由于本片论文不涉及技术,所以就翻译一下,看看公司的人是怎么理解DNN在自动驾驶中的应用的。
文章目录
A survey of deep learning techniques for autonomous driving
0、Abstract
过去十年见证了自动驾驶汽车技术的日新月异的发展,这主要得益于深度学习和人工智能(AI)领域的进步。本文的目的是调查自动驾驶中使用的最新深度学习技术。我们首先介绍基于AI的自动驾驶架构,卷积和递归神经网络,以及深度强化学习范例。这些方法为所调查的驾驶场景感知,路径规划,行为仲裁和运动控制算法奠定了基础。我们研究了使用深度学习方法构建的每个模块的模块化感知计划行动管道以及将传感信息直接映射到转向命令的End2End系统,此外,我们还解决了在设计用于自动驾驶的AI架构时遇到的挑战,例如其安全性,训练数据和计算硬件。本次调查中进行的比较有助于深入了解深度学习和自动驾驶AI方法的优势和局限性,并协助设计选择。
1、Introduction
在过去的十年中,深度学习和人工智慧(AI)成为计算机视觉(Krizhevsky,Sutskever和&Hinton,2012),机器人技术(Andrychowicz等人,2018)和自然语言取得许多突破的主要技术。处理(NLP; Goldberg,2017)。它们也对当今在学术界和工业界看到的自动驾驶革命产生了重大影响。无人驾驶汽车(AVs)和自动驾驶汽车开始从实验室开发和测试条件迁移到在公共道路上驾驶。将它们部署在我们的环境景观中,可以减少交通事故和交通拥堵,并改善我们在拥挤的城市中的出行能力。“自动驾驶”的标题似乎是不言而喻的,但实际上用于定义自动驾驶的汽车软件(SAE)级别有五个安全性。SAE J3016标准(SAE委员会,2014年)引入了从0到5的等级来对车辆自动化进行评级。较低的SAE等级具有基本的驾驶员辅助功能,而较高的SAE等级则朝着不需要任何人机交互的车辆发展。5级类别的汽车不需要人工输入,通常甚至都没有方向盘或脚踏板。
尽管大多数驾驶场景可以通过经典的感知,路径规划和运动控制方法来相对简单地解决,但其余未解决的场景是传统方法失败的极端情况。
恩斯特·迪克曼斯(Dickmanns&Graefe,1988)在1980年代开发了第一批自动驾驶汽车。这为例如PROMETHEUS,旨在开发功能齐全的自动驾驶汽车的研究项目铺平了道路。1994年,无人驾驶和自动驾驶汽车(VaMP)成功行驶了1,600公里,其中95%是自动驾驶。同样,1995年,卡内基·梅隆导航实验室(CMU NAVLAB)演示了在6,000公里处自动驾驶的情况,其中98%是自动驾驶。自动驾驶的另一个重要里程碑是2004年和2005年美国国防高级研究计划局(DARPA)的大挑战,以及这是2007年DARPA城市挑战赛的目标。无人驾驶汽车的目标是在没有人工干预的情况下,尽可能快地在越野道路上行驶。2004年,这15辆车中没有一辆完成比赛。2005年比赛的冠军斯坦利(Stanley)利用MachineLearning技术在非结构化环境中导航。这是无人驾驶汽车开发的转折点,承认机器学习和人工智能是自动驾驶的核心组成部分。该转折点在本调查报告中也很明显,因为大部分被调查的工作都定于2005年之后。
在这项调查中,我们回顾了自动驾驶中使用的不同AI和深度学习技术,并提供了适用于自动驾驶汽车的最新深度学习和AI方法的调查。我们还将专门讨论安全方面的内容,培训数据源的挑战以及所需的计算硬件。
2、在自驾车中使用基于深度学习的决策架构
自动驾驶汽车是自主决策系统,可处理来自不同车载系统的观察流,例如相机,雷达,光检测和测距(LiDAR),超声传感器,全球定位系统(GPS)单位和/或惯性传感器。这些观察结果被汽车的计算机用来做出驾驶决策。图1显示了AI动力自动驾驶汽车的基本框图。驾驶决策可以通过模块化的感知计划行动管线(图1a)或End2End学习方式(图1b)进行计算,其中感官信息直接映射到控制输出。可以基于AI和深度学习方法或使用经典的非学习方法来设计模块化管道的组件。可以对基于学习和非学习的组件进行各种排列(例如,基于深度学习的对象检测器为经典的A-star路径规划算法提供输入)。安全监控器旨在确保每个模块的安全。
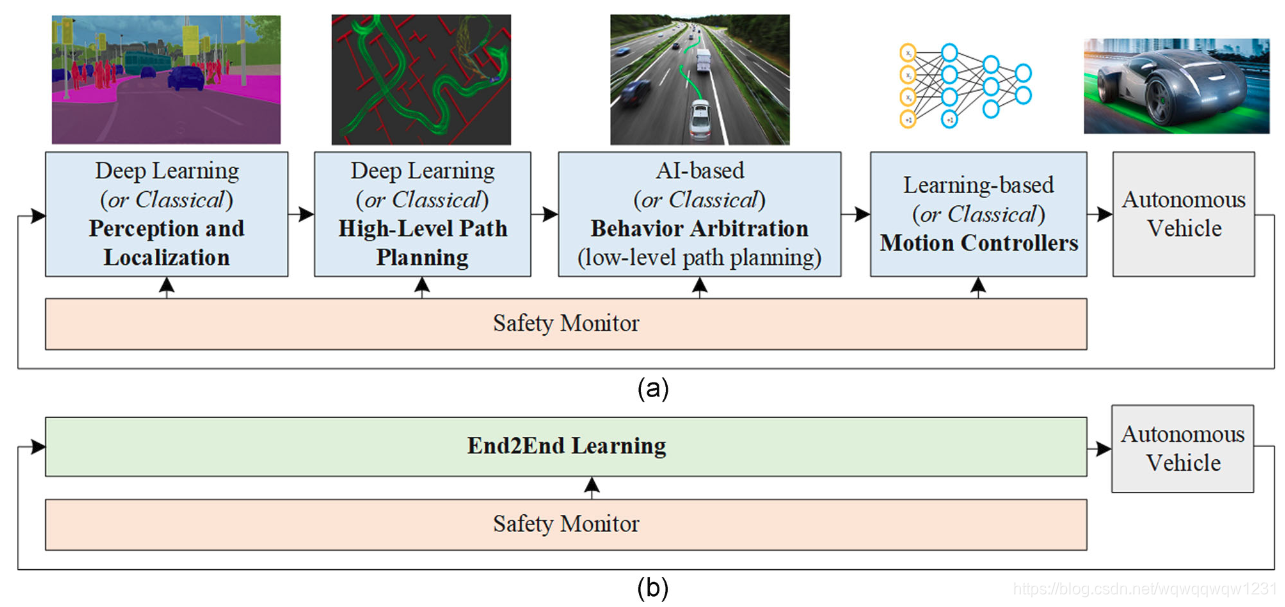
图1 基于深度学习的自动驾驶汽车。该体系结构既可以实现为顺序感知计划行动管线(a),也可以实现为End2End系统(b)。在顺序管道的情况下,可以使用AI和深度学习方法或基于经典的非学习方法来设计组件。End2End学习系统主要基于深度学习方法。通常设计安全监视器来确保每个模块的安全。人工智能,人工智能[彩色图形可以在wileyonlinelibrary.com上查看] 。
图1a中的模块化管道被分层分解为四个组件,可以使用深度学习和AI方法或经典方法进行设计。这些组件是:
- 感知和定位
- 高级路径规划
- 行为仲裁或低级路径规划
- 运动控制器。
在这四个高级组件的基础上,我们将描述用于自动驾驶系统的方法的相关深度学习论文归类在一起。除了上述算法之外,我们还对相关文章进行了分组,涵盖了在设计自动驾驶汽车深度学习模块时遇到的安全性,数据源和硬件方面的问题。
给定一条通过道路网络规划的路线,自动驾驶汽车的首要任务是在周围环境中了解和定位自身。在这种表示的基础上,计划了一条连续的道路,并由行为仲裁系统确定了汽车的未来动作。最终,运动控制系统反应性地纠正了在执行计划的运动中产生的错误。可以在Paden,Cáp,Yong,Yershov和Frazzoli(2016)中找到关于这四个组成部分的经典非AI设计方法的概述。
随后将介绍自动驾驶中使用的深度学习和AI技术以及调查用于设计上述分层决策过程的不同方法。此外,我们提供了End2End学习系统的概述,该系统用于将分层过程编码为单个深度学习体系结构,该体系结构将感官观察直接映射到控制输出
3、 深度学习技术概述
这一章节都是讲DNN的原理的,引用的文献也都很老,与Autonomous Driving没什么关系
3.1、CNN
3.2、RNN
3.3、DRL
代理无法直接访问模拟的环境状态。取而代之的是,传感器读数提供了有关环境真实状态的线索。要解码真实的环境状态,仅映射传感器读数的单个快照是不够的。时间信息也应该包含在网络的输入中,因为环境的状态会随着时间而改变。可以在Sallab,Abdou,Perot和Yogamani(2017a)中找到在模拟器中应用于AV的DQN示例.DQN已开发为在离散的动作空间中运行。在自动驾驶汽车的情况下,离散动作将转换为离散命令,例如左转,右转,加速或破坏。上面描述的DQN方法已经基于策略梯度估计扩展到了连续动作空间(Lillicrap et al。,2016)。Lillicrap等人的方法。(2016年)描述了一种无模型的行为批评算法,能够直接从原始像素输入中学习不同的连续控制任务。S. Gu,Lillicrap,Sutskever和Levine(2016)提出了一种基于模型的连续Q学习解决方案。
尽管可以使用DRL进行连续控制,但自动驾驶中最常见的DRL策略是基于离散控制(Jaritz,Charette,Toromanoff,Perot和Nashashibi,2018年)。由于agent必须探索其环境,因此这里面临的主要挑战是训练,通常是从碰撞中学习。仅在模拟数据上进行训练的此类系统倾向于学习驾驶环境的偏向版本。这里的解决方案是使用模仿学习(IL)方法,例如反强化学习(IRL, Wulfmeier,Wang和Posner,2016年),可以从人类驾驶示范中学习,而无需探索不安全的动作。
4、深入学习环境感知和定位
