VulHawk: Cross-architecture Vulnerability Detection with Entropy-based Binary Code Search [NDSS 2023]
Zhenhao Luo, Pengfei Wang, Baosheng Wang, Yong Tang, Wei Xie, Xu Zhou, Danjun Liu and Kai Lu
College of Computer, National University of Defense Technology
代码重用在软件开发中非常普遍。它带来的漏洞大量蔓延,威胁软件安全。不幸的是,随着物联网(IoT)的发展和部署,代码重用的危害被放大了。二进制代码搜索是发现这些隐藏漏洞的可行方法。面对不同架构、不同编译器、不同优化级别编译的IoT固件镜像,现有方法难以适应这些复杂场景。在本文中,我们提出了一种新的中间表示函数模型,它是一种用于跨体系结构二进制代码搜索的体系结构不确定模型。它将二进制代码提升为微码,并通过补充隐式操作数和删除冗余指令来保留二进制函数的主要语义。然后,我们使用自然语言处理技术和图卷积网络生成函数嵌入。我们将编译器、体系结构和优化层的组合称为文件环境,采用分治策略将 C N 2 C_N^2 CN2跨文件环境场景的相似度计算问题划分为N−1个嵌入传输子问题。我们提出了一种基于熵的适配器,将不同文件环境中的函数嵌入传输到同一文件环境中,以缓解不同文件环境造成的差异。为了精确识别脆弱函数,我们提出了一种渐进搜索策略,用细粒度特征补充函数嵌入,以减少修补函数造成的误报。我们实现了一个名为VulHawk的原型,并在七个不同的任务下进行了实验,以评估其性能和鲁棒性。实验表明,VulHawk的性能优于Asm2Vec、Asteria、BinDiff、GMN、PalmTree、SAFE和Trex。
一句话 - VulHawk: 使用熵适配器将不同文件环境传输到相同环境进行二进制函数嵌入,并采用细粒度特征的渐进式搜索策略改进嵌入效果,实现跨架构的二进制漏洞函数搜索。
导论
Motivation
代码重用在软件开发中非常普遍。然而,大量的代码和库在没有安全审计的情况下被重用到多个体系结构二进制文件中,这导致软件项目中隐藏了许多漏洞。Synopsys在2021年审计了2409个项目,报告称97%的项目包含第三方代码,其中81%包含已知漏洞[49]。开源代码中的一个漏洞可能会传播到数千个软件中,使数百万人面临严重的软件安全威胁。不幸的是,随着物联网(IoT)的发展和部署,代码重用的危害被放大了。物联网设备被广泛应用于各种场景。针对不同的使用需求,这些来自不同指令集架构(isa)的IoT固件映像由不同的编译器以不同的优化级别生成。然而,许多物联网固件映像只提供二进制文件,没有用于安全分析的源代码。它们的符号信息,如函数名,通常被剥离。因此,二进制代码搜索成为寻找隐藏在物联网设备中的漏洞的活跃研究焦点。
二进制代码搜索用于在大型函数库中查找相似或同源的二进制函数。广泛应用于漏洞检测[5]-[7]、[16]、[29]、[41]、[43]、[48]、[58]。例如,给定一个二进制文件,二进制代码搜索将其函数与漏洞库中的所有函数进行比较,根据函数相似性查找二进制文件中的漏洞函数。此外,它还用于恶意软件分析和二进制补丁分析。由于物联网固件镜像来自不同的编译器、优化级别和指令集,这给二进制代码搜索带来了严峻的挑战,这要求搜索方法具有较高的鲁棒性。
在物联网固件中寻找漏洞需要跨ISA健壮的二进制代码搜索方法。在单体系结构二进制代码搜索中,Asm2Vec[10]、DeepBinDiff[11]和PalmTree[27]使用自然语言处理(NLP)技术取得了令人鼓舞的结果。但是,它们只能搜索同一ISA上的二进制代码,不支持跨体系结构任务。InnerEye[60]将来自不同isa的二进制作为不同的自然语言,并使用神经机器翻译来计算二进制代码的相似度。SAFE[35]使用来自多个ISA的二进制来训练其语言模型,以跨体系结构搜索二进制代码。这些方法严重依赖于训练数据,并且很难实现多个ISA。将特定于体系结构的二进制代码提升为与体系结构无关的中间表示(IR)是解决物联网固件中跨体系结构挑战的有效方法。然而,自然语言和IR有本质的区别。与自然语言不同,IR包含EFLAGS作为隐式操作数(例如,ZF)。这些标志控制函数的执行路径,并对函数语义具有重要含义。此外,提取中大量的冗余指令降低了主语义的权重,影响了主语义的提取精度。
