一、版本要求
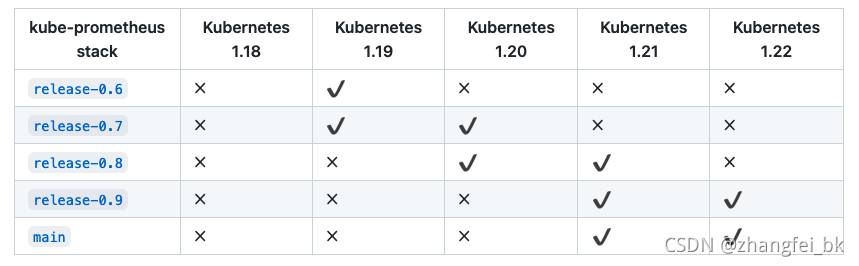
结合上图选择release-0.9版本。
二、下载资源
2.1下载安装包
github网站地址:https://github.com/prometheus-operator/kube-prometheus
下载安装包:
wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.9.0.zip
解压:
unzip v0.9.0.zip
进入解压目录:
cd kube-prometheus-0.9.0
查看需要的镜像:
find ./manifests/ -type f |xargs grep 'image: '|sort|uniq|awk '{print $3}'|grep ^[a-zA-Z]|grep -Evw 'error|kubeRbacProxy'|sort -rn|uniq
[root@node2 kube-prometheus-0.9.0]# find ./manifests/ -type f |xargs grep 'image: '|sort|uniq|awk '{print $3}'|grep ^[a-zA-Z]|grep -Evw 'error|kubeRbacProxy'|sort -rn|uniq
quay.io/prometheus/prometheus:v2.29.1
quay.io/prometheus-operator/prometheus-operator:v0.49.0
quay.io/prometheus/node-exporter:v1.2.2
quay.io/prometheus/blackbox-exporter:v0.19.0
quay.io/prometheus/alertmanager:v0.22.2
quay.io/brancz/kube-rbac-proxy:v0.11.0
k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.0
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.1.1
jimmidyson/configmap-reload:v0.5.0
grafana/grafana:8.1.1
[root@node2 kube-prometheus-0.9.0]#
2.2准备镜像(每个节点都操作一遍)
由于k8s.gcr.io下的国外镜像是无法直接下载的,所以需要提前准备一下。我把这两个镜像上传到了docker hub上面。
拉取这两个镜像:
docker pull zfhub/prometheus-adapter:v0.9.0
docker pull zfhub/kube-state-metrics:v2.1.1
给镜像打tag:
docker tag zfhub/prometheus-adapter:v0.9.0 k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.0
docker tag zfhub/kube-state-metrics:v2.1.1 k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.1.1
操作流程:
[root@node2 kube-prometheus-0.9.0]# docker pull zfhub/prometheus-adapter:v0.9.0
v0.9.0: Pulling from zfhub/prometheus-adapter
0d7d70899875: Pull complete
9101555ad5ba: Pull complete
Digest: sha256:2ffef2ecfa11f052de52a214ff17dc8209d168a9aeb9f3ab74c238308524caf4
Status: Downloaded newer image for zfhub/prometheus-adapter:v0.9.0
docker.io/zfhub/prometheus-adapter:v0.9.0
[root@node2 kube-prometheus-0.9.0]# docker pull zfhub/kube-state-metrics:v2.1.1
v2.1.1: Pulling from zfhub/kube-state-metrics
0d7d70899875: Already exists
782dbf431fc7: Pulling fs layer
v2.1.1: Pulling from zfhub/kube-state-metrics
0d7d70899875: Already exists
782dbf431fc7: Pull complete
Digest: sha256:102c4adb2e8935e8e9d09419fc06e6eedcb5c4a8529c9557ce40e0a4a437287e
Status: Downloaded newer image for zfhub/kube-state-metrics:v2.1.1
docker.io/zfhub/kube-state-metrics:v2.1.1
