本文出自论文 Designing Adaptive Neural Networks for Energy-Constrained Image Classification,主要介绍了一个有效的超参数优化方法,来设计硬件约束的自适应CNNs。
现有方法的主要限制是它们只学习数据如何在CNNs中被处理而不是网络架构,其中每个网络都被看作一个黑盒。因此,我们将自适应CNNs的设计作为一个超参数优化问题,并将运行在移动设备上的能量、精度和通信约束考虑在内。为了有效解决这个问题,我们应用贝叶斯优化到设计空间的性质中,在几十次函数评估中达到接近的最优配置。我们的方法对于移动设备上的图像分类任务,与先前最好的方法相比减少能耗到6倍。最终,我们评估了两种图像分类实践,在能量和通信约束下对本地和云上的所有图像进行分类。
一、简介
- 本文中,我们做了以下观察:如果每个私有网络的架构都可以被网络选择方案来优化,自适应CNNs获得的最小能量可以被显著地减少。我们的关键点是将每个网络体系架构的选择(隐藏单元的数量、特征映射的数量等)看作超参数,而目前还没有一种全局的、系统的自适应CNNs的硬件约束的超参数优化方法,它基于一个真实移动平台上的硬件测量。
- 本文主要贡献:(1)全局优化的自适应CNNs,我们首次在运行于移动平台的硬件约束下,优化适用于网络架构和网络选择方案的自适应CNNs系统。(2)自适应CNNs作为超参数问题,将自适应CNNs的设计问题公式化一个超参数优化问题。(3)用于设计自适应CNNs的贝叶斯优化增强,利用移动设计空间的特性。(4)深刻的设计空间探索,利用我们方法的有效性作为设计空间探索的有用辅助。
二、相关工作
- 自适应CNN执行:由于简单的例子并不需要计算复杂性和一个巨大的整体的CNN的开销,这激励了有着不同级别的精度和复杂性的自适应CNNs的使用。最近的工作展示出在网络级别的自适应执行胜过层级别的执行,因此我们侧重于网络级别的设计,而我们的方法是通用的,能够被灵活地应用于layer-wise的情形中。我们的工作是第一个把自适应CNNs的设计问题转换成超参数优化问题,并增强一个贝叶斯优化方法来有效解决它,于是有效地设计了CNN体系架构和它们之间的选择函数。
- 以剪枝和量化为基础的节能CNNs:对于解决基于CNN参数减少的能效问题,第一个方法是基于剪枝的方法来减少网络连接,第二个方法是通过量化网络权重来直接减少计算复杂度。我们集中于自适应CNN结构来进行全局优化和确定不同CNNs的大小,现有的方法是互补的,并当给定使用我们方法确定的全局最优seed时,可以用于进一步降低计算成本。
- 超参数优化:贝叶斯优化对于CNNs上的体系架构搜索是有效的,并且它已经被成功用于硬件加速器和NNs(运行时间和功耗限制)的共同设计中。我们部署贝叶斯优化来确定CNNs的输入图像间的流动和它们的大小(过滤器数量、核大小等)。因为我们的目标应用程序是移动和嵌入式设计空间,我们部署贝叶斯优化,其中所有的网络架构基于实际的硬件测量,都是针对商业移动平台进行采样和优化的。我们的工作是第一个对于通信和计算能耗来考虑贝叶斯优化的。
三、背景
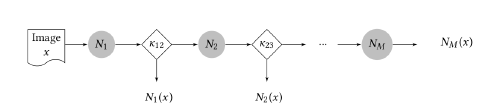
- 自适应神经网络:给定一个要被分类的图像,神经网络
总是要被首先执行,接下来一个决策函数
被评估来决定从
执行后的分类结果应当被返回作为最终结果,或者到下一个网络
来被执行。一般来说,我们将决策函数
表示为:
,从而来提供置信度反馈,以及决定在状态
退出或者在接下来的阶段
继续执行。
.
- 网络选择问题:自适应CNNs可以被看作一个优化问题,网络选择问题的目标是去选择一个函数 ,优化每张图像的推理成本,同时限制总体精度的下降。对于一个双网络情况,我们可以定义其优化公式为: 。在优化公式中,代价函数仅在决策函数的参数上进行优化,而不是单个网络的参数。对于决策函数 的选择,我们可以定义其为score margin(SM),表示在网络 的输出结果向量中最大值和第二个最大值之间的距离。CNN对其预测结果越自信,所预测的输出结果值越大,SM的值也越大。
- 网络设计问题:我们定义一个CNN的设计空间 ,此神经网络的超参数元素被表示为 。在一个不同网络架构中不同 值的选择,会导致损失函数 和计算效率 的变化。对于一个简单的网络,超参数优化问题可以被表示为: 。
- 工作关键要素:一方面,网络选择问题假定CNNs的架构被固定好,并且网络已经可以得到和预先训练好,其优化问题仅需要解决决策函数 。另一方面,网络设计问题假定只有一个单一的CNN并不能直接应用于自适应CNNs。
四、提出方法
-
超参数优化:(1)能量最小化:最小化每个图像的平均能量消耗(受制于最大精度下降),我们将执行神经网络 对一个输入图像 分类的能量消耗定义为 。其总体能量和精度明确依赖于基于各自超参数值的网络架构 ,一个超优化处理允许我们直接合并 值作为超参数,从而与网络的规模来共同优化。
(2)不同设计范例的考虑:第一种是所有网络都本地化处理的情况,用公式表示为: ;另外一种是图像集的一部分通过网络发送到服务器,其结果被反馈回来,这里能耗是来自于客户端节点的功耗输出,总运行时间则为发送图像和接收结果所花费时间,用公式表示为: 。
(3)能量约束优化:我们也可以考虑最小化分类误差,同时不超过每张图像的最大能量 。这种设计方案对于被移动硬件工程师所施加的能量预算下的图像分类具有显著的影响效果。
-
使用贝叶斯优化:为了获得总体精度,所有的网络需要被训练,因此一个优化算法的每个步骤都需要花数小时时间去完成。为了支持能量可知超参数优化,我们在这个设计空间中使用了贝叶斯优化。在每个阶段d,贝叶斯优化在候选点 和记录观察 查询目标函数 和受限函数 ,从而获得一个三元组 。在自适应神经网络系统中,这对应于每个网络 的能量、运行时间和功耗的分析,从而获得图像数据集上的预期能耗和精度。通常来说,贝叶斯优化由三个阶段组成:第一是基于d-1个数据点集合的概率模型M;第二是概率模型M被用来计算一个采集函数 ,在随机点量化目标函数的预测提升;第三是在点 时 和 被评估,是采集函数的当前可行优化器。

