自适应线性神经网络Adaptive linear network, 是神经网络的入门级别网络。
相对于感知器,
- 采用了f(z)=z的激活函数,属于连续函数。
- 代价函数为LMS函数,最小均方算法,Least mean square。

实现上,采用随机梯度下降,由于更新的随机性,运行多次结果是不同的。
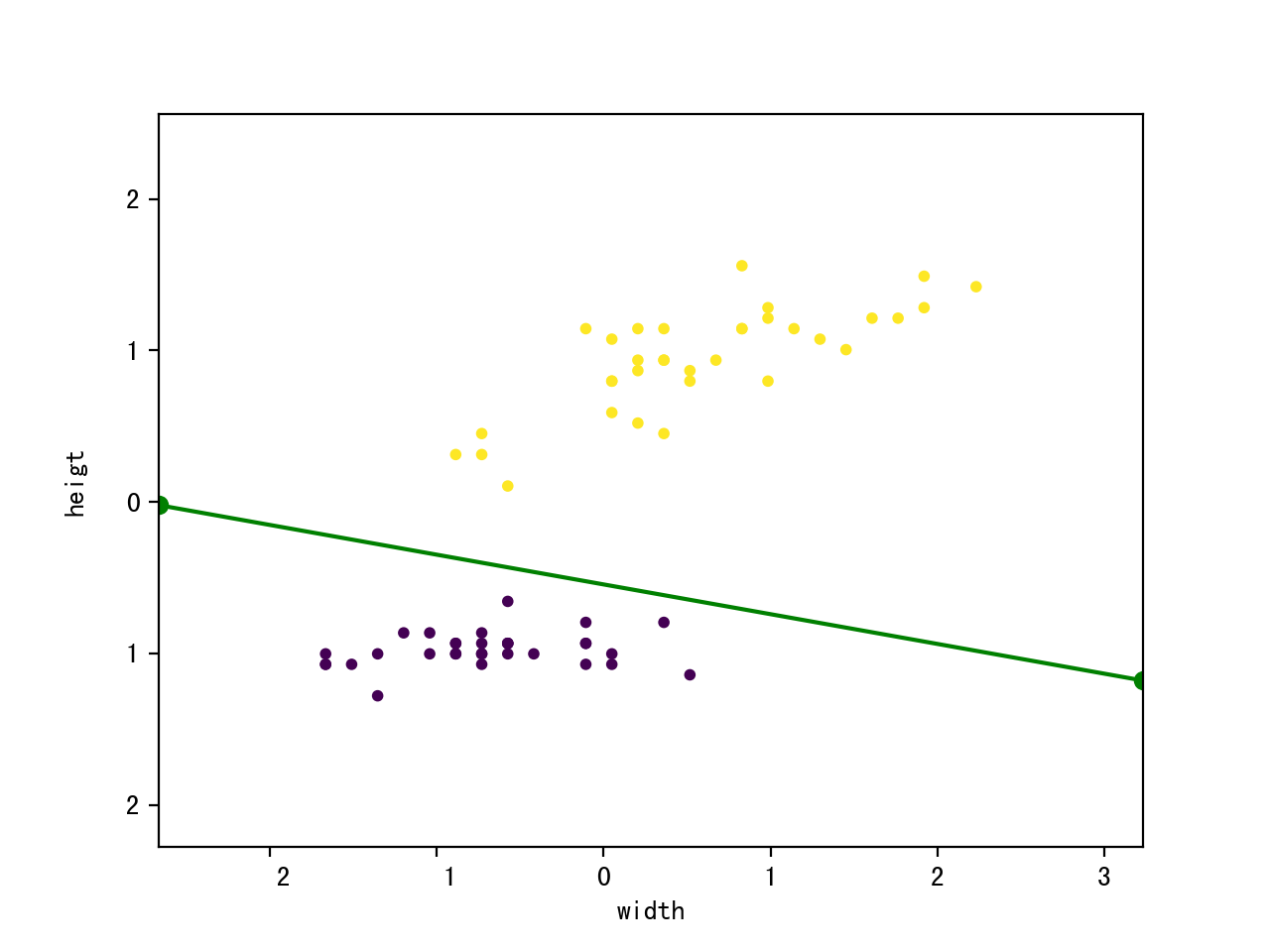
1 ''' 2 Adaline classifier 3 4 created on 2019.9.14 5 author: vince 6 ''' 7 import pandas 8 import math 9 import numpy 10 import logging 11 import random 12 import matplotlib.pyplot as plt 13 14 from sklearn.datasets import load_iris 15 from sklearn.model_selection import train_test_split 16 from sklearn.metrics import accuracy_score 17 18 ''' 19 Adaline classifier 20 21 Attributes 22 w: ld-array = weights after training 23 l: list = number of misclassification during each iteration 24 ''' 25 class Adaline: 26 def __init__(self, eta = 0.001, iter_num = 500, batch_size = 1): 27 ''' 28 eta: float = learning rate (between 0.0 and 1.0). 29 iter_num: int = iteration over the training dataset. 30 batch_size: int = gradient descent batch number, 31 if batch_size == 1, used SGD; 32 if batch_size == 0, use BGD; 33 else MBGD; 34 ''' 35 36 self.eta = eta; 37 self.iter_num = iter_num; 38 self.batch_size = batch_size; 39 40 def train(self, X, Y): 41 ''' 42 train training data. 43 X:{array-like}, shape=[n_samples, n_features] = Training vectors, 44 where n_samples is the number of training samples and 45 n_features is the number of features. 46 Y:{array-like}, share=[n_samples] = traget values. 47 ''' 48 self.w = numpy.zeros(1 + X.shape[1]); 49 self.l = numpy.zeros(self.iter_num); 50 for iter_index in range(self.iter_num): 51 for rand_time in range(X.shape[0]): 52 sample_index = random.randint(0, X.shape[0] - 1); 53 if (self.activation(X[sample_index]) == Y[sample_index]): 54 continue; 55 output = self.net_input(X[sample_index]); 56 errors = Y[sample_index] - output; 57 self.w[0] += self.eta * errors; 58 self.w[1:] += self.eta * numpy.dot(errors, X[sample_index]); 59 break; 60 for sample_index in range(X.shape[0]): 61 self.l[iter_index] += (Y[sample_index] - self.net_input(X[sample_index])) ** 2 * 0.5; 62 logging.info("iter %s: w0(%s), w1(%s), w2(%s), l(%s)" % 63 (iter_index, self.w[0], self.w[1], self.w[2], self.l[iter_index])); 