[root@node2 kube-prometheus-0.9.0]# docker tag zfhub/prometheus-adapter:v0.9.0 k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.0
[root@node2 kube-prometheus-0.9.0]# docker tag zfhub/kube-state-metrics:v2.1.1 k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.1.1
[root@node2 kube-prometheus-0.9.0]#
下载其它镜像:
docker pull quay.io/prometheus/prometheus:v2.29.1
docker pull quay.io/prometheus-operator/prometheus-operator:v0.49.0
docker pull quay.io/prometheus/node-exporter:v1.2.2
docker pull quay.io/prometheus/blackbox-exporter:v0.19.0
docker pull quay.io/prometheus/alertmanager:v0.22.2
docker pull quay.io/brancz/kube-rbac-proxy:v0.11.0
docker pull jimmidyson/configmap-reload:v0.5.0
docker pull grafana/grafana:8.1.1
三、创建所有服务
创建:
kubectl create -f manifests/setup
kubectl create -f manifests/
查看:
扫描二维码关注公众号,回复:
15416431 查看本文章

kubectl -n monitoring get all
[root@node2 kube-prometheus-0.9.0]# kubectl -n monitoring get all
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 1/2 Running 0 51s
pod/alertmanager-main-1 1/2 Running 0 50s
pod/alertmanager-main-2 1/2 Running 0 49s
pod/blackbox-exporter-6798fb5bb4-62ng4 3/3 Running 0 51s
pod/grafana-7476b4c65b-9sf6g 1/1 Running 0 48s
pod/kube-state-metrics-74964b6cd4-j277l 3/3 Running 0 48s
pod/node-exporter-fg5g5 2/2 Running 0 48s
pod/node-exporter-ft8w7 2/2 Running 0 48s
pod/node-exporter-h66h5 2/2 Running 0 48s
pod/prometheus-adapter-5b8db7955f-6wn2z 1/1 Running 0 47s
pod/prometheus-adapter-5b8db7955f-7nklc 1/1 Running 0 47s
pod/prometheus-k8s-0 2/2 Running 0 44s
pod/prometheus-k8s-1 2/2 Running 0 44s
pod/prometheus-operator-75d9b475d9-4n2cs 2/2 Running 0 65s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.1.122.158 <none> 9093/TCP 52s
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 52s
service/blackbox-exporter ClusterIP 10.1.228.67 <none> 9115/TCP,19115/TCP 52s
service/grafana ClusterIP 10.1.164.198 <none> 3000/TCP 49s
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 48s
service/node-exporter ClusterIP None <none> 9100/TCP 48s
service/prometheus-adapter ClusterIP 10.1.152.248 <none> 443/TCP 47s
service/prometheus-k8s ClusterIP 10.1.61.120 <none> 9090/TCP 46s
service/prometheus-operated ClusterIP None <none> 9090/TCP 45s
service/prometheus-operator ClusterIP None <none> 8443/TCP 65s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/node-exporter 3 3 3 3 3 kubernetes.io/os=linux 48s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/blackbox-exporter 1/1 1 1 52s