-
决策函数 的微调好处:(1)在贝叶斯优化的早期阶段,更多的数据被填充到观察历史 中,从而提升了贝叶斯优化的收敛性;(2)在贝叶斯优化的后期阶段, -based优化被作为附近最优区域的微调。我们的方法结合了贝叶斯优化方法固有的设计空间探索特性,且优化的探索范围仅在 函数周边。
五、实验设置
- 为了与现有技术有一个代表性的比较,我们考虑了一个双网络系统,其中CaffeNet作为 ,VGG-19作为 。对于一个三网络情形,我们考虑了LeNet,CaffeNet和VGG-19来作为 。为了不失一般性,我们应用了超参数优化方法,并学习了CaffeNet网络架构,而不改变LeNet或者VGG-19网络。对于卷积层,我们改变了特征映射的数量和核大小,对于全连接层则为单元数量。
- 我们考虑了自适应图像分类的下面测试情况:(1)所有的CNNs在移动系统上本地执行,我们将其表示为local;(2)较少复杂的网络被部署在移动系统(边缘节点),而更精确的网络在一个服务器上执行(远程执行)。对于每个图像例子,决策函数选择使用本地预测,或者将图像传输到服务器,然后接收更复杂网络的结果。我们计算通信时间为传输图片和接收到分类的结果所占用的时间。
六、实验结果
- 自适应CNNs作为超参数优化问题:(1)与仅优化决策函数的现有工作方法相比,贝叶斯优化下的精度和能量之间的权衡更加完善,它将自适应CNN系统设计看作一个超参数问题,并对网络结构进行了全局优化。(2)贝叶斯优化所考虑的配置在普通优化设计前面,展示了我们的方法在能耗方面的显著减少。(3)我们的方法在确定灵活的、邻近最优的区域具有一定的有效性。
- 贝叶斯优化有效性评估:在edge-server设计误差约束下对最小能量进行贝叶斯优化,这个方法有效地评估设计接近于Pareto front。从实验结果图中我们可以看出,邻近最优区域在22个函数评估中被达到。另外,我们注意到微调步骤允许优化在较少的函数评估中去选择邻近最优区域的配置。


- 综合的自适应CNNs评估:我们报告了验证误差,因为这个度量是评估贝叶斯优化结果的标准方法。我们也报告了最优的和灵活的解决方案的测试误差。基于这些结果,我们可以有以下几个发现:(1)先前工作的次优性;(2)所提方法的有效性:我们发现在所有考虑的情况中,所提出的
方法紧密地匹配网格搜索所确认的结果;(3)使用
-based 微调的性能增强:我们在贝叶斯优化中引入的微调步骤是有益的,特别是在过度约束的情况下,可以允许优化更快地确认邻近最优区域;(4)本地和远程执行:在相同级别的精度上本地执行任何事相比较,我们发现远程执行一些包含自适应神经网络的CNNs可以实现更高效的图像分类。(5)我们发现三网络的案例要比使用双网络低能效,这可能因为更多网络的自适应设计更适合于多计算密集型应用。

- 层次结构探索:最终我们在一个三网络的案例中对所提出的方法进行评估。我们发现,与静态方法相比,我们的方法与网格搜索的结果非常吻合。更特别地,在能量最小化情况中,
所实现的解决方案与基于网格搜索的最优设计只有4.74%的差距,同时在能量最小化方面远胜于先前提出的静态方法。

七、结论
- 本文我们介绍了一个有效的超参数优化方法,来设计硬件约束的自适应CNNs。我们所做工作的关键点是CNNs体系架构设置和网络选择问题被看作超参数来进行全局优化。为了有效解决这个问题,我们增强了贝叶斯优化到设计空间的特性中,我们的方法被看作 ,与一个硬件无关的BO相比,更快地到达接近最优的区域,并且最优设计通过网格搜索被确定。
- 我们利用所提方法的有效性来考虑不同自适应CNN设计,包括能量、精度、通信权衡和移动设备施加的约束。我们的方法确定了该设计优于先前提出的将CNNs看作黑盒子的方案,在精度限制下每个图像处理的最小能量降低了6倍,在能量约束下误差最小化可达31.13%。最终,我们研究了两个图像分类实践,在能量和通信约束下在本地和云端分类所有图像。
