Accurate and Scalable Cross-Architecture Cross-OS Binary Code Search with Emulation [TSE 2018]
Yinxing Xue, University of Science of Technology of China
Zhengzi Xu, Nanyang Technological University
Mahinthan Chandramohan, Nanyang Technological University
Yang Liu, Nanyang Technological University
与源代码克隆检测不同,二进制可执行文件中的克隆检测(类似代码搜索)面临着巨大的挑战,因为编译器、体系结构和操作系统的不同配置导致二进制代码的语法和结构存在巨大差异。现有研究提出了不同类型的检测二进制代码克隆的特征,包括CFG结构、CFG中的n-gram、输入/输出值等。在我们之前的研究和工具BINGO中,为了减轻CFG结构中由于不同编译场景而产生的巨大差异,我们提出了一种选择性内联技术,通过内联相关库和用户定义函数来捕获完整的函数语义。然而,BINGO只考虑输入/输出值的特征。在这项研究中,我们建议结合不同类别的特征(例如结构特征和高级语义特征)来提高准确性,并通过仿真来提高效率。我们经验地比较了我们的工具BINGO- e与之前的工具BINGO和可用的最先进的二进制代码搜索工具在搜索精度和性能方面的差异。结果表明,在跨架构匹配、跨操作系统匹配、跨编译器匹配和编译器内匹配方面,BINGO- e的准确性明显高于BINGO。此外,在匹配分叉项目的二进制文件的新任务中,BINGO-E也表现出比现有基准测试工具更好的准确性。同时,BINGO- e算法在匹配过程中比BINGO算法花费的时间更短。
一句话 - BinGo-E: 结合不同类别特征提高BinGo的准确性,应用仿真提高执行效率。
(这篇论文是BinGo的扩展,创新点主要有3D-CFG方法的应用,Emulation提取动态低层语义特征,加了静态高层语义特征和静态底层语义特征,其余的大致和BinGo一致,可以参考另一篇blog分享
导论
Background
使用GPL下的软件,新软件(甚至商业上的开源项目和开放软件的繁荣)可以重用现有相关项目的代码。然而,大量重用现有代码会导致一些法律和安全问题。根据“gplviolations.org”[1]的报告,已经在软件产品中发现了200多个违反GNU公共许可证的案例。其中,VMWARE就是因违反GPL而面临诉讼的知名软件供应商。同时,代码重用带来的风险是,已重用项目中披露的漏洞可能会以未披露漏洞的形式传播到新的商业产品中。例如,2014年12月,网络时间协议(NTP) ntpd实施中的漏洞影响了导入该协议的产品,如Linux发行版、思科的5900x和苹果的OSX交换机。
当可执行文件或库的源代码不可用时,二进制代码搜索可以方便完成各个软件组件中的GPL违规检测、软件抄袭检测、逆向工程、语义恢复、恶意软件检测和漏洞(脆弱)代码识别等任务。然而,二进制代码搜索是一个比源代码搜索更具挑战性的基本问题,这是由于平台、体系结构和编译选项造成的语法差距。
在源代码搜索中,两个代码段的相似性是基于源代码的一些表示来衡量的,例如基于令牌[12]、抽象语法树(AST)[13]、控制流图(CFG)[14]或程序依赖图(PDG)[15]的方法。所有这些表示都捕获程序的语法或结构信息,并为源代码搜索产生准确的结果。然而,这些方法在应用于二进制代码搜索时失败。原因是由于体系结构、平台或编译选项的选择,相同的源代码可能被编译成具有不同结构的程序集代码。因此,语法或结构信息对于精确的二进制代码搜索是不够的。