无人驾驶技术使车辆能够感知环境并做出响应,从而实现自动驾驶。接下来,我们将综合考虑基于摄像头与LiDAR的环境感知,来概述用于驾驶场景理解的最佳方法。我们调查了自动驾驶中的对象检测和识别,语义分割和定位以及使用占用图的场景理解。有关自动视觉和环境感知的调查可以在Zhu,Yuen,Mihaylova和Leung(2017)和Janai,Güney,Behl中找到。和盖格(2017)。
4.1、传感硬件:相机与激光雷达的辩论
深度学习方法特别适用于检测和识别分别从摄像机和LiDAR设备获取的二维(2D)图像和3D点云中的对象。
在自动驾驶社区中,3D感知主要基于LiDAR传感器,该传感器以3D点云的形式提供周围环境的直接3D表示。LiDAR的性能是根据视野,范围,分辨率和旋转/帧速率来衡量的。3D传感器(例如Velodyne®)通常具有360度的水平视场。为了高速行驶,AV至少需要200米的射程,从而使车辆能够及时响应路况的变化。3D对象检测精度取决于传感器的分辨率,最先进的LiDAR能够提供3cm的精度。
最近的辩论引发了相机与LiDAR传感技术之间的争论。领先于自动驾驶技术发展的两家公司Tesla®和Waymo®(O’Kane,2018)在其主要感知传感器以及目标SAE水平方面有不同的理念(SAE委员会,2014)。Waymo®直接将其车辆构建为5级系统,目前自动驾驶的里程超过了1000万英里。2另一方面,Tesla®将其AutoPilot部署为高级驾驶员辅助系统(ADAS)组件,客户可以在方便时打开或关闭它。Tesla®的优势在于其庞大的培训数据库中,该数据库包含超过10亿英里的行驶里程。3该数据库是通过从客户拥有的汽车中收集数据而获得的。
两家公司的主要传感技术均不同。Tesla®尝试利用其摄像头系统,而Waymo则更多地依赖于LiDAR传感器。传感方法各有利弊。激光雷达即使在黑暗中也具有高分辨率和精确的感知能力,但易受恶劣天气条件的影响(例如,大雨; Hasirlioglu,Kamann,Doric和&Brandmeier,2016年)并且涉及运动部件。相比之下,相机具有成本效益,但缺乏深度感知且无法在黑暗中工作。如果天气条件阻碍了视野,则相机对恶劣天气也很敏感。
康奈尔大学的研究人员试图从视觉深度估计中复制LiDAR类点云(Wang等人,2019)。相对于立体摄像机的左传感器坐标,将估计的深度图重新投影到3D空间中。产生的点云称为伪LiDAR。伪LiDAR数据可以进一步馈送到3D深度学习处理方法,例如PointNet(Qi,Su,Mo,&Guibas,2017)或聚合视图对象检测(AVOD; Ku,Mozifian,Lee,Harakeh,&Waslander,2018)。基于图像的3D估计的成功对于自动驾驶汽车的大规模部署至关重要,因为LiDAR无疑是自动驾驶汽车中最昂贵的硬件组件之一。
除了这些传感技术,雷达和超声波传感器还用于增强感知能力。例如,除了三个LiDAR传感器外,Waymo还使用了五个雷达和八个摄像头,而Tesla®汽车则配备了八个摄像头,12个超声波传感器和一个前向雷达。
4.2、驾驶场景理解
自动驾驶汽车应能够检测交通参与者和可驾驶区域,尤其是在可能出现各种物体外观和遮挡物的城市区域。基于深度学习的感知(尤其是CNN)已成为对象检测和识别的事实上的标准,在竞争中获得了显着的结果,例如ImageNet大规模视觉识别挑战(Russakovsky et al。,2015)。
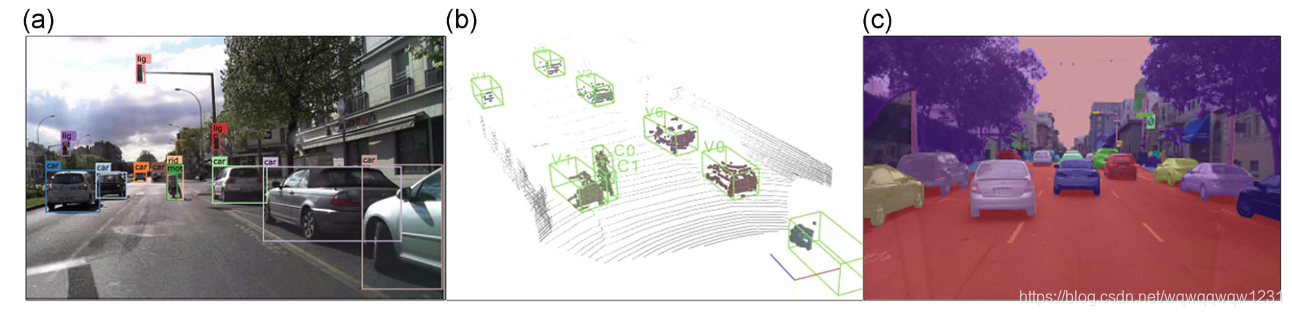
图3 场景感知结果的示例。(a)图像中的2D对象检测;(b)应用于LiDAR数据的3D边界框检测器;以及(c)图像上的语义分割结果。二维,二维;3D,三维[可在wileyonlinelibrary.com上查看彩色图形]
使用不同的神经网络架构来检测作为2D感兴趣区域的对象(Dai,Li,He和Sun,2016年; Girshick,2015年; Iandola等人,2016年; Law&Deng,2018年; Redmon,Divvala 吉尔希克(Girshick)和法哈迪(Farhadi),2016年;S. Zhang,Wen,Bian,Lei,&Li,2017)图像中的像素方向分割区域(Badrinarayanan,Kendall,&Cipolla,2017; He,Gkioxari,Dollar,&Girshick,2017; Treml等,2016; H.Zhao,Qi,Shen,Shi,&Jia,2018),LiDAR点云中的3D边界框(Luo,Yang,&Urtasun,2018; Qi et al。,2017; Zhou&Tuzel,2018),以及其中的对象的3D表示相机-LiDAR组合数据(X.Chen,Ma,Wan,Li,&Xia,2017; Ku等,2018; Qi,Liu,Wu,Su,&Guibas,2018)。场景感知结果的示例在图3中进行了说明。图像数据信息更丰富,更适合于对象识别任务。但是,由于深度信息在成像场景投影到成像传感器上时会丢失,因此必须估计检测到的对象的真实3D位置。
4.2.1、边界盒状物体检测器
用于图像中2D对象检测的最受欢迎的体系结构是单级和双级检测器。流行的单级检测器是“ You Only Look Once”(Yolo; Redmon等,2016; Redmon&Farhadi,2017、2018),单发多盒检测器(SSD; W。Liu等,2016),CornerNet(法律)&Deng,2018)和RefineNet(S. Zhang et al。,2017)。双级检测器,例如具有CNN(R-CNN)的区域(Girshick,Donahue,Darrell和Malik,2014),Faster-RCNN(Ren,He,Girshick和Sun,2017)或基于区域的全卷积网络(R-FCN; Dai et al。,2016),将物体检测过程分为两部分:感兴趣区域候选提案和边界框分类。通常,单级检测器不能提供与双级检测器相同的性能,但是速度要快得多。如果车载计算资源稀缺,则可以使用诸如SqueezeNet的检测器(Iandola等人,2016或(J.(Li,Peng,&Chang,2018),它们经过优化可在嵌入式硬件上运行,这些检测器通常具有较小的神经网络架构,从而可以减少操作次数来检测物体,但以检测精度为代价。上述对象检测器基于Pascal视觉对象类别(VOC)2012数据集及其测得的平均平均精度(mAP)(联合与交叉点(IoU)值分别等于50和75)给出在图4中。
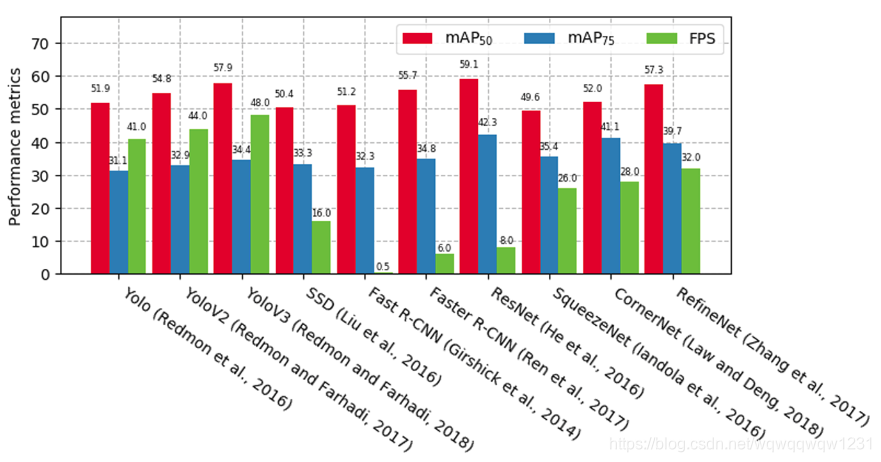
图4 对象检测和识别性能比较。评估已在Pascal VOC 2012基准数据库上进行。右边的前四种方法代表一级检测器,其余的六种是二级检测器。由于它们的复杂性增加,因此对于双级检测器,运行时性能以每秒帧数(FPS)较低。IoU,联合的交集;mAP,平均平均精度;SSD,单发多盒检测器;VOC,可视对象类[可以在wileyonlinelibrary.com上查看颜色图]
许多出版物展示了对原始3D感测数据以及视频和LiDAR组合信息的目标检测.PointNet(Qi等人,2017)和VoxelNet(Zhou&Tuzel,2018)旨在仅从3D数据中检测目标,提供还有对象的3D位置。但是,仅点云并不包含图像中可用的丰富视觉信息。为了克服这个问题,使用了组合的摄像头-LiDAR架构,例如FrustumPointNet(Qi等人,2018),Multiview 3D网络(MV3D; X.Chenet等人,2017)或RoarNet(Shin,Kwon和Tomizuka,2018年)在自动驾驶汽车的感官套件中使用LiDAR的主要缺点主要是其成本.5A解决方案将使用神经网络架构,例如AVOD(Ku等人,2018),该架构仅利用LiDAR数据。用于训练,而在训练和部署过程中使用图像。在部署阶段,AVOD能够仅从图像数据中预测对象的3D边界框。在这样的系统中,仅LiDAR传感器仅用于培训数据采集,就像今天用于收集道路数据导航地图的汽车一样。
