参考:https://github.com/kevinlin311tw/caffe-cvprw15
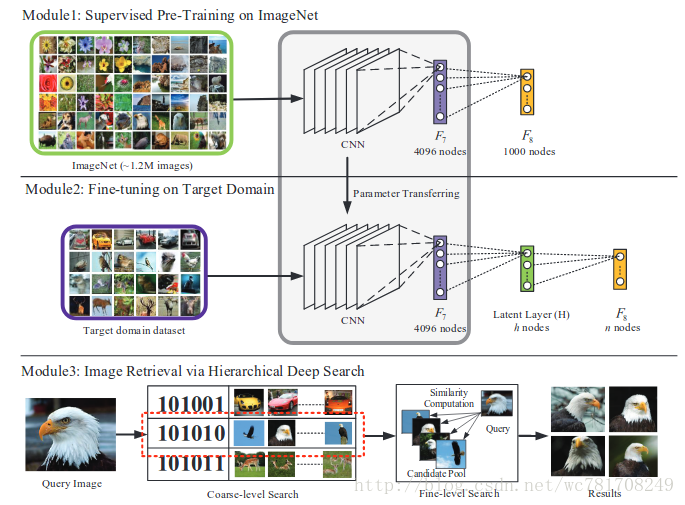
提出的图像检索框架通过分层深度搜索。 我们的方法由三个主要部分组成。 首先是ImageNet上的卷积神经网络的监督预训练,以学习丰富的中级图像表示。 在第二个组件中,我们为网络添加一个潜在层,并让该层中的神经元学习类似散列的表示,同时在目标域数据集上对其进行微调。 最后一步是使用从粗到精的策略来检索相似的图像,该策略利用学习散列式二进制代码和F7特征。
他的第一部分是监督大规模ImageNet的预培训数据集[14]。第二部分是使用潜在层微调网络,以同时学习特定于领域的特征表示和一组类似散列哈希函数。 第三种通过建议的分层深度搜索来获取与查询图像相似的图像。我们使用Krizhevsky提出的预训CNN模型
等人。from the Caffe CNN library 该软件是在大型ImageNet数据集上进行训练的,该数据集包含超过120万张分类为1000个对象类别的图像。 我们的学习二进制代码的方法详细描述如下
3.1. Learning Hash-like Binary Codes
最新研究表明,可以将由输入图像的层F6-8的特征激活层用作视觉特征。这些中级图像表示法的使用表现出色图像分类,检索等任务的改进。但是,这些签名是高维的在大型科学图像检索中效率低下的矢量。为了便于高效的图像检索,降低计算成本的实际方法是将特征向量转换为二进制码。 这种二进制紧凑码可以使用哈希或海明距离进行快速比较。在这项工作中,我们建议同时学习领域特定的图像表示和一组散列(或二进制编码)函数。我们假设分类层F8的最终输出依赖于每个属性开启或关闭的一组h隐藏属性。也就是说,相同标签的图片应该有相同的二进制激活。为了实现这个想法,我们在F7和F8之间嵌入了潜在层H,如图1的中间一行所示。潜在层H是完全连接的层,并且其神经元活动由编码语义的后续层F8调节并实现分类。所提出的潜在层H不仅提供了丰富的抽象来自F7的功能,而且还架设了中级功能和高级语义。在我们的设计中,潜伏层H中的神经元被S形功能(sigmoid)激活,所以激活近似为{0,1}.
为了实现领域适应,我们对提议进行了微调网络在目标域数据集上通过反向传播。 deep CNN 的初始权重被设置为权重来在ImageNet数据集进行训练。潜在层H和最终分类层F8的权重被随机地初始化。潜在层H的初始随机权重就像LSH [6],它使用随机投影来构造哈系bit。然后将代码从LSH改编为适合监督深度网络学习的更好数据的代码。 如果不对深度CNN模型进行重大修改,建议的模型会同时学习领域特定的视觉描述符和一组哈希函数以实现高效的图像检索。
3.2. Image Retrieval via Hierarchical Deep Search
Zeiler和Fergus [32]分析了CNN的深度,发现浅层学习局部视觉描述符,而更深层的CNN捕获适合识别的语义信息。我们采用从粗到精的搜索策略来快速准确地进行图像检索。我们首先检索一组具有类似高级语义的候选者,也就是说,从潜在层类似地隐藏二进制激活。然后,为了进一步过滤具有相似外观的图像,基于最深的中级图像表示来执行相似性排名。
粗略搜索。给定图像I,我们首先提取潜在层的输出作为由Out(h)表示的图像签名。然后通过将阈值进行二值化来获得二进制码。每一位
(其中h是潜在层中的节点数量),我们输出H的二进制码
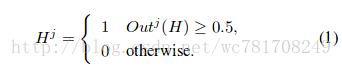
让 { }表示由n个用于检索的图像组成的数据集。 { }表示每个图像的对应二进制码, { }^ .给定查询图像 及其二进制码 ,我们确定了一组m个候选人, { },如果Hamming距离低于阈值在 与 .
精细搜索。
给定查询图像
和候选池P,我们使用从层F7提取的特征来识别排名前k的图像以形成候选池P.设
和
分别表示查询图像q和池中图像
的特征向量。我们将
与P的第i个图像之间的相似度定义为相应特征向量之间的欧几里德距离,

欧几里德距离越小,两幅图像的相似度越高。 每个候选者 按照相似性按升序排列; 因此,识别出排名前k位的图像。
图2:来自Yahoo-1M Shopping Dataset的示例图像。 异构产品图像表现出极大的差异性,并且对图像分类和检索具有挑战性。
文章流程图:
分析:
- 1、先用ImageNet 做一个分类模型
- 2、将自己的数据迁移到1、中的模型上,在F7与分类层的之间添加一个编码层(激活函数使用 sigmoid,取出编码使用 tf.round() 数值大于0.5则为1,反之为0),冻结输入层到F7的所以层参数,只微调编码层与F8(分类层)
- 2-2、也可以直接训练module2这一条网络,训练收敛后(分类精度高),冻结输入层到F7的所以层参数,只微调编码层与F8(分类层),微调时加上一些附加的cost(类别相同 编码层特征欧式距离最小,类别不同 编码层特征欧式距离变大等)
3、类别查询
- 先得到编码( tf.round(编码层)),比较查询图片与要查询库中的每张图片的编码距离(这里使用汉明距离 即 编码求XOR(异或操作) ),汉明距离小于某个阈值(为编码列数的0.2~0.5左右),筛选出备选图片
- 再计算经过上面筛选的图片与查询图片之间的特征欧式距离(这里的特征选编码层特征(不使用 tf.round),也可以选择编码层 的前一层的特征 如:这里是F7层的特征),如果距离至小于某个阈值 (0.065~0.2)则判别为要查询的图片(和查询图片是一个类别)
4、推广到训练集以外的数据进行图片查询
- 按照第3步的操作,查询训练集以外的图片(只使用编码特征层,此时分类的层就没有实际意义,分类精度没有任何意义,因此不用在意分类的效果,遇到分类的直接跳过即可)
