题解 luogu P5021 【赛道修建】
时间:2019.8.9 20:40
时间:2019.8.12
题目描述
C 城将要举办一系列的赛车比赛。在比赛前,需要在城内修建 \(m\) 条赛道。
C 城一共有 \(n\) 个路口,这些路口编号为 \(1,2,\dots,n\),有 \(n-1\) 条适合于修建赛道的双向通行的道路,每条道路连接着两个路口。其中,第 \(i\) 条道路连接的两个路口编号为 \(a_i\) 和 \(b_i\),该道路的长度为 \(l_i\)。借助这 \(n-1\) 条道路,从任何一个路口出发都能到达其他所有的路口。
一条赛道是一组互不相同的道路 \(e_1,e_2,\dots,e_k\),满足可以从某个路口出发,依次经过 道路 \(e_1,e_2,\dots,e_k\)(每条道路经过一次,不允许调头)到达另一个路口。一条赛道的长度等于经过的各道路的长度之和。为保证安全,要求每条道路至多被一条赛道经过。
目前赛道修建的方案尚未确定。你的任务是设计一种赛道修建的方案,使得修建的 \(m\) 条赛道中长度最小的赛道长度最大(即 \(m\) 条赛道中最短赛道的长度尽可能大)
题意分析
给出一棵 \(n\) 个点的树,并在其中选取 \(m\) 条边不相交的路径,使得最短路径(赛道)的长度尽可能大。
分析
最短路径的长度尽可能大,即要求最大化最小值。显然可以考虑二分。
考虑二分转换为判定问题:二分枚举 \(limit\),能否选出 \(m\) 条长度不小于 \(limit\) 的路径?
不妨尽可能多地选择长度不小于 \(limit\) 的路径,判断选择的最大数量是否大于等于 \(m\)。
于是,我们的问题进一步被转换为:给出 \(limit\),求出不小于 \(limit\) 的路径最多有多少条。
贪心策略
先给出一个定义:从 \(u\) 子树中某个节点连向 \(u\) 的一条路径称为“半链”(借鉴了 @XG_Zepto 的定义)
下面是一个半链的例子。我们发现,两条长度之和大于等于 \(limit\) 的未使用的半链(红色)可以合并在一起对答案造成贡献。
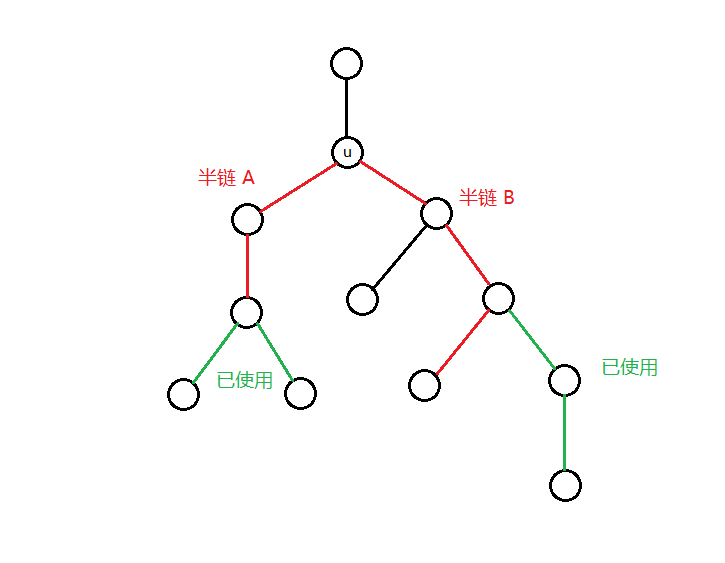
如图,A 和 B 分别是两条未被使用过的半链。如果 A 与 B 的总长可以达到 \(limit\),则将它们合并,对答案就造成了贡献。
我们很容易想到:每次合并时尽量让两条半链总长接近 \(limit\),此时才能更优。换句话说,让合法的总长尽量小更优。
另外,如果 \(v\) 是 \(u\) 的儿子,如果 \(v\) 的子树中有两条半链可以合并,那么就不要将其中某一条(再加上 \(u, v\) 距离后)留到 \(u\) 处合并。
这是因为一条半链对答案最多造成 \(1\) 的贡献,而且 \(v\) 只能留出一条返回给 \(u\),这样做答案并不会更优。换句话说,能在子树中合并就尽量在子树中合并。
有了这两个贪心策略后,我们考虑递归遍历整棵树。访问到 \(u\) 号节点时,我们先将 \(u\) 的儿子们的子树中,能够合并的半链尽量合并,并将合并的数量累加到答案中。从某个儿子返回时,无非就两种情况:
- 该儿子子树中的半链不能两两配对合并。要么剩余的半链长度太小,要么数量不够(是奇数)。
- 子树中的半链已经两两配对了,没有剩余的半链。
相应的解决方案如下:
- 在剩余的半链中选择一条最长的半链,将其长度加上 \(u, v\) 距离后返回。(一个儿子最多返回一条半链)
- 直接返回 \(u, v\) 距离。
事实上,我们并不需要知道半链的始末节点。我们只需要知道半链的长度就行了(反正肯定可以合并的嘛)。
合并方法
说了这么多,具体应该怎么做呢?