4.2.2、语义和实例分割
驾驶场景理解也可以使用语义分割来实现,语义分割表示图像中每个像素的分类标记。在自动驾驶环境中,可以用代表可行驶区域,行人,交通参与者,建筑物等的分类标签标记像素。它是高级场景之一,可帮助您全面了解场景,并在自动驾驶,室内导航或虚拟现实和增强现实等应用中使用。
语义分割网络,例如SegNet(Badrinarayananet等,2017),ICNet(H.Zhao等,2018),ENet(Paszke,Chaurasia,Kim和Culurciello,2016),AdapNet(Valada,Vertens,Dhall和&Burgard(2017)或Mask RCNN(He et al。,2017)主要是具有像素分类层的编码器-解码器体系结构。这些体系结构是基于AlexNet(Krizhevsky,Sutskever和Hinton,2012),VGG-16(Simonyan&Zisserman,2014),GoogLeNet(Szegedy et al。,2015)或ResNet(He,Zhang,Ren,&Sun,2016)。
与边界框检测器一样,已努力改善这些系统在嵌入式目标上的计算时间。InTreml等。(2016)和Paszke等人。(2016),作者提出了一种方法来加速数据处理和嵌入式设备上的自动驾驶推理。两种架构都是光网络,可提供与SegNet相似的结果,并降低了计算成本。在AdapNet中解决了语义分割的鲁棒性目标以进行优化(Valada等人,2017)。该模型能够根据场景条件自适应学习专家网络的特征,从而在各种环境下进行稳健的分割,并使用MaskRCNN等架构获得结合的边界框对象检测器和语义分割结果(He et al。,2017)。。该方法通过添加一个与现有分支边界框识别并行的预测对象掩码的分支,将Faster-RCNN的有效性扩展到实例分割。图5显示了基于CityScapes数据集在四个关键语义分段网络上执行的测试结果。每类联合的平均交集(mIoU)指的是多类细分,其中每个像素被标记为属于特定对象类,而每类mIoU则指前景(对象)-背景(非对象)分割。输入样本的大小为×480 px 320 px
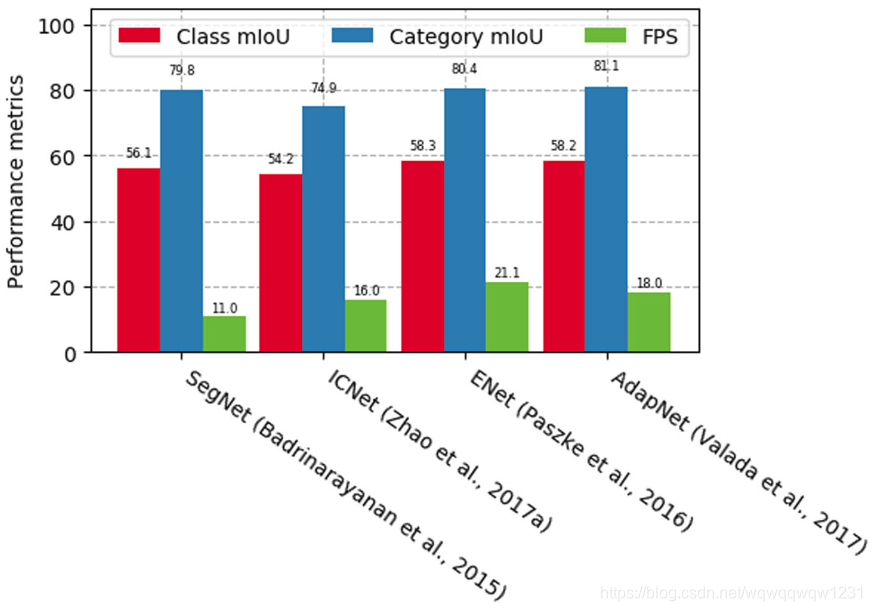
图5 在Cityscapes数据集上进行语义分割性能比较(Cityscapes,2018)。输入样本是驾驶场景的×480 px 320 px图像。FPS,每秒帧数;mIoU,平均交叉点重叠[可以在atwileyonlinelibrary.com查看颜色图
4.2.3、定位
定位算法旨在在AV导航时计算其姿态(位置和方向)。尽管这可以使用GPS等系统实现,我们将重点研究基于视觉的本地化的深度学习技术。视觉的本地化,也称为视觉测距法(VO),通常是通过匹配连续视频帧中的关键点地标来确定的。在给定当前帧的情况下,这些关键点用作透视图n点映射算法的输入,用于计算车辆相对于前一帧的姿态。深度学习可通过直接影响关键点检测器的精度来提高VO的准确性。在Barnes,Maddern,Pascoe和Posner(2018)中,已经对一个深度神经网络进行了训练,以学习单眼VO中的关键点干扰因素。所谓的“学习型神经网络掩码”充当关键点离群值的拒绝方案,这可能会降低车辆定位的准确性。环境的结构可以通过相机姿势的计算来增量映射。这些方法属于同时定位和映射(SLAM)领域。对于经典SLAM技术的调查,我们向读者介绍了Bresson,Alsayed,Yu和Glaser(2017).PoseNet(Kendall,Grimes,&Cipolla,2015),VLocNet ++(Radwan,Valada和Burgard,2018),或Walch等人引入的方法。(2017),Melekhov,Ylioinas,Kannala和Rahtu(2017),Laskar,Melekhov,Kalia和Kannala(2017),Brachmann和Rother(2018)或Sarlin,Debraine,Dymczyk,Siegwart和Cadena(2018),正在使用图像数据以End2End方式估计相机的3D姿势。场景语义可以与估计的姿势一起导出(Radwan等人,2018).LiDAR强度图也适合于学习自动驾驶汽车的实时,校准不可知的本地化(Barsan,Wang,Pokrovsky和Urtasun,2018年)。。该方法使用深度神经网络从LiDARsweeps和强度图构建学习的驾驶场景表示。车辆的定位是通过卷积匹配获得的。在廷契夫(Tinchev),佩纳特·桑切斯(Penate-Sanchez)和法伦(Fallon)(2019)中,使用激光扫描和深度神经网络来学习用于在城市和自然环境中进行本地化的描述符。
4.3、使用occupancy maps的感知
占用图(也称为OG)是环境的表示,该环境将驾驶空间划分为一组单元并计算每个单元的占用概率。OGrepresentation在机器人技术中很受欢迎(Garcia-Favrot和Parent,2009; Thrun,Burgard和&Fox,2005),成为自动驾驶汽车的合适解决方案。一对OG数据样本如图6所示

图6 占用网格(OG)的示例。图像显示了驾驶环境及其各自的OG的快照(Marina等人,2019)[颜色图可在wileyonlinelibrary.com上查看] 10 | GRIGORESCUET AL。
深度学习可用于占用图的环境中,用于动态物体的检测和跟踪(Ondruska,Dequaire,Wang和Posner,2016),围绕车辆的占用图的概率估计(Hoermann,Bach和Dietmayer,2017年; Ramos,Gehrig),Pinggera,Franke和Rother,2016年),或用于得出驾驶场景上下文(Marina等人,2019年; Seeger,Müller和&Schwarz,2016年)。在后一种情况下,OG是通过随时间累积数据来构造的,而深度神经网络用于将环境标记为驾驶环境类别,例如高速公路驾驶,停车区或城市内驾驶。
占用图表示车载虚拟环境,以一种更适合路径规划和运动控制的形式集成了感知信息。深度学习在OG的估计中起着重要作用,因为用于填充网格单元的信息是从使用场景感知方法处理图像和LiDAR数据中推断出来的,如本章所述。
5、深度学习的路径规划和行为仲裁
自动驾驶汽车在两点之间找到路线的能力,即起始位置和所需位置,代表了路径规划。根据路径规划过程,无人驾驶汽车应考虑周围环境中存在的所有可能障碍物,并计算出无碰撞路线的轨迹。正如Shalev‐Shwartz,Shammah和Shashua(2016)所述,无人驾驶是一种多主体环境,在超车,让路,合并,左转和右转时,当车辆在非结构化城市中行驶时,宿主车辆必须与其他道路使用者应用复杂的谈判技巧巷道。文学方面的发现指出了一项不平凡的政策,应该在驾驶中确保安全。考虑到应该避免的意外事件的奖励函数(̄)=-Rsr和其余轨迹的(̄)∈[-] Rs1,1,目标是学会平稳而安全地执行困难的操纵。
