https://www.leiphone.com/news/201709/8tDpwklrKubaecTa.html
https://www.cnblogs.com/hellojamest/p/11128799.html
https://blog.csdn.net/longxinchen_ml/article/details/86533005
一. 前提:
RNN : 解决INPUT是序列化的问题,但是RNN存在的缺陷是难以并行化处理.
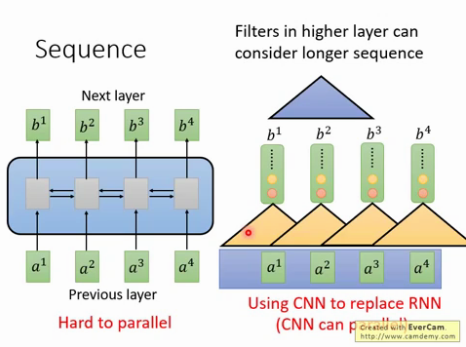
CNN : 使用CNN来replaceRNN,可以并行,如下图每个黄色三角形都可以并行. 但是问题是难解决长依赖的序列, 解决办法是叠加多层的CNN,比如下图的CNN黄色三角形和蓝色三角形为两层CNN,
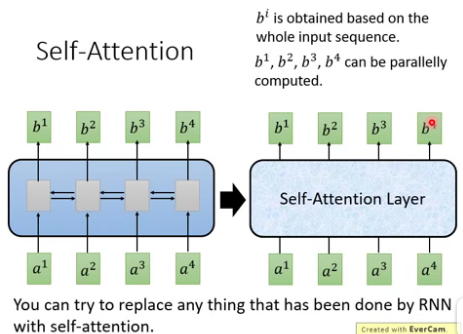
self-attention : 其输入和输出和RNN一样,就是中间不一样. 如下图, b1到b4是同时计算出来, RNN的b4必须要等到b1计算完.
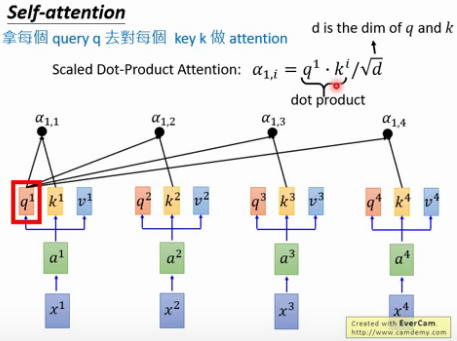
二. self-attention计算(Attention is all you need)

用每个query q去对每个key k做attention , 即计算得到α1,1 , α1,2 ……,
为什么要除以d [d等于q或k的维度,两者维度一样] ? 因为q和k的维度越大,dot product 之后值会更大,为了平衡值,相当于归一化这个值,除以一个d.