我们考虑3种架构(x86、arm和mips)、2个字大小(32位和64位)、2个编译器(Clang和GCC), 6个优化级别
(O0, O1, O2, O3, Os, Ofast),总共72种组合(3 × 2 × 2 × 6)。如果从上述任意两种组合中选择二进制,则总共有2556种组合场景( C 72 2 C_{72}^2 C722)。现有的[9],[10],[27],[41]方法寄希望于深度学习来缓解这些差异,并针对这些场景建立一个健壮的模型。为一个或几个特定的场景构建健壮的模型是可能的。然而,针对这2556个场景建立一个健壮的模型是复杂的。此外,没有信息直接指示二进制文件中的编译器和优化级别。
为了解决上述问题,本文提出了一种新的跨架构二进制代码搜索方法VulHawk。它包含了一种新的中间表示函数模型(IRFM)来生成健壮的函数嵌入。在IRFM中,我们首先将二进制代码提升为微码。然后,我们将微码序列视为语言,并使用RoBERTa模型[31]的变体来构建基本的块嵌入。我们采用图卷积网络(GCNs)集成基本块嵌入和控制流图(CFGs)来生成函数嵌入。
对于P1中的跨架构挑战,微代码是一种与架构无关的语言,它允许我们的模型从一个ISA训练,并在多个ISA中搜索函数。对于P1中的冗余指令和隐式操作数,我们在IRFM中实现了指令简化。我们将隐式操作数(EFLAGS)的赋值视为真实的赋值指令,这可以帮助IRFM补充隐式操作数语义。对于冗余指令,指令简化是基于defuse关系对微码进行简化,既去掉了冗余指令,又保留了二进制函数的主要语义。这有助于IRFM更精确地提取函数语义。我们还提出了根操作数预测(ROP)和相邻块预测(ABP)预训练任务,以帮助模型理解操作数之间的关系和基本块之间的数据流关系。
对于P2中的挑战,我们采用分治策略,将2556个场景的相似度计算问题划分为71个嵌入转移问题。我们将编译器、体系结构和优化级别的组合称为文件环境。面对72个文件环境,我们选择一个中间文件环境,将不同文件环境中的函数嵌入传递到同一文件环境中,以缓解差异。首先,我们从信息理论的角度引入香农熵[47]来表示二进制文件中的信息量。在实践中,我们发现来自相同文件环境的二进制文件具有相似的熵分布。所以我们使用熵流来识别文件环境。通过了解函数的文件环境,我们部署了一个基于熵的适配器,将这些函数嵌入传输到中间文件环境中,以缓解不同环境造成的差异。在此基础上,我们提出了一种渐进搜索策略来搜索候选函数,以保持检索的高效率和精度。首先,它使用函数嵌入来检索基于欧氏距离的top-K候选函数。然后,提出了一种相似度标定方法,利用细粒度特征对函数嵌入进行补充,以减少误报。
Contributions
(1) 我们提出了一个IRFM来生成跨架构的健壮的函数嵌入。它将二进制代码提升为微码,并通过简化指令来保留二进制函数的主要语义。提出了两个预训练任务来帮助我们的模型学习操作数的根语义和掌握块数据流关系。我们使用GCNs集成基于CFG的基本块嵌入来生成函数嵌入
(2) 根据分治策略,我们从信息论的角度使用熵流来识别二进制文件的文件环境。我们提出了一种基于熵的适配器,将函数嵌入传输到同一个文件环境中,以缓解不同文件环境造成的差异
(3) 提出了一种渐进式搜索策略,该策略使用细粒度特征实现相似度校准,以提高性能并减少修补函数引起的误报
(4) 实现了VulHawk,并在三种不同的场景中评估它:一对一比较、一对多搜索和多对多匹配,这些场景都是跨编译器、优化级别和体系结构的。实验表明,VulHawk的性能优于最先进的方法
(5) 为了便于后续研究,发布了VulHawk的程序和预训练模型 https://github.com/RazorMegrez/VulHawk
Background
二进制相似度分析
跨架构二进制代码搜索旨在为从各种物联网设备中提取的大量二进制函数检索语义相似的候选函数[55]。受现有工作[10],[55],[57]的启发,我们定义两个二进制函数,如果它们是从相同或逻辑相似的源代码编译的,则它们在语义上相似。