自动驾驶汽车的最佳路径规划这一新兴主题应以较高的计算速度运行,以在满足特定优化标准的同时获得较短的反应时间。彭德尔顿等人的调查。(2017)提供了汽车领域路径规划的一般概述。它介绍了路径规划的分类法方面,即任务规划器,行为规划器和运动规划器。然而,彭德尔顿等。(2017)没有包含对深度学习技术的评论,尽管最新的文献显示对使用深度学习技术进行路径规划和行为仲裁的兴趣有所增加。接下来,我们讨论路径规划中两个最具代表性的深度学习范例,即IL(Grigorescu,Trasnea,Marina,Vasilcoi和Cocias,2019; Rehder,Quehl和&Stiller,2017; Sun,Peng,Zhan和Tomizuka,2018)和DRL-基础计划(Paxton,Raman,Hager和Kobilarov,2017; L.Yu,Shao,Wei和Zhou,2018)。
IL的目标是(Grigorescu等,2019; Rehder等,2017; Sunet等,2018),目的是从记录的驾驶经验中了解人类驾驶员的行为(Schwarting,Alonso-Mora和Rus,2018)。该策略暗示了人类示范的车辆教学过程。因此,作者聘用CNN来从模仿中学习计划。例如,NeuroTrajectory(Grigorescu et al。,2019)是一种感知规划的深度神经网络,可在有限的预测范围内学习自我车辆的理想状态轨迹。ILcan也被视为IRL问题,其目标是向人类驾驶员学习其功能(T. Gu,Dolan和Lee,2016; Wulfmeier等,2016)。此类方法使用真实的驾驶员行为来学习奖励功能并生成类似于人的驾驶轨迹。
路径规划的DRL主要是在模拟器中学习驾驶轨迹(Panov,Yakovlev和Suvorov,2018年; Paxton等人,2017年; Shalev‐Shwartz等人,2016年; L.Yu等人,2018年)。该模型基于传输模型被抽象并转换为虚拟环境。在Shalev‐Shwartzet等人中。(2016年)指出,目标函数不能确保函数安全性而不会引起严重的方差问题。针对此问题的建议解决方案是构建由可学习部分和不可学习部分组成的策略功能。可学习的策略使奖励功能最大化(包括舒适性,安全性,超车机会等)。同时,不可学习的政策遵循功能安全性的严格限制,同时保持可接受的舒适度。
IL和DRL在路径规划中都有优点和缺点。IL的优点是可以使用从现实世界收集的数据进行训练。不过,这些数据很少出现在紧急情况下(例如,驶离车道,发生车祸等),使得训练有素的网络在面对看不见的数据时的响应不确定。另一方面,尽管DRL系统能够在模拟世界中探索不同的驾驶情况,但是当移植到现实世界中时,这些模型往往会产生偏差。
6、基于运动控制器的自动驾驶汽车
运动控制器负责计算车辆的纵向和横向转向命令。学习算法既可以用作学习控制器的一部分,也可以用作图1a的运动控制模块中的一部分,也可以用作完整的End2End控制系统,将传感数据直接映射到转向命令,如图1b所示
6.1、学习的控制器
传统控制器利用由固定参数组成的先验模型。当机器人或其他自治系统用于复杂环境(例如驾驶)时,传统的控制器无法预见系统必须应对的所有可能情况。与固定参数的控制器不同,学习型控制器会利用训练信息来随着时间推移学习其模型。随着每一批收集的训练数据,真实系统模型的逼近度将变得更加准确,从而实现模型的灵活性,一致的不确定性估计以及可重复影响和干扰的预期不能在部署前建模(Ostafew,Collier,Schoellig和Barfoot,2015年)。考虑非线性状态空间系统
在以前的工作中,已经基于简单的函数逼近器引入了学习控制器,例如高斯过程(GP)建模(Meier,Hennig和Schaal,2014年; Nguyen-Tuong,Peters和Seeger,2008年; Ostafew等人,2015年。Ostafew,Schoellig,&Barfoot,2016)或支持向量回归(Sigaud,Salaün,&Padois,2011)。
学习技术通常用于学习动力学模型,从而改善先验系统模型的迭代学习控制(ILC; Kapania&Gerdes,2015; Ostafew,Schoellig,&Barfoot,2013; Panomruttanarug,2017; Z.Yang,Zhou,Li,&Wang,2017b)和模型预测控制(MPC; Drews,Williams,Goldfain,Theodorou,&Rehg,2017; Lefevre,Carvalho,&Borrelli,2015; Lefevre,Carvalho,&Borrelli,2016; Ostafew等,2015,2016;Panet等人,2018,2017; Rosolia,Carvalho和Borrelli,2017)。
ILC是一种控制以重复模式工作的系统的方法,例如自动驾驶汽车的路径跟踪。它已成功地应用于越野地形中的导航(Ostafewet等人,2013),自动驾驶停车场(Panomruttanarug,2017)以及自动驾驶汽车的转向动力学建模(Kapania&Gerdes,2015)。强调了多种好处,例如使用简单且具有计算能力的光反馈控制器,以及减少控制器的设计工作量(通过预测路径干扰和平台动力学来实现)。
MPC(Rawlings&Mayne,2009)是一种控制策略,通过解决优化问题来计算控制动作。由于它能够处理具有状态和输入约束的复杂非线性系统,在过去的二十年中它受到了广泛的关注。MPC的中心思想是在每个采样时间通过在短时间内最小化成本函数来计算控制动作,同时考虑到观察,输入-输出约束和过程模型给出的系统动力学。Kamel,Hafez和Yu(2018)对自动机器人的MPC技术进行了一般性综述。
学习已与MPC结合使用来学习驾驶模型(Lefevre等人,2015;Lefèvre等人,2016),在操纵极限下运行的赛车的驾驶动力学(Drews等人,2017; Rosolia等人,2017)),以及提高路径跟踪的准确性(Brunner,Rosolia,Gonzales和Borrelli,2017年; Ostafew等人,2015年,2016年)。这些方法使用学习机制来识别在MPC的轨迹成本函数优化中使用的非线性动力学。这使人们能够更好地预测车辆的干扰和行为,从而导致对控制输入施加最佳的舒适性和安全性约束。训练数据通常以过去的车辆状态和观察结果的形式出现。例如,CNN可用于在本地机器人中心坐标系中计算密集的OG地图。网格图会进一步传递给MPC的成本函数,以在有限的预测范围内优化车辆的轨迹。
学习控制器的主要优势在于,它们可以将传统的基于模型的控制理论与学习算法完美地结合在一起。这使得仍然可以将既定的方法学用于控制器设计和稳定性分析,以及在系统识别和预测级别应用强大的学习组件
6.2、端到端学习控制
在自动驾驶的背景下,End2End学习控制被定义为从感官数据到控制命令的直接映射。输入通常来自高维特征空间(例如图像或点云)。如图1b所示,这与传统的处理流水线相反,在传统的流水线中,首先在输入图像中检测到对象,然后规划路径,最后执行计算出的控制值。表1总结了一些最受欢迎的End2End学习系统。
End2End学习也可以表述为扩展到复杂模型的反向传播算法。该范式是在1990年代首次引入的,当时它建立了非人工神经网络自动驾驶汽车(ALVINN)系统(Pomerleau,1989年)。ALVINN的设计遵循预定道路,并根据观察到的道路曲率进行转向。在End2End驾驶中的下一个里程碑被认为是在2000年代中期,在经过类似但并非完全相同的驾驶场景的人类驾驶小时培训后,那时Darpa自主汽车(DAVE)设法通过障碍物充满的道路(Muller等人,2006)。在过去的几年中,计算硬件的技术进步促进了End2End学习模型的使用。现在,可以在并行图形处理单元(GPU)上有效地实现用于梯度估计深层网络的反向传播算法。这种处理方式允许训练大型和复杂的网络体系结构,这又需要大量的训练样本(请参阅第8节)。