实际上,二进制代码克隆搜索比典型的二进制代码克隆搜索问题更复杂,后者是在相同架构和平台中的两个类似项目中查找二进制代码克隆。通常,它需要跨体系结构和跨操作系统。假设有一个著名的开源项目(例如libXML2)被报道包含一些关键的有bug的代码,我们需要找到相应的应用程序的有bug的二进制代码,这些应用程序可以在不同的架构和平台上重用该项目的代码。为了解决上述问题,我们提出了一个精确而可扩展的跨架构和跨OS的二进制代码搜索工具的三个理想特性。
- P1 对编译器、体系结构和操作系统的不同配置导致的语法和结构差异具有弹性
- P2 准确地捕捉抽象和完整的函数语义,平衡编译器优化级别的影响
- P3 可扩展到现实世界的大型二进制文件,避免基于动态执行或约束求解的分析开销
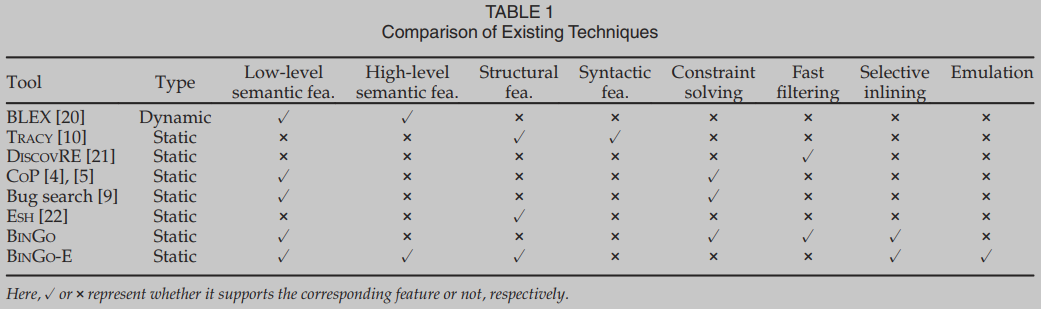
在表1中,我们列出了文献中最先进的二进制代码搜索工具。在这些工具中,只有BLEX[20]是使用运行执行生成的7个语义特征的动态函数匹配工具。所有其他工具都采用静态分析,因此会遇到P1和P2中的问题。TRACY[10]使用纯语法信息进行函数匹配,它使用k-tracelet(即沿控制流路径长度为k的基本块),这是与体系结构和os相关的。discover[21]建议以一种可伸缩的方式在二进制文件中查找跨体系结构的错误,它使用两个过滤器(数值和结构)来快速定位目标函数的相似候选。COP[4]是一个抄袭检测工具,它采用定理证明来搜索语义等价的代码段。[9]中提出的错误搜索工具支持跨体系结构分析,方法是将二进制代码转换为中间表示,并求解输入和输出变量的赋值公式。ESH[22]受到图像组合的相似性思想的启发,提出将每个过程分解为小的代码段(所谓的链),从语义上比较链以确定相似性,并将结果提升为过程。
为了匹配二进制代码克隆,采用了两种基本方法。第一个是使用IDA PRO [28], DYNINST [29], ANGR[30]等工具进行静态分析。这些工具允许在二进制程序中构建二进制函数的控制流图(CFG)。基于二元函数的相似度,测量了两个二元函数的相似度。最近,为了匹配Android上的字节码克隆,[31]中提出了3D-CFG的概念。3D-CFG,顾名思义,是将函数的CFG投影到3d坐标系中。传统上,CFG相似度是通过图匹配或图同构来度量的。在3D-CFG中,每个函数都被认为是3d坐标系中的一个对象,两个函数的相似度是通过分别代表两个函数的两个对象质量质心之间的距离来衡量的。另一种方法是利用仪器或仿真工具进行动态分析。在这些工具中,最基本的是QEMU[32],这是一个免费的开源托管管理程序,用于执行硬件虚拟化。QEMU可以模拟计算机的大多数功能。许多现代仿真器都是在QEMU上扩展的。在这些扩展中,UNICORN[27]是一个轻量级的多平台、多架构CPU模拟器。通过使用即时编译器技术,它具有高性能,并支持各种级别的细粒度插装。使用UNICORN执行二进制函数,对两个二进制代码段的匹配可以简化为比较两个二进制代码段的I/O值。
Motivation
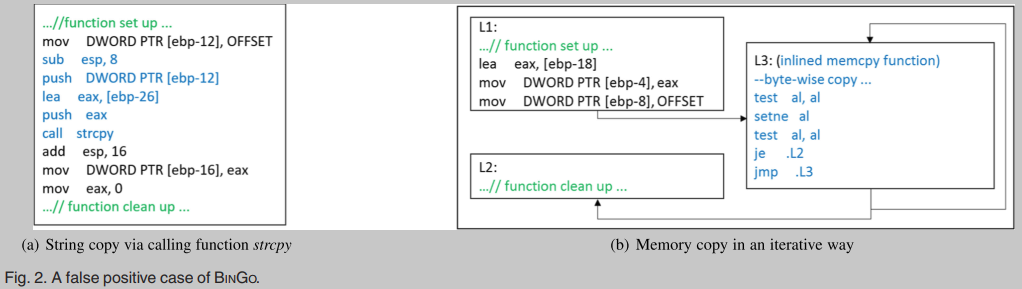
在我们之前对一些现实世界二进制[23]的评估中,对于相同的任务,BINGO在搜索精度和性能方面优于现有的最先进的工具(即TRACY[10]和BINDIFF[24])。然而,我们在使用BINGO时发现了一些假阳性(FP)的情况。当函数具有较小的汇编指令时,从该函数中提取的低级语义特征可能过于通用,无法包含任何真正的语义。例如,图2显示了由于相同的输入/输出值导致的BINGO假阳性情况。
为了解决FP情况,我们的工具BINGO-E的新版本支持高级语义特征和结构特征。我们使用的高级语义特征是系统调用或库调用的信息;另一方面,我们借鉴了基于将CFG投影到三维坐标[26]质心的快速字节码克隆检测思想。受此方法(3D-CFG,简称[26])的启发,图同构问题被简化为计算质心之间距离的问题。在BINGO-E中实现的3D-CFG采用了如下结构信息:基本块(BB)序列、环路信息以及BB的进/出度。
为了加快这一过程,BINGO-E利用模拟,而不是在提取低级语义特征时使用的约束求解。我们采用UNICORN[27] (一个轻量级的多平台、多架构CPU仿真器框架)来虚拟执行从给定函数的函数模型中提取的部分跟踪。模拟步骤可能比约束求解花费的时间要少得多。集成UNICORN[27]的挑战在于函数调用的句柄。最后,结合两个函数在结构、低级语义和高级语义方面的相似度得分进行最终匹配。
Contributions
(1) 第一次尝试将仿真与跨体系结构、跨操作系统的二进制代码搜索结合起来
(2) 基于质心克隆检测的思想提取结构特征。此前,基于3D-CFG的匹配主要应用于字节码克隆检测
(3) 将表1中列出的不同类别的特性组合在一起。在跨架构匹配、跨操作系统匹配和跨编译器匹配的场景下评估提出的方法
(4) 在搜索精度和性能方面对BINGO-E与BINGO和可用的最先进的二进制代码搜索工具进行了实验比较
我们进行了各种实验来评估BINGO-E的有效性。对于coreutils二进制文件上的跨体系结构匹配,平均而言,BINGO-E的最佳匹配率(65.6%)明显优于BINGO(35.1%)。对于coreutils二进制文件上的交叉编译器匹配和编译器内部匹配,平均而言,最佳匹配率从30- 60% (BINGO)的范围提高到70- 99% (BINGO- e)的范围。对于Windows二进制mscvrt和Linux二进制libc上的跨操作系统匹配,平均而言,最佳匹配率从22% (BINGO)提高到51.7% (BINGO-E)。在分叉项目的二进制代码匹配的额外实验中,BINGO-E实现了更高的最佳匹配率(93.6%),而不是现有基准测试工具的最佳匹配率(88%)。最后,通过仿真,显著加快了底层语义特征提取最耗时的部分,从而可以引入更多的特征来提高准确率。
方法
Overview
BINGO-E,作为BINGO的一个新的扩展,旨在成为一个精确的和可扩展的二进制代码搜索引擎。给定一个要匹配的二进制函数(搜索中的签名函数),BinGo-E从分析的二进制函数池(搜索中的目标函数)中返回函数,根据它们的语义相似性进行排序。
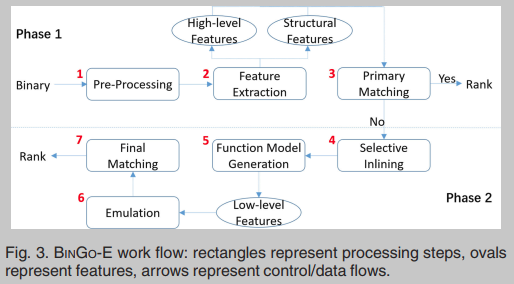
BINGO-E的工作流程如图3所示。输入是一个二进制函数作为签名函数,一组候选函数作为可能的目标。输出是超过用户定义的相似分数阈值的候选目标函数的排序列表。在第一步,给定一个签名函数,它执行预处理,即分解和构建签名函数的CFG。在步骤2中,从表2中的高级语义和结构信息中提取这些特征。如表2所示,我们提取了6种高级语义特征和3D-CFG结构特征。第3步,基于高级语义特征的Jaccard距离和结构特征的质心距离,进行主匹配步骤,测量相似度。如果没有结果高于相似阈值,该过程将继续比较低级语义特征。如果第3步没有返回,则第二阶段匹配开始。在第4步,对于目标二进制文件中的每个函数,函数调用将被识别,并根据所调用的库和其他用户定义函数的相关性选择性内联。在步骤5中,签名功能,长度变异部分跟踪(k-tracelets)生成和分组形成了功能模型,哪些底层语义特征提取。注意,函数模型生成和特征提取是一次性的工作。在第6步,我们依靠模拟来获得签名函数的输入/输出值、标志、内存地址作为低级语义特征。最后,在第7步,结合Jaccard距离的低级语义特征和主要匹配的结果,BINGO-E以排序顺序返回高于相似阈值的目标函数。综上所述,在图3中,步骤2、3、6、7是在BINGO-E中新引入的。

BINARY CODE MATCHING FEATURES
在本节中,我们详细阐述了用于测量两个二进制代码段的相似性的特征。如表2所示,这些特性分为三类。对于表2中的每个特性,下面的部分给出了示例和描述。通过静态分析提取结构特征和高级语义特征,这是步骤2的功能。最后是用模拟执行获取低层语义特征。
3D-CFG的思想最初用在安卓字节码匹配上,思想核心是为方法的控制流图(CFG)中的每个节点(基本块)分配一个结构三维坐标值,然后计算这些坐标的质量质心作为方法的质心。通过计算两种方法质心之间的距离,可以测量两种方法之间的相似性。