64 if iter_index > 1 and math.fabs(self.l[iter_index - 1] - self.l[iter_index]) < 0.0001: 65 break; 66 67 def activation(self, x): 68 return numpy.where(self.net_input(x) >= 0.0 , 1 , -1); 69 70 def net_input(self, x): 71 return numpy.dot(x, self.w[1:]) + self.w[0]; 72 73 def predict(self, x): 74 return self.activation(x); 75 76 def main(): 77 logging.basicConfig(level = logging.INFO, 78 format = '%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', 79 datefmt = '%a, %d %b %Y %H:%M:%S'); 80 81 iris = load_iris(); 82 83 features = iris.data[:99, [0, 2]]; 84 # normalization 85 features_std = numpy.copy(features); 86 for i in range(features.shape[1]): 87 features_std[:, i] = (features_std[:, i] - features[:, i].mean()) / features[:, i].std(); 88 89 labels = numpy.where(iris.target[:99] == 0, -1, 1); 90 91 # 2/3 data from training, 1/3 data for testing 92 train_features, test_features, train_labels, test_labels = train_test_split( 93 features_std, labels, test_size = 0.33, random_state = 23323); 94 95 logging.info("train set shape:%s" % (str(train_features.shape))); 96 97 classifier = Adaline(); 98 99 classifier.train(train_features, train_labels); 100 101 test_predict = numpy.array([]); 102 for feature in test_features: 103 predict_label = classifier.predict(feature); 104 test_predict = numpy.append(test_predict, predict_label); 105 106 score = accuracy_score(test_labels, test_predict); 107 logging.info("The accruacy score is: %s "% (str(score))); 108 109 #plot 110 x_min, x_max = train_features[:, 0].min() - 1, train_features[:, 0].max() + 1; 111 y_min, y_max = train_features[:, 1].min() - 1, train_features[:, 1].max() + 1; 112 plt.xlim(x_min, x_max); 113 plt.ylim(y_min, y_max); 114 plt.xlabel("width"); 115 plt.ylabel("heigt"); 116 117 plt.scatter(train_features[:, 0], train_features[:, 1], c = train_labels, marker = 'o', s = 10); 118 119 k = - classifier.w[1] / classifier.w[2]; 120 d = - classifier.w[0] / classifier.w[2]; 121 122 plt.plot([x_min, x_max], [k * x_min + d, k * x_max + d], "go-"); 123 124 plt.show(); 125 126 127 if __name__ == "__main__": 128 main();