End2End控制论文主要采用在现实世界和/或合成数据上脱机训练的深度神经网络(Bechtelet等人,2018; Bojarski等人,2016; C.Chen,Seff,Kornhauser,&Xiao,2015; Eraqi等人。,2017年; Fridman等人,2017年; Hecker等人,2018年; Rausch等人,2017年; Xu等人,2017年; S.Yang等人,2017a),或在模拟中训练和评估的DRL系统(Jaritz等人,2018; Perot,Jaritz,Toromanoff,&Charette,2017; Sallab等人,2017b)。还已经报道了将模拟训练的DRL模型移植到现实世界驾驶的方法(Wayve,2018),以及直接在现实世界的图像数据上训练的DRL系统(Pan等人,2017,2018)。
End2End方法在最近几年中被NVIDIA®作为PilotNet架构的一部分而得到普及。该方法是训练CNN,该CNN将单个前置摄像头的原始像素直接映射到操纵命令(Bojarski等人,2016)。训练数据由在各种照明和天气状况以及不同道路类型下执行的驾驶场景中收集的图像和转向命令组成。在训练之前,使用扩充功能丰富数据,在原始数据中添加人工移位和旋转。
PilotNet具有250,000个参数和大约2,700万个连接。评估分两个阶段进行:第一阶段模拟,第二阶段在测试车中进行。自主性能指标代表神经网络驾驶汽车的时间百分比

当模拟车辆偏离中心线超过1 m时,即认为是6 s是人类重新控制车辆并将其恢复到所需状态所需的时间,因此将采取干预措施。从霍姆德尔到新泽西州大西洋高地20公里车程,自治度达到98%。通过培训,PilotNet了解了驾驶员如何计算转向指令(Bojarski等人,2017)。重点在于确定输入流量图像中的哪些元素对网络的转向决策影响最大。描述了一种在输入图像中找到显着物体区域的方法,同时得出结论,PilotNet学习的低级特征类似于与驾驶员相关的特征。
Rausch等人已经报道了类似于PilotNet的End2End架构,该架构将视觉数据映射到操纵命令。(2017),Bechtel等。(2018)和C.Chen等人。(2015)。在徐等人。(2017)
引入的FCN-LSTM方法旨在使用全卷积编码器联合训练像素级监督任务,以及通过时间编码器进行运动预测。Eraqi等人也考虑了输入数据的视觉时间依存关系之间的组合。(2017年),其中提出了卷积长短期记忆(C-LSTM)网络进行转向控制。在Hecker等人中。(2018),环视摄像机用于End2End学习。据称,驾驶员还使用后视镜和侧视镜进行驾驶,因此需要收集车辆周围的所有信息并将其集成到网络模型中以输出适当的控制命令。
为了对Tesla®AutoPilot系统进行评估,Fridmanet等。(2017)提出了End2End CNN框架。它旨在确定AutoPilot及其自身输出之间的差异,并考虑了边缘情况。该网络使用了从超过420个小时的实际道路行驶中收集的真实数据进行训练。Tesla®的AutoPilot与建议的框架之间的比较是在Tesla®汽车上实时完成的。评估显示,在检测两个系统之间的差异以及汽车向人类驾驶员的控制转移方面,准确性为90.4%。
设计End2End驱动系统的另一种方法是DRL。这主要是在仿真中执行的,在该仿真中,自治代理可以安全地探索不同的驾驶策略。在Sallab等。(2017b),DRL End2End系统用于在TORCS游戏仿真引擎中计算转向命令。考虑到更复杂的虚拟环境,Perot等人。(2017)提出了一种异步优势ActorCritic(A3C)方法,用于在图像和车速信息上训练CNN。贾里茨等人也增强了同样的想法。(2018),具有更快的收敛性和更宽泛的宽松性。这两篇文章都依赖于以下过程:接收游戏的当前状态,然后确定ext控制命令,然后在nextiteration上获得奖励。实验装置得益于现实的赛车游戏,即世界汽车拉力锦标赛6,也得益于其他模拟环境,例如TORCS。
基于DRL的控制的下一个趋势似乎是将经典的基于模型的控制技术包括在内,如第6.1节所述。经典控制器提供了稳定的确定性模型,并在此模型上估算了神经网络的策略。通过这种方式,将建模系统的硬约束转移到神经网络策略中(T.Zhang,Kahn,Levine和Abbeel,2016年)。在Panet等人中提出了针对真实图像数据进行训练的ADRL政策。(2017年,2018年)进行主动驾驶。在这种情况下,使用模型预测控制器以训练时提供的最佳轨迹示例训练CNN(称为学习者)。
7、自主驾驶中深度学习的安全性
安全意味着缺乏导致系统危险的条件(Ferrel,2010)。演示系统的安全意味着缺乏导致系统危险的条件(Ferrel,2010)。演示系统的安全性:
- 理解可能发生的故障的影响
- 了解更广泛系统中的上下文
- 定义有关系统上下文和可能使用它的环境的假设
- 定义安全行为的含义,包括非功能性约束
Burton,Gauerhof和Heinzemann(2017),上述示例针对深度学习组件映射了一个示例。该组件的问题空间是带有CNN的行人检测。该系统的首要任务是在100 m的距离内定位类人的物体,其横向精度为±20 cm,假阴性率为1%,假阳性率为5%。假设当检测到车辆的计划轨迹为100 mahead的人员时,制动距离和速度足以做出反应。可以使用替代的传感方法将系统的总体假阴性和假阳性率降低到可接受的水平。上下文信息是距离和精度应映射到呈现给CNN的图像帧的尺寸。
机器学习或深度学习的上下文中,术语安全没有公认的定义。在Varshney(2016)中,Varshney定义了风险,认识论的不确定性以及不良后果所造成的危害方面的安全性。Hethen分析了成本函数的选择以及使经验平均培训成本最小化的适当性。Amodei等。(2016)考虑了机器学习系统中的事故问题。此类事故被定义为不良AI系统设计中可能出现的意外行为和有害行为。作者列出了与事故风险相关的五个实际研究问题的列表,这些问题是根据问题是由于目标函数错误(避免副作用和避免奖励黑客攻击),过于昂贵而无法经常评估(可分级监督)还是在评估过程中出现不良行为而产生的。学习过程(安全探索和分配转移)。
为了扩大安全范围,Möller(2012)提出了一种安全的决策理论定义,适用于广泛的领域和系统。他们将安全性定义为与不必要的后果相关的风险和认知不确定性的降低或最小化,这些后果严重到足以被视为有害。该定义的关键点是:(a)从某种意义上讲,有害事件的成本必须足够高才能使事件成为有害事件;(b)安全性既要降低预期伤害的可能性,也要降低意外伤害的可能性。
不管以上关于安全性的经验定义和可能的解释如何,在不安全关键的系统中使用深度学习组件仍然是一个未解决的问题。用于道路车辆功能安全的ISO 26262标准提供了一套全面的确保安全的要求,但未解决基于深度学习的软件的独特功能。Queiroz和Czarnecki(2017)通过分析机器学习可能会影响标准的地方来解决这一差距,并就如何适应这种影响提供了建议。这些建议侧重于确定危害,故障和失败情况的实现工具和机制的方向,同时也要确保完整的培训数据集和设计多层体系结构。需要在软件开发生命周期的各个阶段使用特定技术。
ISO 26262标准建议使用危险分析和风险评估(HARA)方法来识别系统中的危险事件并指定减轻危险的安全目标。该标准有10个部分。我们的重点是第6部分:软件级别的产品开发,这是遵循众所周知的V工程模型的标准。汽车安全完整性等级(ASIL)是指ISO 26262中针对汽车系统中某个项目(例如,子系统)定义的风险分类方案。