权重w是基本块的指令数,加权的权重w’是w+N,N是函数调用指令数目。

质心差度

函数f的签名用两个质心表示,一个是普通质心,一个是函数调用加权的质心
给定两个函数,函数级差度定义为它们的质心距离(CDD)与其权重质心距离(加权)之间的最大值
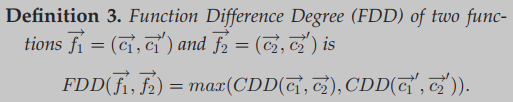
请注意,将3D-CFG应用于二进制代码搜索的挑战在于为二进制代码[39]构建精确CFG的挑战和复杂性。一般来说,反编译Java字节码比反编译二进制代码更容易。因此,为了进一步提高3D-CFG的精度,还需要解决如何获得准确的循环(间接调用循环跳转)结构以及如何从代码中区分数据等问题。这些问题超出了本文的讨论范围。
Low-Level Semantic Features
Features Newly Added in BINGO-E
如上所述,寄存器的输入/输出值不能直接用于跨体系结构的代码搜索。由于采用了仿真,BINGO-E现在在提取函数参数和函数使用的中间值的特征方面更快、更方便。因此,为了进一步提高低级语义特征的准确性,我们建议合并以下中间值的特征,这些特征也在BLEX[20]中使用:

地址分析的基本思想是:在模拟之前,我们假设堆栈的起始地址(ebp)为某个十六进制值。然后在模拟中,我们在每条指令执行后继续跟踪堆栈的结束地址(esp)。如果一个操作位于ebp和esp之间的地址,我们可以知道该操作在堆栈上(属于" v3 “或” v4 ")。否则,我们将把它视为堆上的操作(属于“v1”或“v2”)。然而,很少有情况下指令是在全局堆栈(全局变量的堆栈)上操作的。在模拟中,很难进一步区分这些非堆地址,因此我们只将这些地址视为堆地址。
Emulation
模拟比实际执行快,也比约束求解快得多。在BINGO-E中,对特征值的提取采用了仿真。给定两个代码段,我们假设它们具有相同的初始内存状态(即相同的地址和布局)。对于同一体系结构上的代码匹配,我们在模拟过程中检查寄存器的值、模拟后的标志以及堆栈和堆上读写操作的地址; 而对于跨体系结构的代码匹配,我们在模拟后检查标志的值,并在模拟期间检查堆栈和堆上读/写操作的地址。例如,对于图6中的三个代码段,具有相同的初始内存状态,它们具有相同的最终内存状态——溢出标志(V-flag)为0,零标志(Z-flag)为1,负标志(N-flag)为0,进位标志(C-flag)是一致的。图6a和图6b中的代码段是在相同的架构上进行代码匹配的,因此寄存器eax和ebx的结果值也相同。此外,在这种情况下,我们还使用从程序堆/堆栈中读取或写入值的低级特性。例如,0x1100是写入堆栈的中间值。

在仿真部分,主要的技术挑战是1)处理函数调用和2)为寄存器、标志和内存地址选择输入或初始值。注意,模拟与选择性内联并不冲突。模拟步骤位于选择性内联步骤之后,因此许多重要的函数调用(例如,系统调用和库调用)都已内联。对于没有选择用于内联的函数调用,我们针对不同的场景采用两种不同的策略:
(1) 在匹配来自相同代码库的二进制代码时,我们采用内联-无-策略,即这些调用的函数都不会内联。基本原理是双重的:没有通过选择性内联进行内联的函数不太可能代表程序的语义(更有可能是实用函数);由于签名函数和目标函数都有被调用的函数(由于相同的代码库),对于相同的输入,忽略被调用的函数仍然应该为语义克隆产生相同的结果。
(2) 在匹配来自不同代码库的二进制代码时,我们采用内联全部的策略,即所有被调用的函数都将内联以模拟指令的执行。原因是,从不同代码库编译的二进制段通常调用不同的系统调用或库调用——忽略它们将带来错误,并导致相同输入的不同结果,即使两个二进制段是语义克隆
对于模拟输入,我们采用使用三个完全不同的输入值的策略。对于要通过仿真来匹配的两个二进制函数,我们为它提供三种类型的输入:所有值都是0x0000,所有值都是0x1111,所有值都是随机值。如果对这三种类型的输入都按照低级语义特征匹配两个二进制段,我们认为它们是匹配的。