与二进位码相似度检测一样,二进位码搜索的核心是设计一个鲁棒模型来检测给定函数是否相似。二进制代码搜索不是一对一匹配,而是考虑一对多搜索,这要求方法能够更快、更准确地检索语义相似的候选项。在现实世界中,物联网固件可以由具有不同优化级别的各种编译器(例如GCC和Clang)编译(例如-O3, -Os),这导致编译的二进制函数具有相同的语义但不同的结构。因此,一个有效的跨架构二进制代码搜索需要达到以下目标:
(1) 支持跨架构
(2) 支持跨编译器
(3) 支持跨编译选项
(4) 高精度和高效率
熵理论
香农的熵理论[47],其中S为元素集合,p(x)表示元素x出现的概率。图1给出了Shannon熵计算的示例。每个模式代表一个不同的元素。
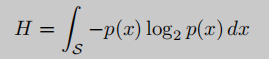
框1中充满了圆熵H为0; 框2有圆形和三角形,比方框1复杂,熵也比方框1大; 框3是三个系统中最复杂的系统,其熵H最高。

通过熵分析,我们可以在深入研究系统之前对系统中的平均信息量有一个预先的了解。在二进制代码搜索任务中,我们通过二进制文件熵得到二进制文件的信息分布,从而推断出它们的编译器和优化级别等信息。这有助于我们的模型为不同的二进制输入选择合适的参数。
方案
Overview
Vulhawk 包含三个组件:中间表示函数模型、基于熵的适配器和渐进式搜索策略。图2显示了总体框架
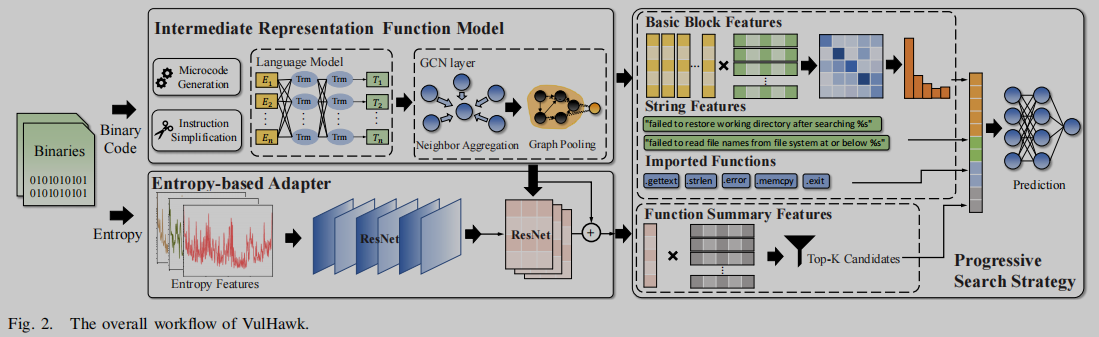
IRFM用于生成基本块嵌入和函数嵌入。我们首先将二进制代码提升为微码。然后,指令简化对隐式操作数语义进行了补充,并对冗余指令进行了删减,既保留了函数的主要语义,又提高了IRFM的鲁棒性。之后,我们使用基于RoBERTa [31] 的语言模型来构建基本的块嵌入。在模型训练中,我们提出根操作数预测和相邻块预测预训练任务,让IRFM理解操作数之间的关系和基本块之间的数据流关系。最后,采用GCNs对相邻基本块嵌入进行聚合,捕获控制流关系,生成函数嵌入。
基于熵的适配器识别输入二进制文件的文件环境,并采用分而治之的策略对来自不同文件环境的函数进行嵌入。在这里,我们从信息论的角度介绍熵。我们首先使用熵来预测文件环境,然后使用基于熵的适配器将函数嵌入根据它们的文件环境传递到中间文件环境中,以减轻文件环境带来的差异。
渐进式搜索策略用于精确检测函数查询的候选项。我们提出了一个两步策略,包括粗粒度搜索和相似度校准。通过相似性校准,我们在检测脆弱函数时过滤了误报(如补丁函数),使我们的模型更加精确。
Intermediate Representation Function Model
中间表示:对于来自各种体系结构的二进制文件,对它们进行反汇编,并将二进制代码提升到一个与体系结构无关的IR。我们在实现中使用了IDA Pro及其IR,命名为microcode,但其他的反汇编器和IR也可以工作。如表1所示,微码组将来自不同体系结构的各种指令分为73个操作码和16种操作数。例如,mop_z表示无操作数,mop_r表示寄存器,而mop_str表示字符串常量。Microcode是一种成熟的IR,可以缓解指令类型差异对跨体系结构二进制代码搜索的影响。更多细节参考 https://www.hex-rays.com/products/decompiler/manual/sdk/hexrays_8hpp_source.shtml
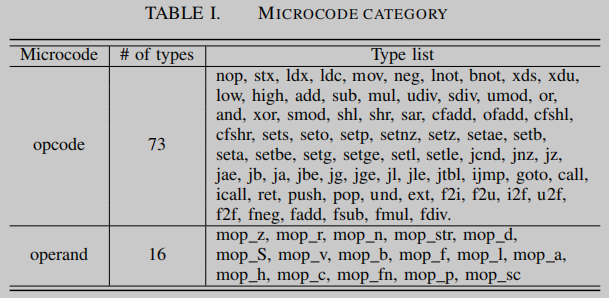
Tokenization
在微码中,一条指令由一个操作码和一个操作数三元组组成,操作数三元组包括左操作数、右操作数和目标操作数。
不同二进制的基址和偏移量不同,引入了噪声,使得模型的鲁棒性较差。我们用一个特殊的标记[addr]来规范化这些地址(例如0x4040E0和0x4150D0)。为了缓解OOV的tokens,会使用如 table I 所示的16种根操作tokens替换。对于词汇表中的操作数,我们使用它们自己的标记,对于那些OOV操作数,我们使用根操作数标记来表示它们的基本语义。在预训练阶段,将频率小于100次的标记替换为它们的根操作数标记,以构建根操作数标记嵌入。
Token Type Layer
与自然语言不同,微码由操作码和操作数组成,而不仅仅是单个单词。操作码表示要执行的操作(例如,ldx和goto),操作数表示操作所使用的数据或内存位置。考虑到这些差异,我们使用令牌类型层来帮助IRFM区分操作码和操作数。我们将标记分为三种类型:操作码、操作数和其他类型。others类型包含一些特殊的标记(例如[pad]),没有实际的语义。