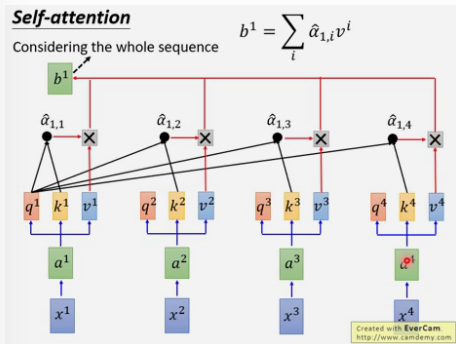
三. self-attention如何并行

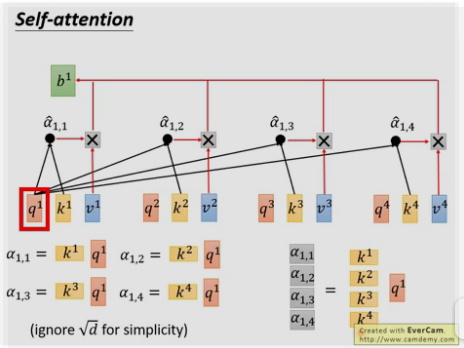
以上每个α都可以并行计算

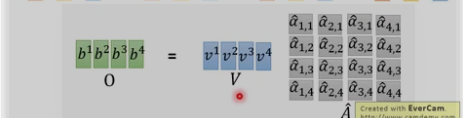
总结:
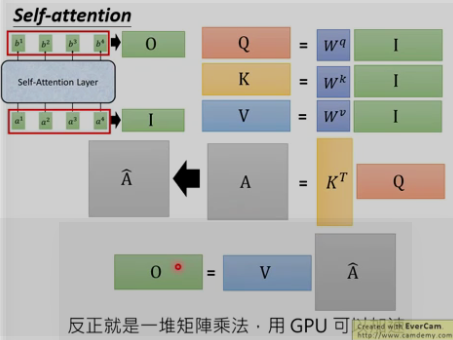
四. self_attention的类型
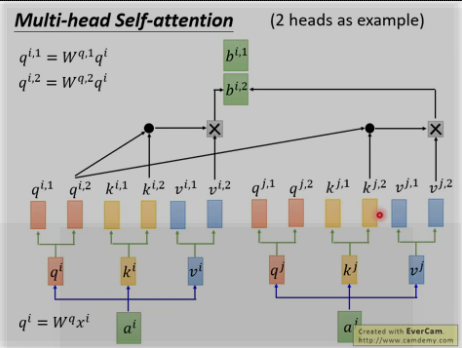
多头: 为何?因为不同的head可以关注不同的信息, 比如第一个head关注长时间的信息,第二个head关注短时间的信息.
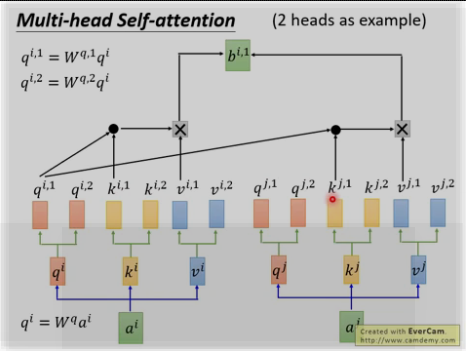
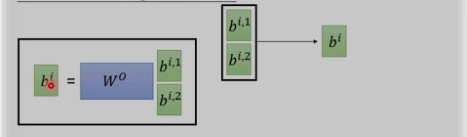
将两个bi,1和bi,2进行concat并乘以W0来降为成bi
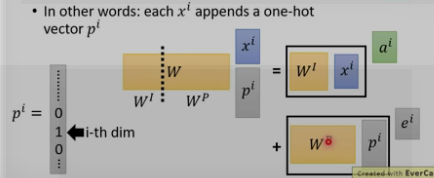
位置encoding
上面的self-attention有个问题,q缺乏位置信息,因为近邻和长远的输入是同等的计算α.
位置encoding的ei是人工设置的,不是学习的.将其加入ai中.

为何是和ai相加,而不是concat?
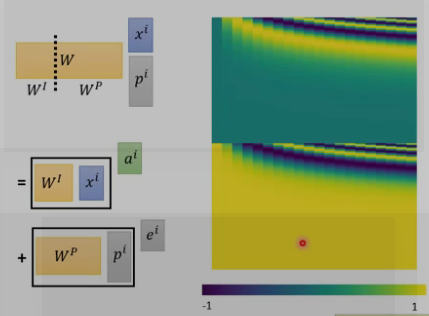
这里的Wp是通过别的方法计算的,如下图所示
五. seq2seq
传统的seq2seq: 中间用的是RNN
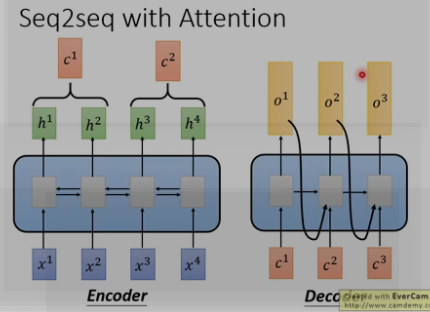
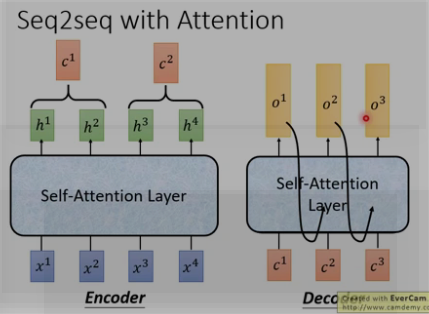
seq2seq with attention
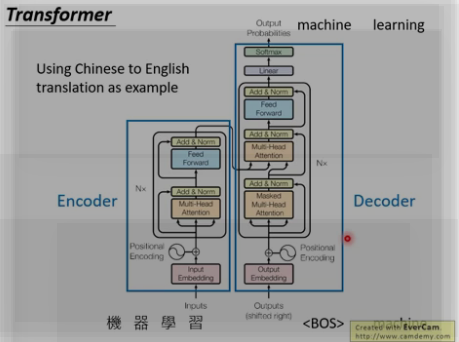
六. Transformer
https://mp.weixin.qq.com/s/RLxWevVWHXgX-UcoxDS70w
整体架构:
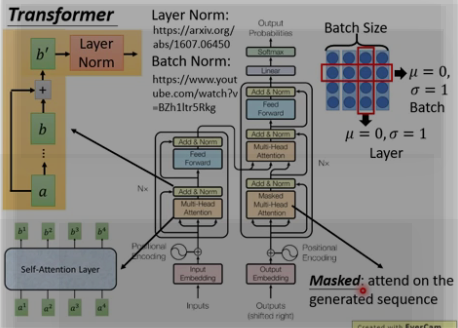
残差
对于每个encoder里面的每个sub-layer,它们都有一个残差的连接,
Layer Norm
每个sub-layer后面还有一步 layer-normalization [layer Norm一般和RNN相接] 。
Batch Norm和Layer Norm 的区别, 下图右上角, 横向为batch size取均值为0, sigma = 1. 纵向 为layer Norm , 不需要batch size.
Masked : [decoder]
注意encoder里面是叫self-attention,decoder里面是叫masked self-attention。
这里的masked就是要在做language modelling(或者像翻译)的时候,不给模型看到未来的信息。

mask就是沿着对角线把灰色的区域用0覆盖掉,不给模型看到未来的信息。
发展: universal transformer
应用: NLP \ self attention GAN (用在图像上)