简介
在这一次的结对编程作业中,我们关注的主题是Code Search,即如何根据用户输入的自然语言,查询得到相关的代码或代码片段。
为了解决这一问题,已经有许多方法被提出,如 CodeHow, CODEnn, CodeNet 等等。这一次作业中,我们选择CODEnn作为我们的baseline,将其复现并尝试提出新的改进。
重现基线模型
CODEnn这一模型由Xiaodong Gu等作者在Deep Code Search一文中提出,其核心思想是把代码和自然语言embed到一个共同的空间,并在这一空间中使用cosine similarity来衡量代码和自然语言的相似度。当用户查询时,返回相似度最高的几个代码片段。其网络结构如图所示: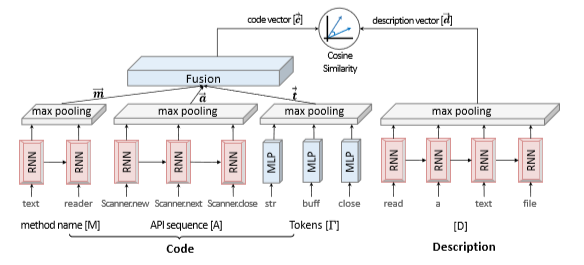
基本架构
如图中所示,code一共用了三个部分的内容:method name, API 和 token, 这三个部分各自embed得到一个高维空间的向量,再用一个全连接层进行融合,最后得到一个向量代表这一段代码的特征;而desrciption直接通过embed就得到了一个向量,代表输入的自然语言的特征。那么embed阶段是怎么完成的呢?embed阶段有三步:
1)word embedding, 把每一个词汇转化为一个向量,语义相近的词得到的向量距离相近;
2)rnn, 使用rnn来进行sequence embedding, 得到的结果记为 h1 h2 ... ht
3) max pooling, 将h1 h2 ... ht整合成一个向量,也就是outputi = max(h1i h2i ... hti)
4) 我们发现,token这一部分没有用rnn,而是用了MLP,论文中对此的解释是token在代码中没有严格的顺序,所以不适合用rnn.
模型优缺点
优点: 这一个模型有效地利用code与description的语义信息,可以更有效地进行比较、查询;
缺点:maxpooling这一操作显得比较粗糙。在下一部分中,我们也尝试针对这一点进行改进。
复现结果
| k | 1 | 5 | 10 |
|---|---|---|---|
| R@k | 0.305590 | 0.590764 | 0.701910 |
上表是我们的测试结果,R@K代表在前k个结果中能找到正确答案的几率。我们使用的数据集是py-github,因为数据集与论文中的不同,所以无法直接比较;但通过与其他组的结果对比,可以认为我们基本完成了模型的复现。
尝试提出改进
正如前文所提及的,我们认为maxpooling的方法比较粗糙,会造成比较多的信息丢失,所以我们尝试对这一部分进行改进。
改进方法
maxpooling的目的是将rnn输出的h1 h2 ... ht合并成一个,这里的t并不固定;这些特征正好可以应用attention, 所以我们尝试使用attention的方法来替代maxpooling。
以合并API中rnn的输出为例,我们假设其rnn输出为a1 a2 ... am,并假设description的rnn输出为d1 d2 ... dn,其过程如下:
1)计算内积: wij = aiT dj
2) 使用softmax: bij = exp(wij) / \(\sum\) exp(wij)
3) 计算输出: aout = a1 * \(\sum_{j=1}^n\)b1j + ... + am * \(\sum_{j=1}^n\)bmj
改进实现
因为和原来的方法差别不太大,只替代了max pooling的部分,所以实现起来比较快,也就没有使用源代码管理了;而是和队友一起体验了一下结对编程,两个人一起改。
新模型结果
Unfortunately, 新模型整个垮掉了,在train, val, test上的结果都很差。大概率是我们的代码实现哪个地方出错了,回头还要再找找原因。
结对伙伴
我的结对编程伙伴是帅气多金的安南。在这一次的作业中,安南提出了改进方法并且一同实现了它。不过因为比较忙吧,我们两个人都没有花特别多的时间在这作业上面,一些参数都没有仔细调过。但总体来说,我们还是认真地完成了这次作业。