ASIL表示降低风险所需的严格程度(例如,测试技术,所需的文档类型等),其中ASIL D代表最高风险,而ASIL A代表最低风险。如果将元素分配给质量管理(QM),则不需要安全管理。首先,将针对给定危害评估的ASIL分配给旨在解决该危害的安全目标,然后根据该目标得出的安全要求继承该目标(Salayet等人,2017)
根据ISO 26226,危害定义为“由行为失常引起的潜在伤害源,其中伤害是人身伤害或对人的健康的损害”(Bernd等,2012)。但是,深度学习组件可能会产生新的危害类型。通常会发生这种危害的一个例子,因为人们认为自动驾驶辅助系统(通常是使用学习技术开发的)比实际更可靠(Parasuraman&Riley,1997)
分析深度学习组件安全性的关键要求是检查结果的直接人工成本是否超过某些危害严重性阈值。从人类的角度来看,不希望有的结果确实是有害的,并且它们的影响可以实时地感受到。这些结果可以归类为安全问题。深度学习决策的成本与明确包含损失函数L的优化公式有关。
通常,概率分布是未知的,从而排除了对域的使用适应技术(Caruana等,2015;Daumé&Marcu,2006)。这是与安全性相关的认知不确定性之一,因为对不同分布的数据集进行训练可能会因偏见而造成很大的伤害。
实际上,机器学习系统仅会遇到有限数量的测试样本,而实际操作风险是测试集上的经验数量。即使风险是最佳的,操作风险也可能比小型基数测试仪的实际风险大得多。由测试集实例化引起的不确定性可能对单个测试样本具有很大的安全隐患(Varshney&Alemzadeh,2016)。
编程组件的故障和失败(例如,使用非正式算法解决问题的故障)与深度学习组件的故障和故障完全不同。深度学习组件的特定故障可能由不可靠或嘈杂的传感器信号(由于恶劣天气导致的视频信号,由于吸收建筑材料而引起的雷达信号,GPS数据等),神经网络拓扑,学习算法,训练集或环境的意外变化引起(例如,未知的驾驶场景或道路上的事故)。我们回想起特斯拉汽车造成的第一次自动驾驶事故,由于对象分类错误,自动驾驶功能将车辆撞向卡车(莱文,2018年)。尽管进行了1.3亿英里的测试和评估,但事故是在极为罕见的情况下(也称为黑天鹅)造成的,这是由于卡车的高度,其明亮的天空下为白色,以及车辆在马路上的位置所致。
自动驾驶车辆必须具有故障安全机制,通常以安全监视器的名称出现。一旦检测到故障,这些必须停止自主控制软件(Koopman,2017),在Kurd,Kelly和Austin(2007),Harris(2016)和麦克弗森(2018)中。这导致开发了专门且重点突出的工具和技术来帮助发现故障。Chakarov,Nori,Rajamani,Sen和2015 Vijaykeerthy(2018)描述了一种由于不良训练数据而对错误分类进行调试的技术,而Nushi,Kamar,Horvitz和Kossmann((2017)。在Takanami,Sato和Yang(2000)中,白盒技术用于通过断开链接或随机改变权重将故障注入到神经网络中。
训练集在深度学习组件的安全性中起着关键作用。ISO 26262标准规定,应充分规定组件的性能,并应根据其规格对每个改进进行验证。在深度学习系统中,使用训练集而不是规范的情况违反了该假设。目前尚不清楚如何确保始终减轻相应的危害。训练过程不是平均过程,因为受训练的模型将根据训练集的构造而正确,直到模型和学习算法的限制为止(Salay et al。,2017)。这种考虑的影响在商用视音频市场中显而易见,在该市场中,由训练集中不存在的数据引起的BlackSwan事件可能导致死亡(McPherson,2018)
应制定详细的要求并将其追溯到危险源。此类要求可以指定如何获得训练,验证和测试集。随后,可以相对于本说明书验证收集的数据。此外,可以使用某些规范(例如,车辆不能超过3 m的事实)来拒绝误报。这样的属性甚至可以在训练过程中直接使用以提高模型的准确性(Katz,Barrett,Dill,Julian,&Kochenderfer,2017)
即使对于安全性至关重要的系统,机器学习和深度学习技术也已开始变得有效和可靠,即使此类系统的完整安全性保证仍然是未解决的问题。车行业的当前标准和法规无法完全映射到此类系统,需要开发针对深度学习的新安全标准。
8、训练自动驾驶系统的数据源
不可否认,使用实时数据是培训和测试自动驾驶组件的关键要求。在此类组件的开发阶段需要大量数据,使得在公共道路上收集数据成为一项有价值的活动。为了获得对驾驶场景的全面描述,用于数据收集的车辆配备了各种传感器,例如雷达,LiDAR,GPS,摄像机,惯性测量单元(IMU)和超声波传感器。传感器的设置因车辆而异,具体取决于计划如何使用数据。AV的常见传感器设置如图7所示。
近年来,主要是由于对自动驾驶汽车的研究兴趣越来越大,许多驾驶数据集已经公开并记录在案。它们的大小,传感器设置和数据格式各不相同。研究人员仅需确定最适合其问题空间的适当数据集即可。Janai等。(2017)发表了关于广泛数据集的调查。这些数据集通常可以解决计算机视觉领域的问题,但很少有适合自动驾驶的主题。
关于自动驾驶车辆算法的公开可用数据集的最全面调查可以在Yin和Berger(2017)中找到。本文介绍了27个可用数据集,其中包含在公共道路上记录的数据。从不同的角度比较数据集,以便读者可以选择最适合自己的任务。
尽管我们进行了广泛的搜索,但我们仍未找到将至少一部分可用数据组合在一起的主数据集。原因可能是数据格式和传感器设置没有标准要求。每个数据集在很大程度上取决于收集数据的算法目标。最近,Scale®和nuTonomy®公司开始创建迄今为止市场上最大,最详细的自动驾驶数据集之一.6其中包括由伯克利大学研究人员开发的伯克利DeepDrive(F.Yu等人,2018)。
在Fridman等人中。(2017),作者提出了一项研究,旨在收集和分析大规模的半自动驾驶自然主义数据,以更好地刻画当前技术的最新水平。该研究涉及99名参与者,29辆汽车,405、807英里和大约55亿个视频帧。不幸的是,这项研究中收集的数据尚未公开。
在本节的其余部分中,我们将提供并强调公开可用的最相关数据集的独特特征(表2)。
KITTI Vision Benchmark数据集(KITTI; Geiger et al。,2013):由德国卡尔斯鲁厄理工学院(KIT)提供,该数据集适合基准立体视觉,光流,3D跟踪,3D对象检测,或SLAM算法。它被称为自动驾驶汽车领域中最负盛名的数据集。迄今为止,它在文献中已经引用了2,000多次引用。数据采集车配备了多个高分辨率彩色和灰度立体摄像机,一个 Velodyne 3D LiDAR和高精度GPS / IMU传感器。总体而言,它提供了在卡尔斯鲁厄周围农村和公路交通场景中收集的6小时驾驶数据。该数据集位于Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Li-cense下提供。
uScenes数据集(Caesar等人,2019):由nuTonomy构造,该数据集包含从波士顿和新加坡收集的1,000个驾驶场景,这两个场景以交通繁忙和极富挑战性的驾驶状况而闻名。为了简化常见的计算机视觉任务,例如对象检测和跟踪,提供程序在整个数据集上以2 Hz的准确3D边界框注释了25个对象类。车辆数据的收集工作仍在进行中,最终的数据集将包括约140万个摄像机图像,400,000次LiDAR扫描,130万次RADAR扫描以及40,000个关键帧中的110万个对象边界框。数据集由知识共享署名-非商业性-相同方式共享3.0许可提供
汽车多传感器数据集(AMUSE; Koschorrek等人,2013):由瑞典林雪平大学提供,由在各种环境中记录的序列组成,这些序列是从装有全方位多相机,高度传感器,IMU,速度传感器和GPS的汽车中记录的。向公众提供了用于读取这些数据集的应用程序编程接口(API),以及以给定的格式。数据集位于CreativeCommons归因-NonCommercial-NoDerivs 3.0 UnsupportedLicense下多传感器和多相机数据流的集合储存以给定的格式。数据集位于CreativeCommons归因NonCommercial-NoDerivs 3.0 UnsupportedLicense下
福特校园视野和LiDAR数据集(Ford; Pandey等人,2011):由密歇根大学提供,该数据集是使用福特F250皮卡车收集的配备专业(Applanix POS‐LV)和消费(Xsens MTi‐G)IMU,Velodyne LiDAR扫描仪,两个推扫式前视Riegl LiDAR和Point GreyLadybug3全向摄像头系统。2009年,在福特研究园区和密歇根州迪尔伯恩市区附近记录了大约100 GB的数据。该数据集非常适合测试各种自动驾驶和SLAM算法。
Udacity数据集(Udacity,2018年):车辆传感器设置包含单目彩色摄像机,GPS和IMU传感器以及Velodyne 3D LiDAR。数据集的大小为223 GB。数据带有标签,并向用户提供驾驶员在测试过程中记录的相应转向角。
Cityscapes数据集(Cityscapes,2018年):由德国戴姆勒AGR&D提供;德国马克斯·普朗克信息学研究所(MPI‐IS),德国达姆施塔特工业大学视觉推理小组,德国,Cityscapes数据集着重于对城市街道场景的语义理解,这就是其仅包含立体视觉彩色图像的原因。图像的多样性非常大:50个城市,不同的季节(春季,夏季和秋季),各种天气条件和不同的场景动态。有5,000张带有精细注释的图像和20,000张带有粗注释的图像。使用此数据集对基准进行语义分割算法(H.Zhao,Shi,Qi,Wang和Jia,2017)和实例分割(S.S.(Liu,Jia,Fidler&Urtasun,2017).
Oxford数据集(Maddern等人,2017):由英国牛津大学提供,数据集的收集时间跨度超过1年,产生了超过1,000公里的行驶记录,几乎从安装在车辆上的六个摄像头以及LiDAR,GPS和INS地面实况收集了2000万张图像。在所有天气条件下都收集了数据,包括大雨,夜晚,阳光直射和下雪。该数据集的特点之一是,该车辆在一年的时间内经常行驶相同的路线,以使研究人员能够研究在现实世界,动态城市环境中对AV进行的长期定位和制图。(CamVid; Brostowet et al。,2009):由英国剑桥大学提供,它是文献中引用最多的数据集之一,并且是第一个公开发布的数据集,其中包含具有对象类语义标签的视频集以及元数据注释。该数据库提供了将每个像素与32个语义类之一相关联的地面真相标签。传感器设置仅基于一个安装在车辆仪表板上的单目摄像头。场景的复杂性非常低,仅在交通流量相对较低且天气条件良好的城市地区驾驶车辆。
剑桥驾驶标签视频数据集(CamVid; Brostowet等,2009):由英国剑桥大学提供,它是文献中引用次数最多的数据集之一,也是第一个公开发布的数据集,其中包含带有对象的视频集合类语义标签以及元数据注释。该数据库提供了将每个像素与32个语义类之一相关联的地面真相标签。传感器设置仅基于一个安装在车辆仪表板上的单目摄像头。场景的复杂性非常低,仅在交通流量较低且天气条件良好的城市地区驾驶车辆。
戴姆勒行人基准数据集(Flohr&Gavrila,2013年):由戴姆勒股份公司研发部和阿姆斯特丹大学提供,该数据集适合行人检测,分类,分割和路径预测。仅使用车载单声道和立体摄像机从行车中观察到行人数据。这是第一个包含行人的数据集。最近,数据集扩展了以相同设置捕获的骑自行车者视频样本(X. Li等人,2016)。
加州理工学院行人检测数据集(Caltech; Dollar等,2009):由美国加州理工学院提供,该数据集包含带注释的丰富视频,这些视频是从行驶中的车辆记录下来的,具有挑战性的低分辨率图像和经常被人遮挡的图像。大约10个小时的驾驶场景,总计约25万帧,共计35万个边界框和2300个独特的行人注释。注释包括边界框和详细的遮挡标签之间的时间对应
考虑到可用数据库的多样性和复杂性,可能很难选择一个或多个来开发和测试自动驾驶组件。可以看出,传感器设置在所有可用数据库中都不同。为了实现本地化和车辆行驶,必须使用LiDAR和GPS / IMU传感器,其中最受欢迎的LiDAR传感器是Velodyne(Velodyne,2018)和Sick(Sick,2018)。从雷达传感器记录的数据仅存在于NuScenes数据集中。雷达制造商采用非公开的专有数据格式。几乎所有可用的数据集都包括从摄像机捕获的图像,而主要配置为捕获灰度图像的单眼和立体摄像机则得到了平衡的使用。AMUSE和Ford数据库是唯一使用全向摄像机的数据库
除了原始记录的数据外,数据集通常还包含其他文件,例如注释,校准文件,标签等。为了处理此文件,数据集提供者必须提供使用户能够读取和后处理数据的工具和软件。由于某些数据集(例如,Caltech,Daimler等),数据集的拆分也是要考虑的重要因素。和Cityscapes)已经提供了经过预处理的数据,这些数据分为不同的组:测试,测试和验证。这样可以使期
要考虑的另一个方面是许可证类型。最常用的许可证是Creative Commons Attribution-NonCom-mercial-ShareAlike 3.0。它允许用户以任何介质或格式复制和重新分发,还可以在材料上进行重新混合,转换和构建。KITTI和NuScenes数据库就是这种发行许可证的示例。牛津数据库使用知识共享署名-非商业4.0。与第一许可证类型相比,这不强制用户在与数据库相同的许可证下分配他的贡献。与之相反,AMUSE数据库是根据知识共享署名-非商业性-noDerivs 3.0许可的,这使得如果对材料进行了修改,则该数据库是非法分发的望算法与类似方法的基准测试保持一致
除极少数例外,数据集是从单个城市收集的,该城市通常位于欧洲,美国或亚洲的大学校园或公司所在地。德国是驾驶录音车的最活跃国家。不幸的是,所有可用数据集一起覆盖了世界地图的一小部分。一原因是数据的存储大小与传感器的设置和质量成正比。例如,Forddata集每行驶1公里大约需要30 GB,这意味着覆盖整个城市将需要数百TeraBytes的驱动数据。大部分可用数据集都考虑了晴天,白天和城市情况,这些是自动驾驶系统的理想运行条件
9、计算硬件和部署
在目标边缘设备上部署深度学习算法不是一项艰巨的任务。涉及车辆的主要限制因素是价格,性能问题和功耗。因此,嵌入式平台由于其便携性,多功能性和能效,对于将AI算法集成到车辆内变得至关重要。
在提供用于在自动驾驶汽车内部署深度学习算法的硬件解决方案的市场领导者是NVIDIA®。DRIVEPX(NVIDIA)是一款AI车载计算机,旨在使汽车制造商直接专注于AV的软件
DrivePX体系结构的最新版本基于两个Tegra X2(NVIDIA)片上系统(SoC)。每个SoC包含两个Denv(NVIDIA)内核,四个ARM A57内核以及一个Pascal(NVIDIA)一代的GPU。NVIDIA®DRIVEPX能够执行实时环境感知,路径规划和本地化。它结合了深度学习,传感器融合和环视技术,以改善驾驶体验。
NVIDIA®DRIVE AGX开发者平台于2018年9月推出,是基于Volta技术(NVIDIA)的世界上最先进的自动驾驶汽车平台(NVIDIA)。它具有两种不同的配置,分别是DRIVE AGX Xavier和DRIVE AGX Pegasus.
DRIVE AGX Xavier是一个可扩展的开放平台,可以充当自动驾驶车辆的AI大脑,并且是一种节能计算平台,每秒30万亿次操作,同时满足汽车标准,例如ISO 26262功能安全规范。NVIDIA®DRIVEAGX Pegasus通过基于两个NVIDIA®Xavier处理器和两个最先进的TensorCoreGPU的架构提高了性能。
汽车制造商用于ADAS的硬件平台是Renesas Autonomy(NVIDIA)的R‐Car V3H SoC平台。该SoC提供了以低功耗实现高性能计算机视觉的可能性。R‐Car V3H针对涉及立体摄像机,包含CNN专用硬件,密集光流,立体视觉和物体分类的应用进行了优化。硬件具有四个1.0 GHz ArmCortex-A53 MPCore内核,这使R-Car V3H成为合适的硬件平台,可用于部署训练有素的推理引擎来解决汽车领域内的特定深度学习任务。
瑞萨还提供了一种类似的SoC,称为R-Car H3(NVIDIA),可提供增强的计算功能并符合功能安全标准。与仅针对CNN进行了优化的R‐Car V3H相比,它配备了新的CPU内核(ArmCortex-A57),可用作部署各种深度学习算法的嵌入式平台
现场可编程门阵列(FPGA)是另一个可行的解决方案,在深度学习应用程序中显示出性能和功耗方面的显着改善。可以从四个主要角度分析FPGA在运行深度学习算法上的适用性:效率和功能,原始计算能力,灵活性和功能安全性。我们的研究基于英特尔(Nurvitadhi等,2017),微软(Ovtcharov等,2015)和UCLA(Cong等,2018)发表的研究。
通过减少深度学习应用程序中的延迟,FPGA提供了额外的原始计算能力。大量的芯片高速缓存存储器减少或消除了与外部存储器访问相关的存储器瓶颈。此外,FPGA的优势在于可以支持各种数据类型以及自定义的用户定义类型。FPGA在效率和功耗方面得到了优化。像Microsoft和Xilinx这样的制造商提供的研究表明,当以相同的计算复杂度处理算法时,GPU的功耗是FPGA的10倍,这表明FPGA可能是更适合汽车领域深度学习应用的解决方案。FPGA具有多种灵活性,具有灵活性,可将硬件可编程资源,数字信号处理器和处理器模块RAM(BRAM)组件组合在一起。这种架构灵活性适用于深度和稀疏的神经网络,这是当前机器学习应用程序的最新技术。另一个优点是可以连接到各种输入和输出外围设备,例如传感器,网络元素和存储设备
在汽车领域,功能安全是最重要的挑战之一。FPGA旨在满足包括ADAS在内的广泛应用的安全要求。与最初用于图形和高性能计算系统的GPU相比,在不需要功能安全的情况下,FPGA在开发驾驶员辅助系统方面具有显着优势
10、讨论和结论
我们已经确定了七个主要领域,这些领域在自动驾驶领域构成了开放的挑战。我们相信深度学习和AI将在克服这些挑战中发挥关键作用:
感知:为了使自动驾驶汽车能够安全地驾车行驶,它必须能够了解周围的环境。深度学习是大量感知系统背后的主要技术。尽管已报告了目标检测和识别准确性方面的巨大进步(Z.Q. Zhao,Zheng,Xu,&Wu,2018),但当前系统主要用于计算2D或3D边界框用于几个训练有素的对象类别,或提供驾驶环境的细分图像。未来的感知方法应着重于提高识别细节的水平,从而可以实时感知和跟踪更多物体。此外,还需要额外的工作来弥合基于图像和基于LiDAR的3D感知之间的差距(Wang等。,2019年),使计算机视觉社区能够结束当前关于摄像头与LiDAR作为主要感知传感器的争论。
短期到中期推理:除了强大且准确的感知系统之外,AV还应能够在短(毫秒)到中间(秒至分钟)的时间范围内推理其驾驶行为(Pendleton等,2017)。人工智能和深度学习是很有前途的工具,可用于导航各种驾驶场景所需的高低级路径规划。目前,无人驾驶汽车深度学习中的论文大部分都集中在感知和End2End学习上(Shalev‐Shwartz等人,2016; T.Zhang等人,2016)。在当地轨迹估计和规划领域发挥重要作用。我们认为导航系统提供的长期推理已解决。这些是通过道路网络选择从汽车当前位置到目的地的路线的标准方法(Pendleton等,2017)
训练数据的可用性:“数据就是新油”最近成为汽车行业最受欢迎的报价之一。深度学习系统的有效性与训练数据的可用性直接相关。根据经验,目前的深度学习方法也会根据训练数据的质量进行评估(Janai et al。,2017)。数据质量越好,算法的准确性就越高。AV记录的每日数据约为PB。这对培训程序的并行化以及存储基础架构都提出了挑战。最近几年已经使用了模拟环境,以弥合稀缺数据和深度学习的空白之间的差距。在模拟世界的准确性和现实世界的驾驶之间仍然存在差距。
学习特殊情况:大多数驾驶场景都可以用经典方法解决。然而,其余尚未解决的情况是一些极端情况,直到现在,这些情况仍需要驾驶员的理智和智慧。为了克服极端情况,应该提高深度学习算法的泛化能力。深度学习中的泛化在学习可能导致事故的危险情况时特别重要,特别是因为缺乏针对此类极端情况的培训数据。这也意味着可以减少训练实例数量的单发和低发学习方法的设计。
基于学习的控制方法:经典控制器使用由固定参数组成的先验模型。在诸如自动驾驶之类的复杂情况下,这些控制器无法预测所有驾驶情况。深度学习组件根据过去的经验来适应的有效性也可以用来学习汽车控制系统的参数,从而更好地近似底层的真实系统模型(Ostafew,2016; Ostafew等,2016)。
功能安全性:在安全关键型系统中使用深度学习仍然是一个公开辩论,并且正在努力使计算智能和功能安全社区彼此靠近。当前的安全标准(例如ISO 26262)不支持机器学习软件(Salay等人,2017)。尽管提出了新的数据驱动设计方法论,但在解释性,稳定性或分类稳健性方面仍然存在未解决的问题。
实时计算和通信:最后,必须满足实时要求,以处理从汽车传感器套件中收集的大量数据,以及通过高速通信线路更新深度学习系统的参数(Nurvitadhi等等人,2017)。这些实时约束可以通过自动驾驶汽车专用半导体芯片的进步以及5G通信网络的兴起得到支持
10.1、最后的笔记
在过去的十年中,视音频技术取得了飞速的发展,特别是由于AI和深度学习领域的进步。如今,在为自动驾驶汽车设计不同的组件时,当前的AI方法已被使用或考虑在内。深度学习方法不仅影响了传统的感知计划,动作管道的设计,而且还启用了End2End学习系统,能够将感觉信息直接映射到操纵命令。
无人驾驶汽车是复杂的系统,必须安全地将乘客或货物从出发地驾驶到目的地。在公共道路上基于AI的AV部署的出现遇到了几个挑战。鉴于当前的形式主义和神经网络的可解释性,一个主要的挑战是难以提高这些车辆的功能安全性。最重要的是,深度学习系统依赖于大型培训数据库,并需要大量的计算硬件。
本文对自动驾驶中使用的深度学习技术进行了调查。性能和计算要求的调查可为基于AI的自动驾驶汽车的系统级设计提供参考。
我的评价
在细分领域看来,本文讲的还是很粗略的。例如感知算法和数据集,其实都是一些基本的东西。但对我而言,control和safety是完全没有接触过的,对于这些领域,本文给出简单的综述以及文献,是一个想要了解这些领域的很好的开始。自动驾驶系统是一个庞大而复杂的系统,每个子系统也非常复杂,不可能用如此短的篇幅说清楚,但作者给出了发展的脉络和文献,对想要了解整个系统的人来说已经是非常好的一篇文献了。但如果是对于那些想跟进子领域的人来说,这篇文章有些泛了。