原文地址:https://medium.com/@ageitgey/machine-learning-is-fun-part-6-how-to-do-speech-recognition-with-deep-learning-28293c162f7a
How to do Speech Recognition with Deep Learning
如何用深度学习做语音识别
Andrew Ng 说语音识别从让人恼怒的不可靠到令人难以置信的有用中间只有4%的距离,是深度学习让这一切成为可能。
机器学习的过程不总是黑盒,我们将语音记录喂给神经网络,就可以得到纯文本输出。其过程如下如所示:

但问题是,每个人发音的习惯不同,同样说‘Hello’,有人语速极快,有人说的很慢。因此建立可靠的识别模型就需要一些小技巧。
一、将声音转换成比特
我们可以记录声波,然后将其用数字形式表示,并形成二维数组。
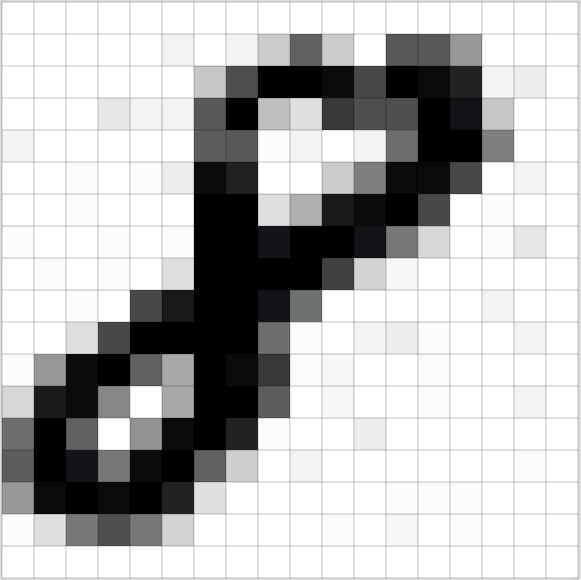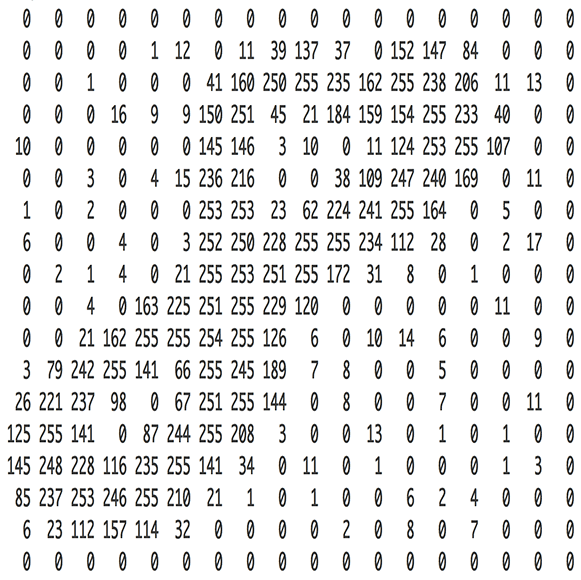
上面是最终效果。但声音被采集的原始形式是声波,比如下图就是‘Hello’的声音片段。

‘Hello’的声音片段比较复杂,先看一个简单的声音片段:
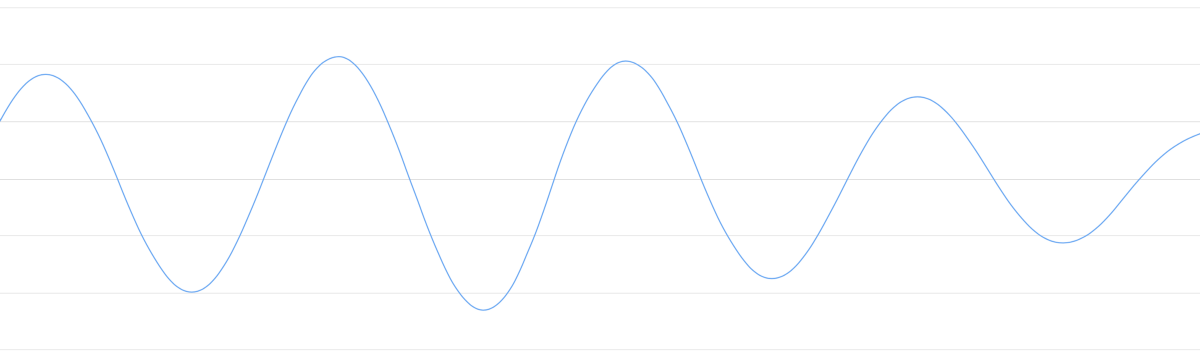
虽然声音是一维的,但加上时间属性后,我们可以将它转为二维图像:

这就是“采样”。我们对样本进行每秒千次的阅读便可以准确的记录它的数据。下图是“Hello”的前100个采样数据:

但又有一个问题,采样的数据就一定等于原数据吗?

理论上来说,只要以我们所需采集的数据最高频的两倍来采集数据,就可以完美呈现近似原音的效果。很多人以为采集数据次数越多,数据点越紧密效果越高,其实这是错误的。
二、预处理声音数据
拿到数据后,我们要对其进行预处理,这个过程会面临很多问题。比如,声音片段并不都是纯粹的标准样本,现实环境复杂多变,说话者可能是在嘈杂的环境下讲话,并且伴有严重的连读和口音,这都给语音识别增加了困难。
—— 待续 ——