1.自定义指标-prometheus
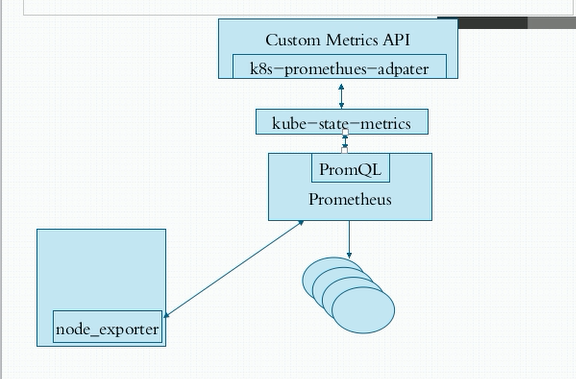
node_exporter是agent;PromQL相当于sql语句来查询数据;
k8s-prometheus-adapter:prometheus是不能直接解析k8s的指标的,需要借助k8s-prometheus-adapter转换成api;
kube-state-metrics是用来整合数据的.
访问:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
git clone https://github.com/iKubernetes/k8s-prom.git cd k8s-prom && kubectl apply -f namespace.yaml # 部署node_exporter cd node_exporter/ && kubectl apply -f . # 部署prometheus,注释掉资源限制limit, cd prometheus/ && vim prometheus-deploy.yaml && kubectl apply -f . #resources: # limits: # memory: 200Mi 这个pod没有部署好,prometheus就无法收集到数据,导致grafana界面没有数据,浪费了一天时间 kubectl get pods -n prom prometheus-server-64877844d4-gx4jr 1/1 Running 0 <invalid>
访问NodePort,访问prometheus

部署k8s-prometheus-adapter,需要自制证书
cd kube-state-metrics/ && kubectl apply -f .
cd /etc/kubernetes/pki/
(umask 077; openssl genrsa -out serving.key 2048)
openssl req -new -key serving.key -out serving.csr -subj "/CN=serving"
openssl x509 -req -in serving.csr -CA ./ca.crt -CAkey ./ca.key -CAcreateserial -out serving.crt -days 3650
# custom-metrics-apiserver-deployment.yaml会用到secretName: cm-adapter-serving-certs
kubectl create secret generic cm-adapter-serving-certs --from-file=serving.crt=./serving.crt --from-file=serving.key=./serving.key -n prom
# 部署k8s-prometheus-adapter,由于版本问题,需要下载两个文件,将两个文件中的名称空间改为prom
cd k8s-prometheus-adapter/
mv custom-metrics-apiserver-deployment.yaml ..
wget https://raw.githubusercontent.com/DirectXMan12/k8s-prometheus-adapter/master/deploy/manifests/custom-metrics-apiserver-deployment.yam
wget https://raw.githubusercontent.com/DirectXMan12/k8s-prometheus-adapter/master/deploy/manifests/custom-metrics-config-map.yaml
kubectl apply -f .
kubectl api-versions # 必须出现这个api,并且开启代理可以访问到数据
custom.metrics.k8s.io/v1beta1
kubectl proxy --port=8080
curl http://localhost:8080/apis/custom.metrics.k8s.io/v1beta1/
# prometheus和grafana整合
wget https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/influxdb/grafana.yaml
把namespace: kube-system改成prom,有两处;
把env里面的下面两个注释掉:
- name: INFLUXDB_HOST
value: monitoring-influxdb
在最有一行加个type: NodePort
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort
kubectl apply -f grafana.yaml
kubectl get svc -n prom
monitoring-grafana NodePort 10.96.228.0 <none> 80:30336/TCP 13h
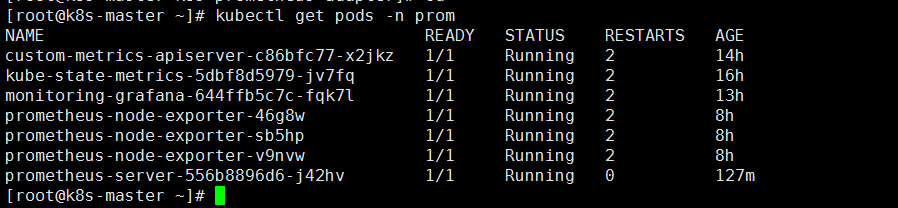
prom名称空间内的所有pod
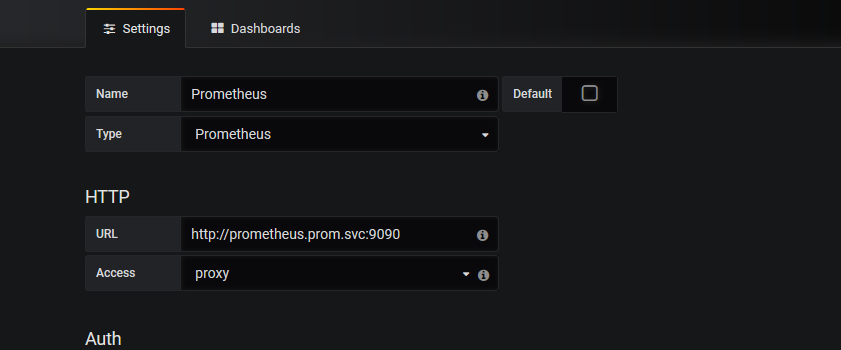
访问:10.0.0.20:30336
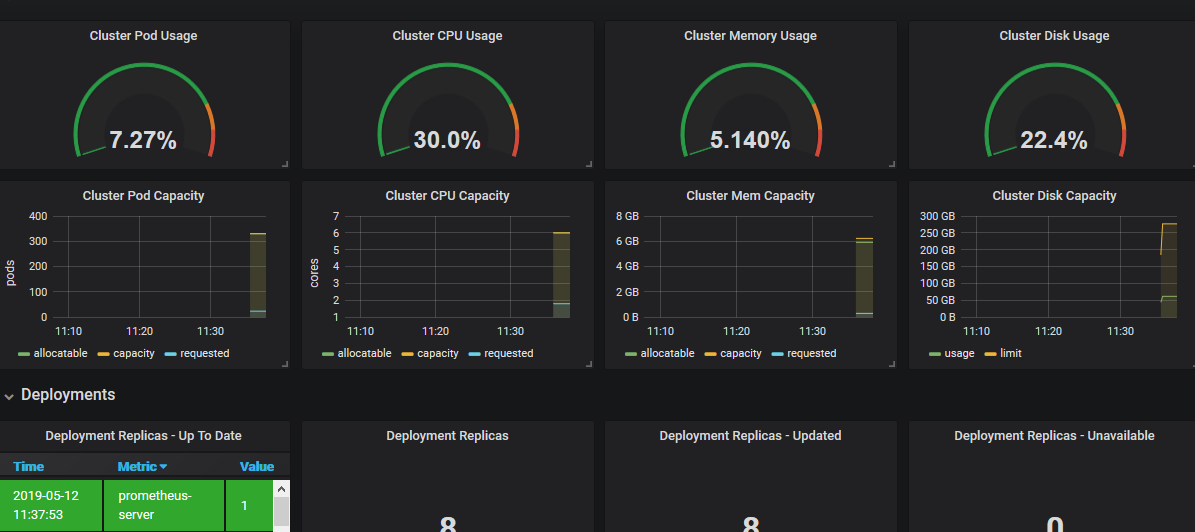
两个k8s模板:https://grafana.com/dashboards/6417 https://grafana.com/dashboards/315

一切顺利的话,立马就能看到监控数据
2.HPA(水平pod自动扩展)
当pod压力大了,会根据负载自动扩展Pod个数以缓解压力
kubectl api-versions |grep auto
创建一个带有资源限制的pod
kubectl run myapp --image=ikubernetes/myapp:v1 --replicas=1 \
--requests='cpu=50m,memory=256Mi' --limits='cpu=50m,memory=256Mi' \
--labels='app=myapp' --expose --port=80
# 让myapp这个控制器支持自动扩展,--cpu-percent表示cpu超过这个值就开始扩展
kubectl autoscale deployment myapp --min=1 --max=5 --cpu-percent=60
kubectl get hpa
# 对pod进行压力测试
kubectl patch svc myapp -p '{"spec":{"type": "NodePort"}}'
yum install httpd-tools
# 随着cpu压力的上升,会看到自动扩展为4个或更多的pod
ab -c 1000 -n 5000000 http://172.16.1.100:31990/index.html
# hpa v1版本只能根据cpu利用率扩展pod,hpa v2可以根据自定义指标利用率水平扩展pod
kubectl delete hpa myapp
cat hpa-v2-demo.yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-v2
spec:
scaleTargetRef: # 根据什么指标来做评估压力
apiVersion: apps/v1
kind: Deployment
name: myapp # 对哪个控制器做自动扩展
minReplicas: 1
maxReplicas: 10
metrics: # 依据哪些指标来进行评估
- type: Resource # 基于资源进行评估
resource:
name: cpu
targetAverageUtilization: 55 # cpu使用率超过55%,就自动水平扩展pod个数
- type: Resource
resource:
name: memory # v2版可以根据内存进行评估
targetAverageValue: 50Mi # 内存使用超过50M,就自动水平扩展pod个数
kubectl apply -f hpa-v2-demo.yaml
# 进行压测即可看到pod会自动扩展
# 自定义的资源指标,pod被开发好之后,得支持这些指标,否则就是白写
# 下面这个例子中支持并发参数的镜像地址:https://hub.docker.com/r/ikubernetes/metrics-app/
cat hpa-v2-custom.yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-v2
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods # 利用pod中定义的指标进行扩缩
pods:
metricName: http_requests # 自定义的资源指标
targetAverageValue: 800m # m表示个数,并发数800
参考博客:http://blog.itpub.net/28916011/viewspace-2216340/
prometheus监控mysql、k8s:https://www.cnblogs.com/sfnz/p/6566951.html