实验

Robustness
图10总结了coreutils二进制的平均结果(选择性内联之前和之后),其中我们报告了排名第一的函数的百分比(即最佳匹配)。在图中,条G64-G32(内联后)应该被读取为,当函数编译时,使用gcc,对于x86 64位架构被用作签名,大约55%的编译函数,使用gcc,对于x86 32位架构达到排名1。可以观察到,当使用ARM二进制函数作为签名时,整体结果显著下降——只有18%的函数排名第一,而x86 32位和64位架构的这一比例约为41%。我们还注意到,与ARM和x86 32位二进制代码相比,ARM和x86 64位二进制代码之间的匹配(内联后)产生了更高的排名。其基本原理是,ARM和x86 64位二进制与x86 32位二进制相比是寄存器密集型的——在ARM和x86 64位架构中,有16个通用寄存器,因此寄存器比x86 32位二进制中使用得更频繁,后者只有8个。
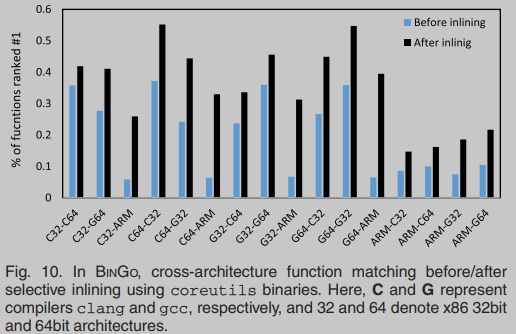
图11显示了BINGO和BINGO- e在coreutils二进制文件上选择性内联后的平均结果。请注意,我们只计算排名第一的函数的百分比(即,在映射来自相同源代码的二进制函数的情况下的最佳匹配)。在图11中,我们列出了16种跨架构代码匹配的可能场景。
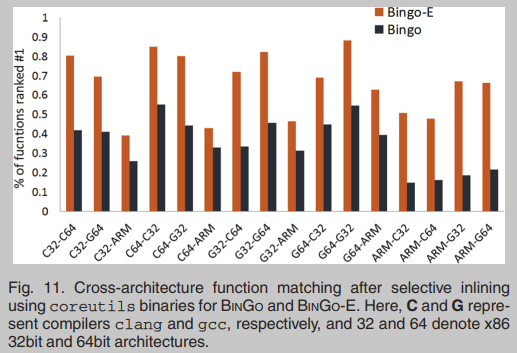
表4总结了BINGO针对x86 32位架构的不同编译器(gcc和clang)、不同优化级别(O0、O1、O2和O3)所获得的结果。在这里,表的每一行和每一列分别表示用于编译签名函数和目标函数的编译器(包括优化级别)。例如,第二行第五列(C1G0)所表示的单元格表示使用优化级别O1的clang编译签名函数的结果,使用优化级别O0的gcc编译目标函数的结果。从表中,我们观察到BINGO是很好的,因为41.5%的函数达到了排名1(在所有为x86 32位编译的二进制实验中平均),而在前10个匹配中,这一比例增加到84%,这是非常有希望的。
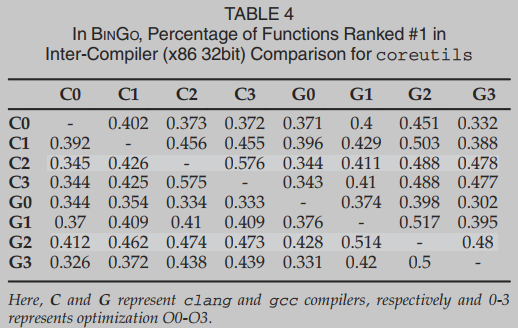
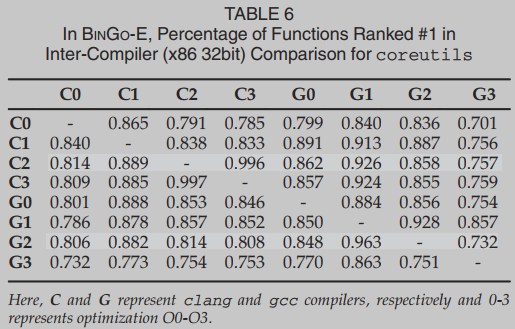
表6总结了在x86 32位架构的coreutils上,bino - e针对不同编译器(gcc和clang)、不同优化级别(O0、O1、O2和O3)所获得的结果。行表示签名函数的优化级别,列表示目标函数的优化级别。我们观察到,通常采用O1或O2时效果最好。当使用O3时,无论gcc还是clang,结果都是最差的(低于80%)。即使C2-to-G1或G2-to-C1也能达到88%以上的精度。因此,对于跨编译器匹配,我们发现编译器差异的影响不如优化级别的影响重要。
与最先进工具的比较。为了将BINGO-E与最先进的工具进行比较,我们使用行业标准二进制比较工具BINDIFF6和公开可用的学术工具TRACY[10]重复上述实验。BINDIFF (v4.1.0)无法将mcvcrt中的表8和表9中的任何函数与libc中的对应函数正确匹配。它的失败根源于对程序结构和调用图模式的严重依赖,而这些不太可能保存在从完全不同的源代码库编译的二进制文件中。对于TRACY,在前50个位置中,只有27个函数具有正确的匹配。


Applications
应用BINGO-E来检测两个可能共享相同或相似代码库的项目的代码抄袭。在本次实验中,我们采用的目标项目与CoP[4]中使用的目标项目相同,即thttpd-2.25b和sthttpd-2.26.4,其中sthttpd从thttpd中分叉出来进行维护。
表10给出了以thttpd为签名函数,以sthttpd为目标函数的匹配结果,表11给出了反过来匹配的结果。在表10和表11中,行指用于编译签名函数的编译器(包括优化级别),列指用于编译目标函数的编译器。
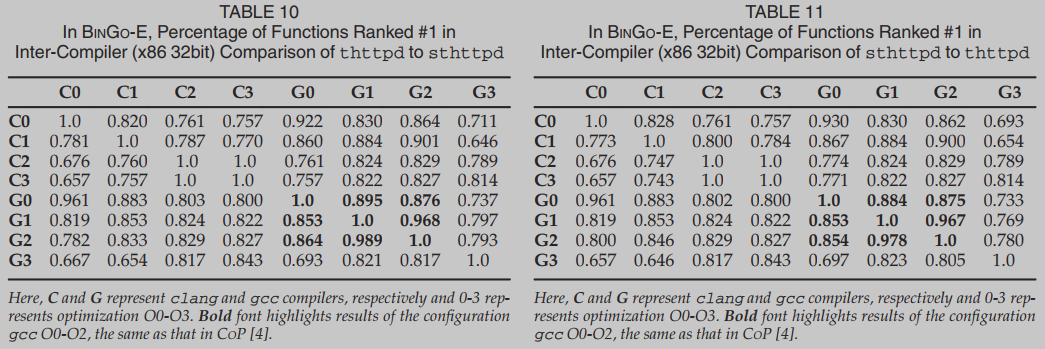
这两个表的结果相当一致。原因是双重的:a) thttpd和sthttpd中的函数是完全克隆的,大多数函数是完全相同的;b) BINGO-E的结果是对称的,因此在匹配时反转签名函数和目标函数的结果没有显著差异。
在相同的优化级别下,这两个项目的功能完美匹配,没有误差。这一完美的结果是由于相同的优化级别导致二进制中相同的BB结构。
一般来说,除了使用相同的优化级别外,gcc G0-G2之间的匹配产生了最好的结果(粗体显示的结果),即表10和表11中平均为93.8%和93.4%。
表10和表11中的C2-to-C3或C3-to-C2的精度均为100%。这说明clang-C2和clang-C3的影响是相似的。
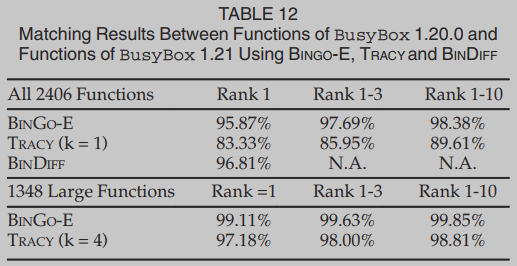
表12显示了BINGO-E、TRACY和BINDIFF在两个版本的BusyBox上的匹配结果。首先,我们使用源(版本1.20.0)中的所有函数与目标(版本1.21)中的所有函数进行匹配。在这三种工具中,BINDIFF在检查最相似的函数时准确率最好,这些函数被排在第一个位置。BINGO-E的精度略低于BINDIFF。但是,其1-3级和1-10级的准确率也高于BINDIFF 1级。
Scalability
在跨架构分析中,比较为一种架构编译的整个coreutils套件(总共103个二进制文件,每个二进制文件平均包含250个函数)平均需要485.2毫秒,而在跨编译器分析中则减少到404.6毫秒。对于跨操作系统匹配的实验,将整个libc二进制文件与msvcrt进行比较需要123.70秒。对于其他大型二进制文件,如BusyBox(约3250个函数,39179个基本块),对所有函数排序需要1307.92秒(每个函数402.4毫秒)。
BINGO-E的主要开销是使用模拟来提取低级语义特征。例如,从2611个libc函数中提取语义特征需要2334.4秒。在实验中,我们进行了16次仿真,以提高鲁棒性。我们发现,如果只运行一次,结果不会有太大变化。类似地,我们能够在787.96秒内从具有1220个函数的msvcrt中提取语义特征。对于其他开销,从msvcrt中提取3D-CFG特征,需要334.73s;而其他高级语义特征的获取大约需要147.67s。在实践中,特征提取过程是一次性的工作,可以很容易地并行化。
总结
References
[1] The gpl-violations.org project, [Online]. Available: http://gplviolations.org/, Accessed on: Sep. 22, 2016
[4] L. Luo, J. Ming, D. Wu, P. Liu, and S. Zhu, “Semantics-based obfuscation-resilient binary code similarity comparison with applications to software plagiarism detection,” in Proc. 22nd ACM SIGSOFT Int. Symp. Found. Softw. Eng., 2014, pp. 389–400
[9] J. Pewny, B. Garmany, R. Gawlik, C. Rossow, and T. Holz, “Crossarchitecture bug search in binary executables,” in Proc. IEEE Symp. Security Privacy, 2015, pp. 709–724. [Online]. Available: http://dx.doi.org/10.1109/SP.2015.49
[10] Y. David and E. Yahav, “Tracelet-based code search in executables,” in Proc. ACM SIGPLAN Conf. Program. Language Des. Implementation, 2014, Art. no. 37. [Online]. Available: http://doi.acm.org/10.1145/2594291.2594343
[12] T. Kamiya, S. Kusumoto, and K. Inoue, “CCfinder: A multilinguistic token-based code clone detection system for large scale source code,” IEEE Trans. Softw. Eng., vol. 28, no. 7, pp. 654–670, Jul.2002. [Online]. Available:http://doi.ieeecomputersociety.org/10.1109/TSE.2002.1019480
[13] L. Jiang, G. Misherghi, Z. Su, and S. Glondu, “DECKARD: Scalable and accurate tree-based detection of code clones,” in Proc. 29th Int. Conf. Softw. Eng., 2007, pp. 96–105. [Online]. Available:http://dx.doi.org/10.1109/ICSE.2007.30
[14] P. P. F. Chan and C. S. Collberg, “A method to evaluate CFG comparison algorithms,” in Proc. 14th Int. Conf. Quality Softw., 2014, pp. 95–104. [Online]. Available: http://dx.doi.org/10.1109/QSIC.2014.28
[15] M. Gabel, L. Jiang, and Z. Su, “Scalable detection of semantic clones,” in Proc. 30th Int. Conf. Softw. Eng., 2008, pp. 321–330. [Online]. Available: http://doi.acm.org/10.1145/1368088.1368132
[20] M. Egele, M. Woo, P. Chapman, and D. Brumley, “Blanket execution: Dynamic similarity testing for program binaries and
components,” in Proc. USENIX Security Symp., 2014, pp. 303–317.
[21] E. Sebastian, Y. Khaled, and G.-P. Elmar, “DiscovRE: Efficient cross-architecture identification of bugs in binary code,” in Proc. 23nd Netw. Distrib. Syst. Security Symp., 2016, pp. 1–15.
[22] Y. David, N. Partush, and E. Yahav, “Statistical similarity of binaries,” in Proc. 37th ACM SIGPLAN Conf. Program. Language Des. Implementation, 2016, pp. 266–280. [Online]. Available: http://doi.acm.org/10.1145/2908080.2908126