如果我们访问到了 \(u\) 号节点,先将 \(u\) 的所有儿子递归遍历。每个儿子都会返回一条半链的长度。我们将这些长度统统存进一个 vector 里。
然后对这些数据合并。合并方法是每次找到两个总和不小于 \(limit\) 的数据,将答案累加 \(1\),并将这两个数据删除。
我们既要保证不会漏掉一些合法的合并方案,又要尽可能地使最终返回的半链长度尽量长。首先是从小到大匹配(不会使答案更差,而且还避免最大的半链第一个被删除)。也许你会想到排序并使用双指针法(two-pointers),遗憾的是,双指针法会漏掉一些情况。
为什么?参考下面的一个样例。我们先假设双指针法从小到大合并吧,也就是代码可能长这个样子(减少了一些特判):
// vector<int> v; n = v.size();
sort(v.begin(), v.end()); // 从小到大排序
int cur = n - 1;
for (int i = 0; i < n; i++) {
if (used[i]) continue;
while (used[cur] && v[i] + v[cur - 1] >= limit)
cur--;
if (v[i] + v[cur] >= limit) {
ans++;
used[i] = used[cur] = true;
}
if (i + 1 == cur) break;
}为了使合并的总长尽可能小,当 v[i] + v[cur - 1] >= limit 时不断将 cur--。看上去好像并没有什么问题,每个半链 \(i\) 一定会找到与之匹配的最小半链 \(cur\)。这份代码甚至还过了样例。我们看看这样一组数据:
v: 1 2 3 3 3 4
limit = 5很简单,是吧?如果使用双指针,会发生什么呢?
1和4配对,cur--2和3配对,因为2和每个3都可以配对,根据我们的算法,我们让2和最左边的3配对。- 好了,这个时候,\(i\) 指向
2,而 \(cur\) 指向最左边的3,因为 \(i\) 和 \(cur\) 相撞,因此退出循环,并返回剩下数字中的最大值3
发现什么问题了吗?指针移动的时候跳过了 3 和 3 这两个原本能够合并的数据。解决方案?将 \(cur\) 移到末尾?让 2 和最右边的 3 配对?从大到小配对?很可惜,都不行。可以轻易地构造 Hack 数据。双指针的问题就在于跳过了的数字没法找回来。
使用平衡树 / multiset
再回顾一下我们的任务:每次找到两个总和不小于 \(limit\) 的数据,将答案累加 \(1\),并将这两个数据删除。
使用平衡树就行了嘛!不断遍历最小的数据 \(x\),然后在平衡树中找到第一个比 \((limit - x)\) 大的数 \(y\),将答案累加 \(1\),最后将 \(x\) 和 \(y\) 删除,直到平衡树大小不超过 \(1\) 为止。
当然,我们也没必要手写一个平衡树。STL 里的 multiset 足以解决这个问题。
multiset::lower_bound(x) 返回第一个大于等于 \(x\) 的数 \(y\)(的迭代器)。如果你不知道迭代器是什么,你可以把它理解成一个更高明的指针(滑稽)。*iter 的语法同样适用于迭代器。
好了,下面这份代码可以取代上面那份双指针的代码了。
// multiset<int> son[u]
while (!son[u].empty()) {
LL x = *(son[u].begin());
son[u].erase(son[u].begin());
Iter iter = son[u].lower_bound(limit - x);
if (iter == son[u].end()) {
ans.val = max(ans.val, x);
} else {
ans.cnt++;
son[u].erase(iter);
}
}这里就是查找并删除的过程。注意如果 lower_bound 返回的迭代器等于 son[u].end() 则说明找不到。此时用它来更新 \(u\) 将要返回的最长半链长度。如果没有数据更新最长半链长度,则将其设成 \(0\)。加上 \(u, v\) 距离这步会在父亲中处理。
代码
注意一个小细节:如果某条半链的长度大于等于 \(limit\),则这条半链可以单独成为一条路径(不用合并)。
代码其实还挺短的 qwq。
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
typedef multiset<LL>::iterator Iter;
const int kMaxN = 50000 + 10;
struct Graph {
struct Arc {
int to;
LL dis;
};
vector<Arc> arcs[kMaxN];
void Add(int u, int v, LL dis) {
arcs[u].push_back((Arc) {v, dis});
arcs[v].push_back((Arc) {u, dis});
}
};
struct Info {
int cnt;
LL val;
};
Graph G;
int n, m;
LL limit, max_limit;
multiset<LL> son[kMaxN];
Info Dfs(int u, int fa) {
Info ans = (Info) {0, 0ll};
son[u].clear();
for (int i = 0; i < G.arcs[u].size(); i++) {
Graph::Arc& arc = G.arcs[u][i];
int v = arc.to;
if (v != fa) {
Info res = Dfs(v, u);
res.val += arc.dis;
ans.cnt += res.cnt;
if (res.val >= limit) {
ans.cnt++;
} else {
son[u].insert(res.val);
}
}
}
while (!son[u].empty()) {
LL x = *(son[u].begin());
son[u].erase(son[u].begin());
Iter iter = son[u].lower_bound(limit - x);
if (iter == son[u].end()) {
ans.val = max(ans.val, x);
} else {
ans.cnt++;
son[u].erase(iter);
}
}
return ans;
}
int main() {
scanf("%d %d", &n, &m);
for (int i = 1; i <= n - 1; i++) {
int u, v, w;
scanf("%d %d %d", &u, &v, &w);
G.Add(u, v, w);
max_limit += w;
}
LL end = 0, top = max_limit + 1;
while (end + 1 != top) {
limit = (end + top) >> 1;
int count = Dfs(1, 0).cnt;
if (count >= m) {
end = limit;
} else {
top = limit;
}
}
printf("%lld\n", end);
return 0;
}