baseline 复现
baseline模型
我们再这次实验中选择了deep code search方法作为了解并复现。下面介绍一下这两种方法
deep code search
模型的结构在论文中已经介绍的非常清楚了,有兴趣的同学可以仔细看一下论文:
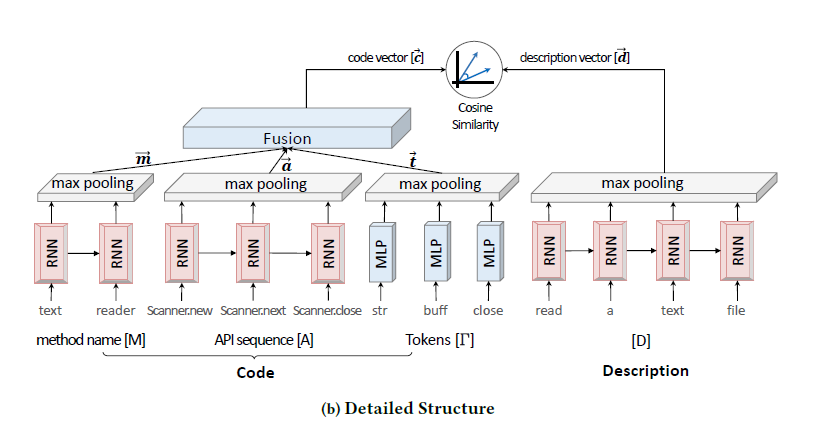
模型分为两部分
- code encoder
- description encoder
将代码和描述编码到同一线性空间
code encoder: 用于给出代码的向量表示。代码可以表示三部分方法名称,api序列和tokens。方法名称和api拥有前后关联顺序,使用word embedding + RNN+maxpooling得到。而tokens实际上不存在上下文关系,直接使用word embedding + max pooling得到。
description encoder:用于给出自然语言的向量表示,使用RNN+ pooling 表示
优缺点分析
优点: 有效的提取了代码和描述的语义特征,其中代码的特征由多个方面组成比较完备 缺点: 使用单向RNN作为特征提取有局限性,代码不像单纯的自然语言处理里用RNN就能抽取较好的特征
效果
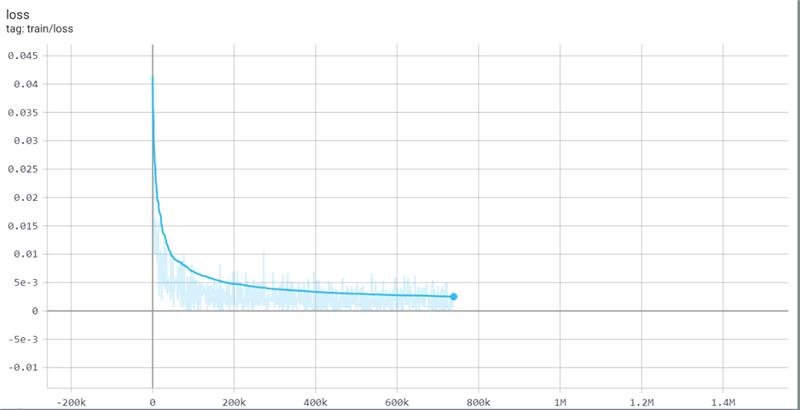
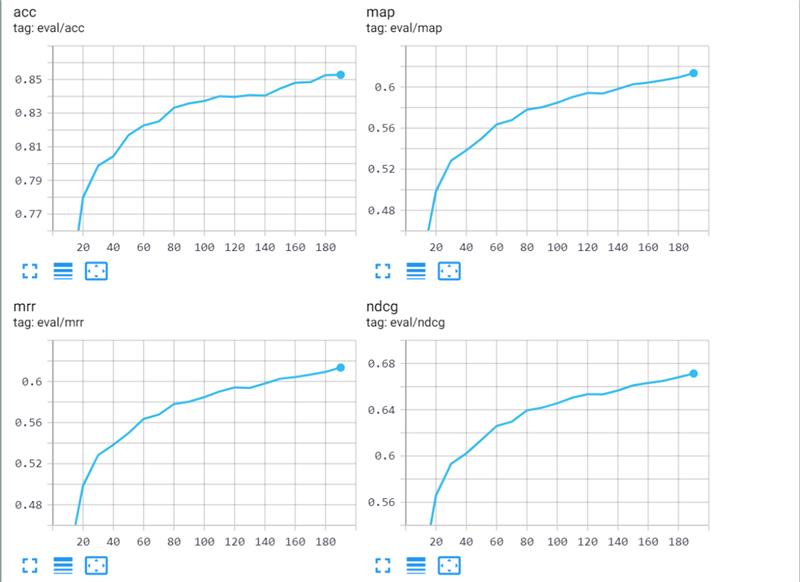
我和队友复现了CODEnn模型,具体的复现过程loss变化如下 其中衡量复现效果的四个metric的变化过程如下: 我们把batch_size设置为64,并且结合一些测试训练的结果把learning rate设置为decay的形式。最终的复现结果如下表所示,和文档里给出的最佳模型作比较在test set上性能几乎一致。
| datasets | acc@top5 | acc@top10 |
|---|---|---|
| validation set(pool=200) | 0.780680 | 0.860476 |
| validation set(pool=800) | 0.600521 | 0.704167 |
| test set(pool=200) | 0.779558 | 0.861565 |
| test set(pool=800) | 0.595174 | 0.700799 |
前端展示部分
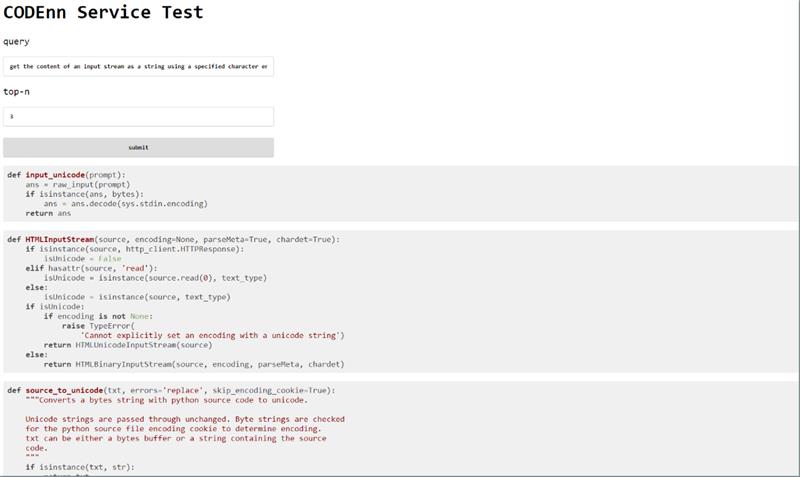
值得一提的是,我们写了点前端代码来方便演示模型的最终效果。我们拿一些例子跑了一下,有的时候返回的结果还是挺不错的,但是对于数据集里没有覆盖到的代码返回结果就很凌乱。比如论文中有一个例子,”get the content of an input stream as a string using a specified character encoding“,测试结果如下:
再比如可以测试一下简单需求”load json":

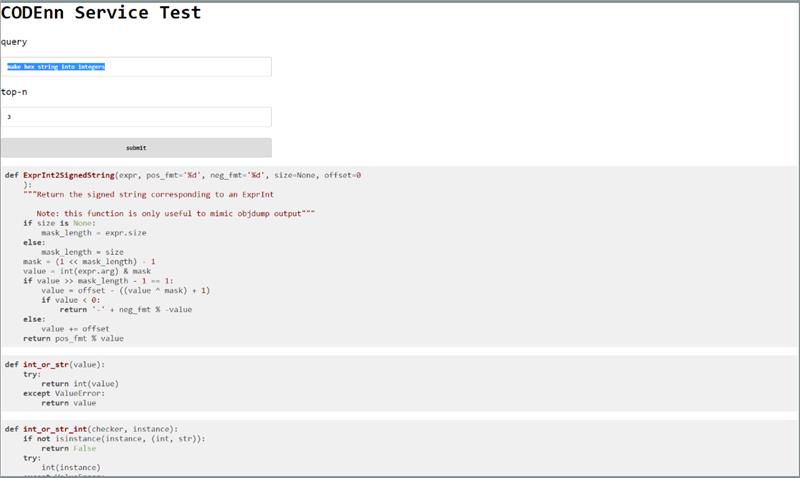
但是还是存在大量的搜索是不大ok的,比如“make hex string into integers"
提出改进方法
可以尝试将RNN替换为进来nlp领域比较常用的multi-head self-attention模型,或者multi-head self-attention。这么做有两个好处:
- RNN是串行的神经网络,这导致他在训练时的速度远远慢于别的网络结构
- multi-head self-attention 和 multi-head self-attention不仅计算速度快,而且相较于Conv1D可以更好地捕获长距离单词之间的联系
bert也可以考虑使用在description encoder部分
我注意到目前的CodeNN训练是没有使用与训练词向量的,这会导致模型的收敛速度较慢:800 epoch。可以考虑尝试用glove或者word2vec等预训练词向量,或者先在语料库上训练出自己的词向量,然后在此基础上进行finetune.
评价
我的队友是王皓,他是一个非常善于沟通且搜索能力很强的同学。在我们结对编程中,对原始数据集产生了很大疑惑的时候,王皓同学积极上网搜索,并找到了一个极为匹配这个任务的github比赛(可惜最后没时间做了)。虽然我们俩在这段时间都比较忙,但是我们依然很好的沟通和协调了各自的时间,并且合理减少了自己能力范围内的任务量。遗憾的地方是没有来得及实现我们的idea,如果能抽出时间我们很愿意做这个工作。