deployment.apps/grafana 1/1 1 1 49s
deployment.apps/kube-state-metrics 1/1 1 1 48s
deployment.apps/prometheus-adapter 2/2 2 2 47s
deployment.apps/prometheus-operator 1/1 1 1 65s
NAME DESIRED CURRENT READY AGE
replicaset.apps/blackbox-exporter-6798fb5bb4 1 1 1 52s
replicaset.apps/grafana-7476b4c65b 1 1 1 49s
replicaset.apps/kube-state-metrics-74964b6cd4 1 1 1 48s
replicaset.apps/prometheus-adapter-5b8db7955f 2 2 2 47s
replicaset.apps/prometheus-operator-75d9b475d9 1 1 1 65s
NAME READY AGE
statefulset.apps/alertmanager-main 0/3 52s
statefulset.apps/prometheus-k8s 2/2 45s
[root@node2 kube-prometheus-0.9.0]#
⚠️⚠️⚠️ 清空上面服务的命令:
kubectl delete -f manifests/
kubectl delete -f manifests/setup/
四、访问下prometheus的UI
修改下prometheus UI的service模式,便于我们访问
kubectl -n monitoring patch svc prometheus-k8s -p '{"spec":{"type":"NodePort"}}'
获取prometheus-k8s对应service的ip:
kubectl get svc prometheus-k8s -n monitoring
[root@node2 kube-prometheus-0.9.0]# kubectl get svc prometheus-k8s -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-k8s NodePort 10.1.61.120 <none> 9090:32217/TCP 28m
[root@node2 kube-prometheus-0.9.0]#
访问http://node2(ip):32217(端口改成自己service对应的端口):
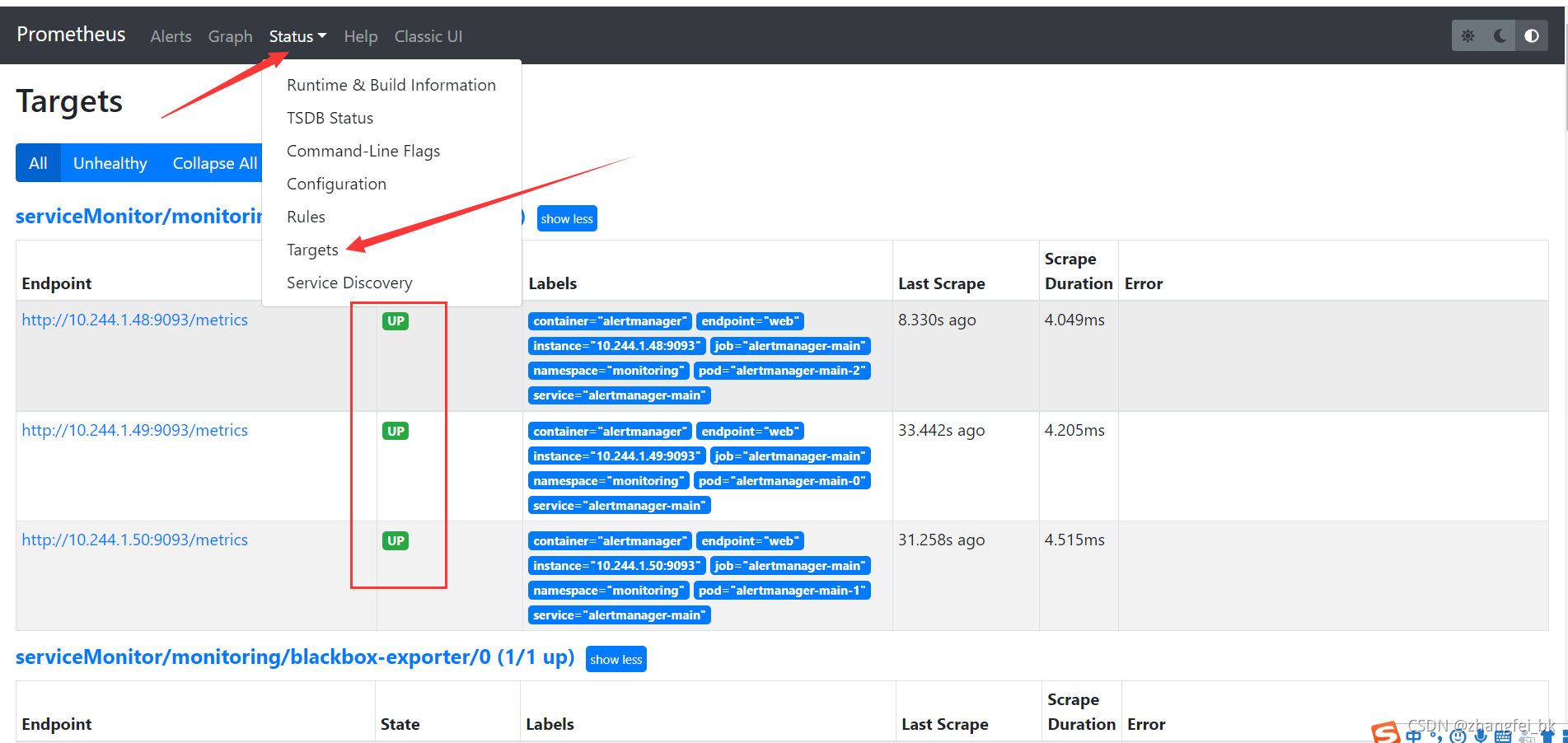
点击Status下的Targets可以看到全部资源都处于UP状态,说明成功监控到了:
修改grafana服务的类型为nodeport用于前端访问:
kubectl -n monitoring patch svc grafana -p '{"spec":{"type":"NodePort"}}'
workflow@Slave2:/home/scidb/k8s_workplace/test/kube-prometheus-0.9.0$ kubectl -n monitoring patch svc grafana -p '{"spec":{"type":"NodePort"}}'
service/grafana patched
workflow@Slave2:/home/scidb/k8s_workplace/test/kube-prometheus-0.9.0$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.109.119.14 <none> 9093/TCP 38m
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 38m
blackbox-exporter ClusterIP 10.96.210.40 <none> 9115/TCP,19115/TCP 38m
grafana NodePort 10.109.219.216 <none> 3000:31509/TCP 38m
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 38m
node-exporter ClusterIP None <none> 9100/TCP 38m
prometheus-adapter ClusterIP 10.103.145.156 <none> 443/TCP 38m
prometheus-k8s NodePort 10.105.178.138 <none> 9090:31326/TCP 38m
prometheus-operated ClusterIP None <none> 9090/TCP 37m
prometheus-operator ClusterIP None <none> 8443/TCP 38m
workflow@Slave2:/home/scidb/k8s_workplace/test/kube-prometheus-0.9.0$
访问http://node2(ip):31509(端口改成自己service对应的端口),账号名和密码都是admin: