基础入门学习Python教程第三版计算机教材书
97 4200.00 知数堂Python开发在线培训课程 知名公司高级Python工程师亲授
98 57.80 Python 3网络爬虫开发实战 Scrapy数据分析处理手册 python3爬虫python网络爬虫实战 python基础教程编程入门书 图灵程序设计丛书
99 63.00 正版现货 Python3 网络爬虫开发实战 Scrapy数据分析处理方法 gerapy爬虫管理python网络爬虫实战编程基础教程入门书基于python3.6
100 79.20 每满200减100【当当网 正版书籍】利用Python进行数据分析
101 93.80 【现货】机器学习实战+Python机器学习基础教程套装2册python基础教程从入门到实践机器学习实战机器高效实战书籍python人工智
102 6800.00 Python教程-马哥教育2018年全新人工智能+Python全栈工程师
103 135.80 2本套 Python编程入门到实践 核心编程 第3版 核心编程基础教程书籍 python3.5计算机程序设计教材 网络爬虫视频教程从入门到精通
104 35.80 【扫码看视频】6月新书现货 笨办法学python3 基础编程从入门到实践 核心编程语言书籍 计算机程序设计从零到入门到实践 自学教材
105 62.50 包邮 Python 3网络爬虫开发实战 Scrapy数据分析处理手册 python3爬虫python网络爬虫实战 python基础教程编程入门书基于python3.6
106 59.90 【正版包邮】利用Python进行数据分析(美)麦金尼著 python基础教程/python数据分析/计算机网络程序/程序设计编程 机械工业出版
107 100.00 C语言python爬虫留学生.net编程C++算法辅导代写 软件项目 程序咨
108 79.50 人邮新书 Python数据科学手册 数据分析计算书籍 python3机器学习 NumPy数据存储 Matplotlib数据可视化实战
109 74.20 正版 Python核心编程第3版 python3爬虫数据分析 python入门实战书籍 python编程入门基础学习手册书籍 实用的代码案例习题
110 148.80 套装2册 流畅的Python+Python高性能编程 python编程教程书籍 python代码大全 python入门到精通 Python语言 Python与有限元
111 95.80 【现货速发】流畅的Python Python基础教程 Python编程从入门到精通 Python核心编程开发程序设计 语言学习书籍 python代码大全
112 32.83 OpenCV 3计算机视觉 Python语言实现(原书第2版)计算机教材教程书籍 人脸检测与识别 图像检索 人工神经网络识别 机械工业出版社
113 62.00 正版包邮Python编程 从入门到实践 图灵程序设计丛书 python3.5*技核心编程基础教程网络爬虫入门书籍 编程从入门到精通教材现货
114 138.30 教孩子学编程+趣学Python+父与子的编程之旅 全3册 教孩子编程的图书 python编程入门教程 Python语言基础入门书籍少儿 趣味编程
115 19.99 python人工智能AI深度学习机器学习视频教程Tensorflow/Caffe
116 44.80 父与子的编程之旅 与小卡特一起学Python 教孩子编程的图书 python编程入门教程 Python语言基础入门书 Python核心编程 人民邮电
117 69.80 正版现货 Python编程从入门到实践 python基础教程 Python核心编程 Python程序设计 python零基础从入门到精通 Python视频教程书籍
118 99.00 python人工智能机器学习视频自然语言处理图像处理爬虫视频教程
119 59.60 Python自然语言处理 python编程语言程序设计书籍 计算机科学 python语言处理入门指南 Python指南图书 计算机教材书
120 59.60 正版包邮 利用Python进行数据分析 python数据分析 python基础教程 企业数据分析 Python语言和库 程序设计编程 机械工业出版社
121 46.80 现货 Python编程从入门到实践 python3.5绝技核心编程基础教程网络爬虫入门书籍 python视频编程从入门到精通程序设计教材 人邮
122 68.00 python基础教程 Python核心编程 第二版 精通核心编程语言书籍 计算机程序设计从零到入门到实践手册 笨办法学习教材 python2/3书
123 69.50 PYTHON核心编程(第3版) 第三版 python开发大全 python入门到精通书籍 python编程入门基础学习手册实用代码案例习题
124 62.50 PYTHON3网络爬虫开发实战 崔庆才 著作 程序设计(新)专业科技 新华书店正版图书籍 人民邮电出版社
Process finished with exit code 0
“股票数据”定向爬虫实例





# CrawBaiduStocksA.py import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockURL): html = getHTMLText(stockURL) soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue def getStockInfo(lst, stockURL, fpath): for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html == "": continue infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div', attrs={'class': 'stock-bets'}) name = stockInfo.find_all(attrs={'class': 'bets-name'})[0] infoDict.update({'股票名称': name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f: f.write(str(infoDict) + '\n') except: traceback.print_exc() continue def main(): stock_list_url = 'https://quote.eastmoney.com/stocklist.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'C:/BaiduStockInfo.txt' slist = [] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) main()
# CrawBaiduStocksB.py import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url, code="utf-8"): try: r = requests.get(url) r.raise_for_status() r.encoding = code return r.text except: return "" def getStockList(lst, stockURL): html = getHTMLText(stockURL, "GB2312") soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue def getStockInfo(lst, stockURL, fpath): count = 0 for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html == "": continue infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div', attrs={'class': 'stock-bets'}) name = stockInfo.find_all(attrs={'class': 'bets-name'})[0] infoDict.update({'股票名称': name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f: f.write(str(infoDict) + '\n') count = count + 1 print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="") except: count = count + 1 print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="") continue def main(): stock_list_url = 'https://quote.eastmoney.com/stocklist.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'C:/BaiduStockInfo.txt' slist = [] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) main()
股票数据定向爬虫
(1) 目标:获取上交所和深交所所有股票的名称和交易信息
新浪股票:http://finance.sina.com.cn/stock/
百度股票:https://gupiao.baidu.com/stock/
选取原则:股票信息静态存在于HTML页面中,非js代码生成
没有Robots协议限制
选取方法:浏览器 F12,源代码查看等
选取心态:不要纠结于某个网站,多找信息源尝试
获取股票列表:
东方财富网:http://quote.eastmoney.com/stocklist.html
获取个股信息:
百度股票:https://gupiao.baidu.com/stock/
单个股票:https://gupiao.baidu.com/stock/sz002439.html
(2) 程序的结构设计
步骤1:从东方财富网获取股票列表

获取股票信息列表代码:
# 获得股票的信息列表 # 第一个参数是列表类型,里面存储了所有股票信息 # 第二个参数就是获得股票列表的url def getStockList(lst, stockURL): html = getHTMLText(stockURL, "GB2312") soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: #找到其属性 href = i.attrs['href'] # 用正则表达式的方法找到股票代码 lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue
步骤2:根据股票列表逐个到百度股票获取个股信息

代码:
# 获得每只个股的股票信息 # 第一个参数股票列表,第二个参数URL网站,第三个参数存储路径 def getStockInfo(lst, stockURL, fpath): count = 0 for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html == "": continue # 记录所有个股信息 infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div', attrs={'class': 'stock-bets'}) # 获取股票名称 name = stockInfo.find_all(attrs={'class': 'bets-name'})[0] infoDict.update({'股票名称': name.text.split()[0]}) # 获取股票信息 keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val # 将数据写到文件中 with open(fpath, 'a', encoding='utf-8') as f: f.write(str(infoDict) + '\n') count = count + 1 # 实现爬取动态进度条 print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="") except: #为了知道出错是在哪一行 traceback.print_exc() count = count + 1 print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="") continue
步骤3:将结果存储到文件
(3) 整体代码
# CrawBaiduStocksB.py import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url, code="utf-8"): try: r = requests.get(url) r.raise_for_status() r.encoding = code return r.text except: return "" # 获得股票的信息列表 # 第一个参数是列表类型,里面存储了所有股票信息 # 第二个参数就是获得股票列表的url def getStockList(lst, stockURL): html = getHTMLText(stockURL, "GB2312") soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: #找到其属性 href = i.attrs['href'] # 用正则表达式的方法找到股票代码 lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue # 获得每只个股的股票信息 # 第一个参数股票列表,第二个参数URL网站,第三个参数存储路径 def getStockInfo(lst, stockURL, fpath): count = 0 for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html == "": continue # 记录所有个股信息 infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div', attrs={'class': 'stock-bets'}) # 获取股票名称 name = stockInfo.find_all(attrs={'class': 'bets-name'})[0] infoDict.update({'股票名称': name.text.split()[0]}) # 获取股票信息 keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val # 将数据写到文件中 with open(fpath, 'a', encoding='utf-8') as f: f.write(str(infoDict) + '\n') count = count + 1 # 实现爬取动态进度条 print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="") except: #为了知道出错是在哪一行 traceback.print_exc() count = count + 1 print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="") continue def main(): # 获取股票列表的url stock_list_url = 'http://quote.eastmoney.com/stocklist.html' # 获取股票信息的url stock_info_url = 'https://gupiao.baidu.com/stock/' # 保存到盘的根目录 output_file = 'E:/BaiduStockInfo.txt' slist = [] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) main()
(4) 输出结果
{'昨收': '1.14', '成交量': '3612手', '股票名称': '长信中证能源','折价率': '-0.62', '成交额': '41.80万', '今开': '1.14', '净值':'1.1360', '最高': '1.20', '最低': '1.12'}
{'昨收': '1.03', '成交量': '651手', '股票名称': '长信优选', '折价率': '2.40', '成交额': '6.68万', '今开': '1.03', '净值':'1.0029', '最高': '1.03', '最低':'1.03'}
{'昨收': '1.00', '成交量': '766手', '股票名称': '精准医疗', '折价率': '0.74', '成交额': '7.70万', '今开': '1.00', '净值':'1.0006', '最高': '1.01', '最低':'1.00'}
{'昨收': '0.95', '成交量': '74手', '股票名称': '互联医疗', '折价率': '0.64', '成交额': '7123', '今开': '0.95', '净值': '0.9459', '最高': '0.95', '最低': '0.95'}
{'昨收': '0.94', '成交量': '1手', '股票名称': '互联医C', '折价率': '1.13', '成交额': '95', '今开': '0.95', '净值': '0.9433', '最高': '0.95', '最低': '0.95'}
{'昨收': '1.22', '成交量': '2424手', '股票名称': '生物科技', '折价率': '-0.21', '成交额': '29.27万', '今开': '1.22', '净值':'1.2075', '最高': '1.22', '最低':'1.21'}
{'昨收': '1.21', '成交量': '1284手', '股票名称': '生物科C', '折价率': '-0.68', '成交额': '15.38万', '今开': '1.21', '净值':'1.2062', '最高': '1.21', '最低':'1.19'}
{'昨收': '1.08', '成交量': '125手', '股票名称': '中药基金', '折价率': '1.26', '成交额': '1.34万', '今开': '1.07', '净值':'1.0715', '最高': '1.09', '最低':'1.06'}
{'昨收': '1.07', '成交量': '1794手', '股票名称': '中药C', '折价率': '0.62', '成交额': '19.26万', '今开': '1.07', '净值':'1.0694', '最高': '1.08', '最低':'1.07'}
{'昨收': '0.97', '成交量': '2.69万手', '股票名称': '财通升级(LOF)', '折价率': '-1.13', '成交额': '259.98万', '今开':'0.97', '净值': '0.9760', '最高':'0.97', '最低': '0.96'}
{'昨收': '1.07', '成交量': '532手', '股票名称': '券商基金', '折价率': '0.23', '成交额': '5.66万', '今开': '1.06', '净值':'1.0636', '最高': '1.07', '最低':'1.06'}
{'昨收': '0.94', '成交量': '1507手', '股票名称': '国泰融丰', '折价率': '-2.77', '成交额': '14.14万', '今开': '0.94', '净值':'0.9647', '最高': '0.94', '最低':'0.94'}
{'昨收': '1.00', '成交量': '9417手', '股票名称': '南方原油', '折价率': '-1.39', '成交额': '94.33万', '今开': '1.00', '净值':'1.0141', '最高': '1.00', '最低':'1.00'}
{'昨收': '0.86', '成交量': '2476手', '股票名称': '军工基金', '折价率': '0.04', '成交额': '21.20万', '今开': '0.85', '净值':'0.8567', '最高': '0.86', '最低':'0.85'}
{'昨收': '1.10', '成交量': '154手', '股票名称': '国企改', '折价率': '-0.43', '成交额': '1.70万', '今开': '1.10', '净值':'1.1058', '最高': '1.10', '最低':'1.10'}