Instruction Simplification
本文提出一种基于def-use关系的指令简化方法,以修剪冗余指令并保留重要语义。首先,我们标记以下“重要”指令以避免删除:(1)全局变量和局部变量存储在内存而不是寄存器中,因此我们标记目标操作数是内存地址的赋值指令,例如图3(a)中的Ln.18。(2)返回值通常存储在特定的寄存器中,例如rax (x86)和x0-x1 (arm)。因此,我们根据所有路径上返回指令附近的调用约定标记特定寄存器,例如图3(a)中的Ln.19。(3)子函数的参数出现在函数调用之前,在传递给子函数之前不会被其他指令覆盖,例如图3(a)中的Ln.2。我们对"重要"指令使用松散规则,以确保没有错误删除主要语义。我们将已定义的寄存器或eflag未在后续指令中使用的指令视为未使用的指令(例如图3(a)中的Ln. 5、12-15),并对其进行修剪。在修剪未使用的指令之后,优化冗余指令(例如图3中的Ln. 5-8)。
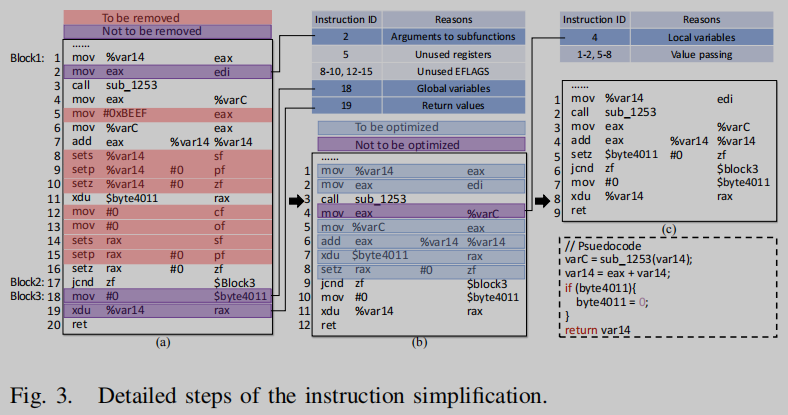
我们关注定义一个寄存器直接赋值给另一个变量的指令,称为值传递指令。通过指令简化,将图3(a)中的20条指令简化为9条指令,保留了图3(a)的主要语义,且与图3(a)的伪代码相似。这有助于IRFM提取更精确的函数语义。在实际应用中,RoBERTa模型接受有限的输入长度,而指令简化使得RoBERTa的输入能够保留更多的有效指令。
预训练任务:在训练阶段,使用掩码语言模型(MLM)、根操作数预测(ROP)和相邻块预测(ABP)进行预训练。
本文提出一个MLM模型来理解微码之间的关系,并构建合适的词嵌入。MLM首先由BERT提出,它使用掩码token周围的上下文token来预测掩码token以优化模型参数。图4显示了一个示例,其中黄色、红色和绿色框分别表示被掩码的标记、被替换的标记和预测结果。在图4中,操作码setz和寄存器r0被掩码为[mask],直接数字常量#0被替换为其根操作数标记mop_n。

在训练过程中,我们将与掩码/替换标记相对应的最终隐藏状态输入到词汇表上的输出softmax中,以预测这些标记的概率。MLM的损失函数使用交叉熵损失如下:

本文提出ROP预训练任务,将token语义与它们的根token语义关联起来,使模型为未登录词生成更可靠的根token语义。在微码中,操作数分为16种类型(见表I)。我们将它们用作根操作数标记。它对OOV操作数是友好的,因为我们可以将OOV操作数转换为它们的根操作数标记,以表示它们的根语义。例如,一个特定的地址0xdeadbeef,假设它是一个OOV操作数,我们的模型为它分配了表示地址操作数的根令牌mop_a的语义,而传统模型无法区分其语义。
由于opcode-root标记本身是操作码标记,因此ROP任务不会预测根操作码标记。我们执行一个ROP头来预测它们的根标记。在训练阶段,我们将token的最终隐藏状态输入线性变换。我们对操作数类型使用输出softmax来预测这些rootoperand token的概率。ROP的损失函数采用交叉熵损失如下:

在二进制函数中,基本块之间存在数据流关系。与自然语言不同,二进制代码中的变量需要在使用之前定义。具有数据流关系的基本块是顺序敏感的,IRFM不能直接捕获这些关系。为训练一个理解相邻块之间数据流关系的模型,提出一种ABP预训练任务。具体来说,给定两个基本块A和B,其中B是A的后继,变量x在块A中定义,变量x在块B中使用。我们将A-B的顺序标记为正,将B-A的顺序标记为负。注意,A和B不是同一个块,A不是B的后继块。此外,我们不考虑A和B只有控制流关系而没有数据流关系的情况。因为如果不支持数据流关系,也可能发生块顺序的倒序。
我们将IRFM中token [cls]的最终隐藏状态输入到ABP头,进行线性变换,以识别输入的两个微码序列是否为正序。ABP的损失函数使用交叉熵损失如下:

语言模型的总损失函数是上述三种损失函数的组合:
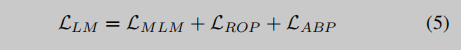