[23] M. Chandramohan, Y. Xue, Z. Xu, Y. Liu, C. Y. Choo, and H. B. K. Tan, “Bingo: Cross-architecture cross-os binary search,” in Proc. 24th ACM SIGSOFT Int. Symp. Found. Softw. Eng., 2016,pp. 678–689.
[24] H. Flake, “Structural comparison of executable objects,” in Proc. Detection Intrusions Malware Vulnerability Assessment, GI SIG SIDAR Workshop, 2004, pp. 161–173. [Online]. Available: http://subs.emis.de/LNI/Proceedings/Proceedings46/article2970.html
[26] K. Chen, P. Liu, and Y. Zhang, “Achieving accuracy and scalability simultaneously in detecting application clones on android markets,” in Proc. 36th Int. Conf. Softw. Eng., 2014, pp. 175–186.[Online]. Available: http://doi.acm.org/10.1145/2568225.2568286
[27] Unicorn: The Ultimate CPU Emulator, [Online]. Available: http://www.unicorn-engine.org/, Accessed on: Sep. 22, 2016.
[28] Interactive Disassembler Professional, [Online]. Available: https://www.hex-rays.com/products/ida/, Accessed on: Nov. 2, 2017
[29] Dyninst for Program Binary Analysis and Instrumentation, [Online]. Available: https://github.com/dyninst, Accessed on:
Nov. 2, 2017
[30] Angr: A Python Framework for Analyzing Binaries, [Online]. Available: https://angr.io/, Accessed on: Nov. 2, 2017
[31] K. Chen, P. Liu, and Y. Zhang, “Achieving accuracy and scalability simultaneously in detecting application clones on android markets,” in Proc. 36th Int. Conf. Softw. Eng., 2014, pp. 175–186.
[32] QEMU: A Generic and Open Source Machine Emulator and Virtualizer, [Online]. Available: https://https://www.qemu.org/,
Accessed on: Nov. 2, 2017
Insights
(1) 可用UniCorn模拟执行获取函数动态语义来做嵌入
(2) 3D-CFG方法是字节码匹配提出的方法,可以找相关问题的文献借鉴新方法提高性能和效率