VulHawk中的IRFM的任务是生成函数嵌入。首先,生成基本块嵌入。对于输入微码块,IRFM transformer编码器输出隐藏状态序列。本文应用平均池化层来集成微码指令嵌入。根据预训练模型结果,在预训练过程中,最后一层的隐状态与目标任务(如MLM)过于接近,可能会对这些预训练任务产生偏差。第二层的隐藏状态比最后一层的隐藏状态具有更强的泛化能力。因此,我们对第二层的隐藏状态使用均值池化来生成基本块嵌入。
现有研究[34]、[55]已经表明,基于CFGs的解决方案在跨架构场景下具有优势。本文集成了基本块嵌入和CFGs来生成函数嵌入。考虑到二进制函数的多分支结构,我们使用GCNs[24]捕获CFG结构,并将基本块语义聚集到相邻的基本块中。将二元函数看作属性图,其基本块是图中的节点,其嵌入是节点的属性。我们将属性控制流图(ACFGs)输入到GCN层。X(l)表示第l层节点的特征,聚合函数如下:
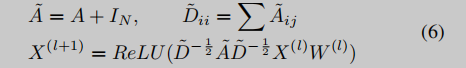
给定两个二进制函数,我们根据函数名和源文件生成真实值y,即不相似(0)和相似(1)。我们使用欧氏距离来计算两个函数的相似度s,如下所示:
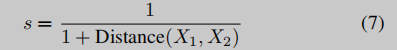
训练目标是使相似函数的相似度趋近于1,不相似函数的相似度趋近于0。我们使用交叉熵损失作为损失函数:

Entropy-based Adapter
在现实世界中,二进制函数由来自不同体系结构的不同优化级别的多个编译器编译。在本文中,我们将编译器、体系结构和优化级别的组合称为文件环境。来自不同文件环境的函数,即使来自同一源代码,其指令和结构也可能不同。
图5显示了在嵌入空间中匹配类似函数的示例。给定一个嵌入空间,相同颜色的点表示相似的函数及其变体。现有方法没有区分函数的文件环境,在混合文件环境中构建一个模型来生成二进制函数的嵌入。不同函数的嵌入在同一文件环境下具有很好的区分度,但混合文件环境可能会导致嵌入冲突,大大增加了二进制代码相似性搜索的复杂度。此外,文件环境之间的差异也不同。例如,O0和O3优化之间的差异以及GCC和Clang编译器之间的差异是不同的。构建一个对所有文件环境都具有高鲁棒性的单一模型是一件困难的事情。
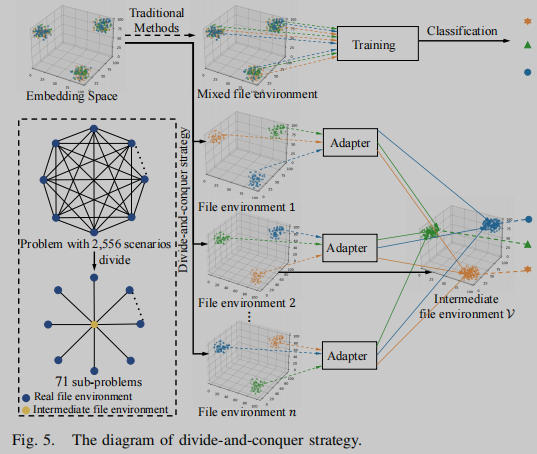
为应对这一挑战,本文提出一种新的分治策略。首先,将混合文件环境的嵌入空间划分为多个嵌入子空间;其次,选择其中一个文件环境V作为中间文件环境,将 C n 2 C^2_n Cn2个场景的N个文件环境之间的函数相似性问题划分为N−1个子函数嵌入迁移问题;最后,使用经过训练的适配器将不同文件环境的函数嵌入迁移到相同的文件环境V中进行相似度计算,以缓解不同文件环境带来的差异。
基于熵的二进制分析:分治策略的一个重要步骤是确定文件环境。二进制函数的体系结构和字长可以通过其指令确定。然而,问题是在二进制文件中没有直接指示编译器和优化级别的信息。为了解决这个问题,本文从信息论的角度来理解二进制文件,并引入熵来识别二进制文件的编译器和优化级别。通常,经过压缩或加密的代码段往往比本机代码[33]具有更高的熵。这也可以用于区分不同的编译器和优化。
图6显示了来自3个文件环境的12个不同二进制文件的熵流。二进制文件的熵流是通过将原始字节分割为十六进制表示(0x00-0xFF)来计算的。可以观察到,来自相同文件环境的熵流看起来是相似的,而属于不同文件环境的熵流是不同的。使用熵流和熵理论,我们可以识别不同的编译器和优化。
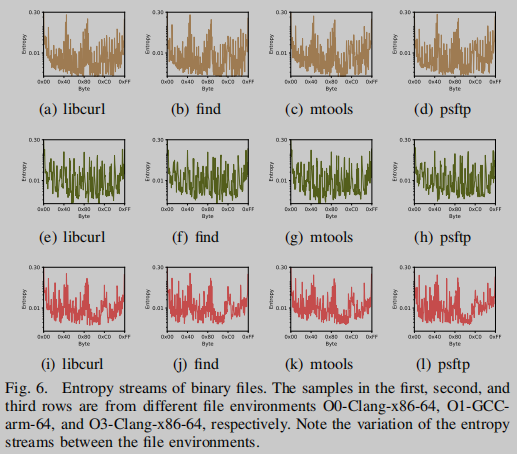
为了防止单熵流可能导致的碰撞问题,我们使用以下功能:
- text段的熵流,包含256个对应的原始字节概率(0x00-0xFF)。
- 文本段熵,是熵流对文本段的积分。这主要关注二进制文件中的可执行部分,避免了数据段更改的影响。
- 文件熵是整个文件熵流的积分,提供了文件级别的全局信息。
图7显示了基本残差块的结构。它由批量归一化和线性变换组成,激活函数为ReLU。在基本残差块输出中添加使用来自输入的身份映射的跳跃连接,保留了函数语义,并有助于解决梯度消失问题。

为了计算不同文件环境下二进制函数的相似度,本文在IRFM之后提出了一种基于熵的适配层。基于熵的适配层作为映射F,将不同文件环境中的函数嵌入转换到相同的中间文件环境V中,以缓解不同文件环境带来的差异。映射F应该既保留函数语义,又减少由于不同的文件环境而产生的偏差。
为了降低训练复杂度,我们冻结了IRFM的参数。将函数相似度作为真值,即dissimilar(0)和similar(1)。训练目标是使相似函数的相似度趋近于1,不相似函数的相似度趋近于0。我们使用交叉熵损失作为损失函数:

Progressive Search Strategy
现有方法利用函数嵌入来搜索相似函数。这是一种粗粒度的检测方法,缺乏细粒度的信息(例如,块级特征),它实现了较低的搜索开销,但会导致较高的误报,特别是对于打过补丁的微小更改的函数。而Marcelli等人[34]使用图匹配网络和[58]、[60]使用孪生网络在细粒度上计算每个函数对的相似度,虽然可以获得较高的性能,但计算成本较高。
面对复杂的漏洞检测场景,本文提出了一种新的搜索策略——渐进式搜索策略,在保持良好性能的同时减轻了计算负担,降低了漏洞检测中补丁函数带来的误报。该策略结合了两个子策略。首先,使用函数嵌入作为粗粒度搜索的全局摘要。其次,通过对候选函数进行两两相似度校准,为函数嵌入补充了细粒度信息,保证了漏洞检测的高精度。
针对高精度二进制代码搜索,本文提出了一种细粒度检测的相似性校准方法。结合基本块、字符串常量和导入函数信息计算两两相似度得分,从中提取向量并与函数级信息相结合,以提升漏洞检测性能。
块级别特征 函数级嵌入可能会丢失块级特征,如块嵌入分布和函数大小。在许多情况下,函数之间的差异存在于较小的子结构中,很难通过函数嵌入反映出来。打个比方,在图匹配中,基于图嵌入的图匹配性能可以通过细粒度的节点级信息来增强。
字符串特征 由于字符串常量和导入的函数在相似的函数对中是相同或相似的,因此它们的相似性也在表示函数的相似性方面起到了一定的作用。
导入函数特征 使用Jaccard指数来计算两个导入函数集 I 1 I_1 I1和 I 2 I_2 I2的相似度 s i s_i si
算法整体如下

计算完上述三个向量后,我们将这些向量与嵌入搜索函数中的相似度 s s s连接到向量 V V V中。然后,将向量 V V V输入前馈网络以学习权重并预测最终函数相似度 s ′ s' s′。我们使用交叉熵损失函数来优化网络权重。最后,我们使用默认阈值 h h h来过滤掉相似的函数作为结果。
实验
设置

One-to-one Comparison
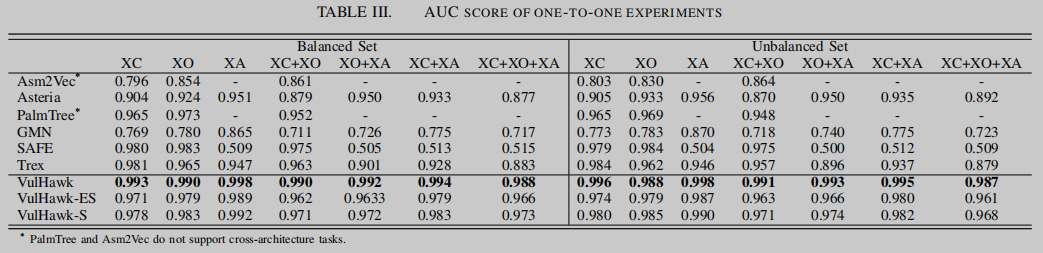
如图所示,VulHawk在平衡和不平衡数据集上的AUC分数在所有实验设置中都优于SAFE、Asteria、GMN、PalmTree、Asm2Vec和Trex。例如,在跨架构(XA)实验中,VulHawk获得了0.998的AUC,其中Trex获得了0.947的AUC, Asteria获得了0.951的AUC, SAFE只有0.509的AUC,而PalmTree和Asm2Vec在跨架构实验中失败。
One-to-many Search
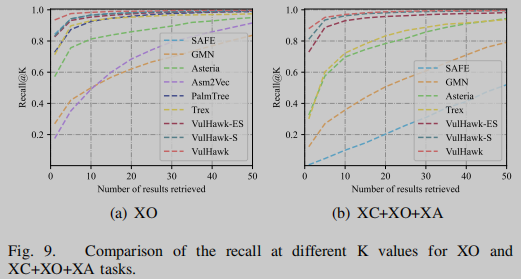
我们在不同的top-K结果中收集召回率,并在图9中绘制召回率与k的关系。结果表明,VulHawk优于目前最先进的方法,在XO任务中取得了最好的recall@1 0.935,在XC+XO+XA任务中取得了0.879。在XC+XO+XA任务中,当检索到的结果数量超过30时,每种方法的召回率都趋于稳定,其中VulHawk达到recall@30 0.994左右,VulHawk- es达到recall@30 0.968左右,VulHawk- s达到recall@30 0.988左右,Trex达到recall@30 0.888左右,SAFE达到recall@30 0.310左右。
Many-to-many Matching
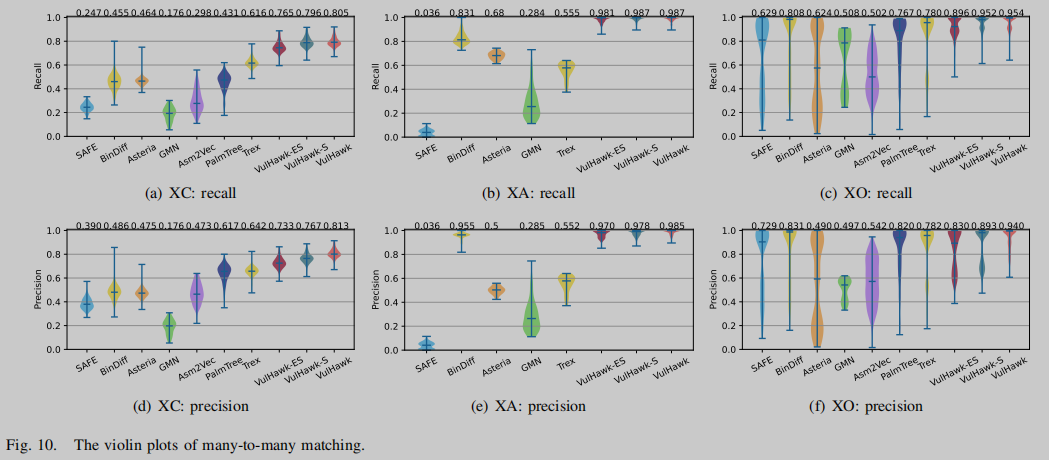
其中,基线在XO实验中O0- O3的结果最低。VulHawk在该实验中取得了0.876的召回率,与SAFE、Asteria、Asm2Vec、BinDiff、PalmTree、GMN和Trex相比,召回率分别提高了385.9%、292.9%、208.6%、240.0%、211.6%、621.3%和202.8%。有趣的是,VulHawk的最差结果(0.805)是在XC实验中,而不是在O0-O3实验中。
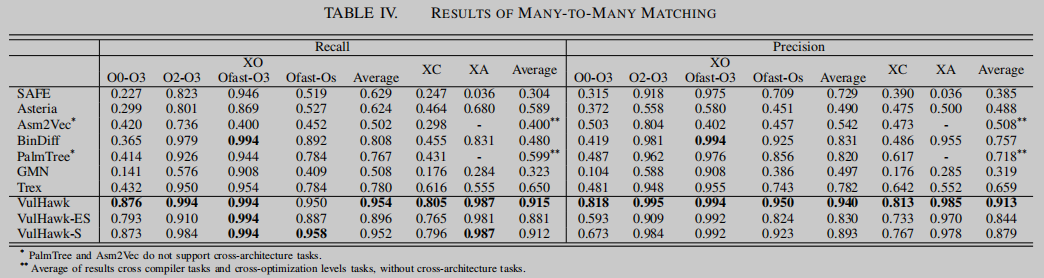
图10用小提琴图显示了XC、XA和XO任务的召回率和准确率的分布,我们在图上注释了每种方法的平均结果。与SAFE、BinDiff、Asteria、Asm2vec、PalmTree、GMN、Trex等方法相比,VulHawk的查全率和查准率概率分布更接近于1且更集中,而其他方法在不同场景下的结果分布较为分散且不稳定。这表明VulHawk的性能比其他基线更好、更稳定。
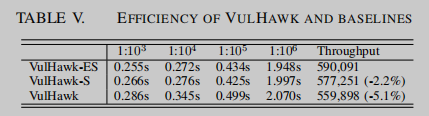
Runtime Efficiency
表V显示了在不同大小的存储库中搜索函数的时间成本及其吞吐量。结果表明,由于VulHawk在嵌入生成过程中使用了基于熵的适配器,在搜索过程中使用了相似性校准,因此VulHawk比VulHawk- es和VulHawk- s慢。
Ablation Study
Entropy-based Adapter. 如表III所示,在7个一对一的函数比较任务中,VulHawkS的AUC高于VulHawk-ES。
Similarity Calibration. 从表III和图9可以看出,VulHawk在一对一函数对比和一对多搜索场景下比VulHawk- s取得了更好的结果。
Training Tasks. 为了评估三个训练任务的贡献,还用不同的训练设置评估了VulHawk。为了更清楚地衡量训练任务的贡献,评估模型没有使用基于熵的适配器和相似性校准,仅在训练任务上有所不同。在一对一对比场景下的XC+XO+XA任务中,MLM任务训练的模型的AUC值为0.833,MLM+ROP任务训练的模型的AUC值为0.934,MLM+ROP+ABP训练的模型的AUC值为0.966。
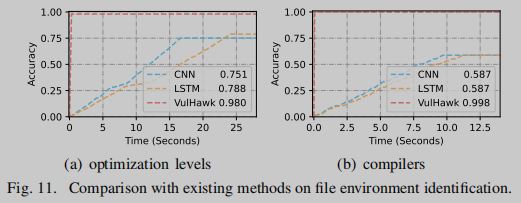
File Environment Identification
我们还评估了基于熵的文件环境识别的准确性。在这里,我们使用10折交叉验证来分割所有的二进制数据,用于训练和评估,就像传统的机器学习设置一样。这些二进制文件来自不同的体系结构(x86、arm和mips)和不同的编译器(GCC和Clang)。Pizzolotto等人[44]在函数字节上使用CNN模型和LSTM模型来识别文件环境。为了更好地展示该方法的性能,下载了他们的预训练模型,并将它们(CNN和LSTM)设置为比较。请注意,在实践中,给定二进制文件的编译器和优化级别是未知的,因此在评估一个参数(例如编译器)以确保实用性时,我们不会固定其他参数(例如,体系结构和优化级别)
1-day Vulnerability Detection from Firmware
在本实验中,我们从三个供应商(D-Link、TP-Link和NetGear)收集了20个最新的物联网固件图像,并在1天的漏洞检测任务中执行VulHawk和其他基线。选择在物联网固件中广泛使用的OpenSSL和Curl项目作为目标,基于通用漏洞与暴露(Common vulnerability and exposure, CVE)数据库构建漏洞库。库中包含12个相关cve的漏洞函数及其补丁函数,其详细信息和ground truth如表6所示,共53739个函数,其中93个为相关漏洞函数,119个为相关补丁函数。对于每个漏洞/补丁函数,使用VulHawk生成其函数嵌入并记录其细粒度特征以进行相似性校准。
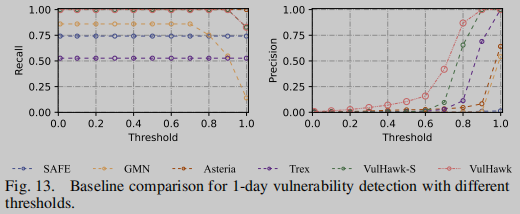
表VI给出了VulHawk和其他基线根据图13得到的最佳阈值的结果。对于12个cve, Trex的假阳性为0,但召回率为52.7%;GMN取得了86.0%的召回率,但产生了36,342个假阳性;Asteria实现了64.1%的准确率,零假阴性;而VulHawk实现了最佳性能,零误报和100%召回。
总结
References
[5] Y. David, N. Partush, and E. Yahav, “Statistical similarity of binaries,” in Proceedings of the 37th ACM SIGPLAN Conference on Programming Language Design and Implementation, 2016, pp. 266–280.
[6] Y. David, N. Partush, and E. Yahav, “Firmup: Precise static detection of common vulnerabilities in firmware,” in ACM SIGPLAN Notices, vol. 53, no. 2. ACM New York, NY, USA, 2018, pp. 392–404.
[7] Y. David and E. Yahav, “Tracelet-based code search in executables,” Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), pp. 349–360, 2014.
[9] S. H. Ding, B. C. Fung, and P. Charland, “Kam1n0: MapReduce-based Assembly Clone Search for Reverse Engineering,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining - KDD ’16. New York, New York, USA: ACM Press, 2016, pp. 461–470.
[10] S. H. Ding, B. C. Fung, and P. Charland, “Asm2vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization,” in 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 472–489.
[11] Y. Duan, X. Li, J. Wang, and H. Yin, “DeepBinDiff: Learning ProgramWide Code Representations for Binary Diffing,” in Proceedings of the 27rd Symposium on Network and Distributed System Security (NDSS), 2020.
[16] J. Gao, X. Yang, Y. Fu, Y. Jiang, and J. Sun, “Vulseeker: A semantic learning based vulnerability seeker for cross-platform binary,” ASE 2018 - Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, pp. 896–899, 2018.
[27] X. Li, Q. Yu, and H. Yin, “Palmtree: Learning an assembly language model for instruction embedding,” in Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, 2021, pp. 3236–3251.
[29] J. Lin, D. Wang, R. Chang, L. Wu, Y. Zhou, and K. Ren, “Enbindiff: Identifying data-only patches for binaries,” IEEE Transactions on Dependable and Secure Computing, no. 01, pp. 1–1, 2021.
[31] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
[33] R. Lyda and J. Hamrock, “Using entropy analysis to find encrypted and packed malware,” IEEE Security & Privacy, vol. 5, no. 2, pp. 40–45, 2007.
[34] A. Marcelli, M. Graziano, X. Ugarte-Pedrero, Y. Fratantonio, M. Mansouri, and D. Balzarotti, “How machine learning is solving the binary function similarity problem.”
[35] L. Massarelli, G. A. Di Luna, F. Petroni, R. Baldoni, and L. Querzoni, “Safe: Self-attentive function embeddings for binary similarity,” in International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment. Springer, 2019, pp. 309–329.
[41] K. Pei, Z. Xuan, J. Yang, S. Jana, and B. Ray, “Trex: Learning execution semantics from micro-traces for binary similarity,” arXiv preprint arXiv:2012.08680, 2020.
[43] J. Pewny, F. Schuster, L. Bernhard, T. Holz, and C. Rossow, “Leveraging semantic signatures for bug search in binary programs,” in Proceedings of the 30th Annual Computer Security Applications Conference, 2014, pp. 406–415.
[47] C. E. Shannon, “A mathematical theory of communication,” The Bell system technical journal, vol. 27, no. 3, pp. 379–423, 1948.
[48] P. Shirani, L. Collard, B. L. Agba, B. Lebel, M. Debbabi, L. Wang, and A. Hanna, “Binarm: Scalable and efficient detection of vulnerabilities in firmware images of intelligent electronic devices,” in International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment. Springer, 2018, pp. 114–138.
[49] Synopsys, “Open source security and risk analysis report,” https://www.synopsys.com/content/dam/synopsys/sig-assets/reports/rep-ossra-2022.pdf, 2022.
[55] X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security - CCS ’17. Dallas,TX, USA: ACM Press, 2017, pp. 363–376.
[57] J. Yang, C. Fu, X.-Y. Liu, H. Yin, and P. Zhou, “Codee: A tensor embedding scheme for binary code search,” IEEE Transactions on Software Engineering, 2021.
[58] S. Yang, L. Cheng, Y. Zeng, Z. Lang, H. Zhu, and Z. Shi, “Asteria: Deep learning-based ast-encoding for cross-platform binary code similarity detection,” in 2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). IEEE, 2021, pp. 224–236
[60] F. Zuo, X. Li, P. Young, L. Luo, Q. Zeng, and Z. Zhang, “Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs,” in Proceedings 2019 Network and Distributed System Security Symposium. Reston, VA: Internet Society, 2019.
Insights
(1) 多种特征直接链接(concatenate)为一个向量
(2) 熵流区分编译器和优化选项