PCA计算的起点是协方差矩阵,方差描述的是一群点偏离均值的程度(偏离度(平方)的均值/期望),标准差是方差的标准化,具有与原数据一样的单位/量纲。协方差描述的是两个变量之间的协同关系(两个变量与其各自均值的协变度),是相关性系数的前体(除以两个变量的标准差后就是相关性系数)。
协方差公式简单,但却有许多惊奇的特性,它居然可以描述两个变量的协同变化程度。协方差矩阵更是计算生物学的利器(协方差矩阵有什么意义?),很多工具分析的起点。
在统计学与概率论中,协方差矩阵(也称离差矩阵、方差-协方差矩阵)是一个矩阵,其 i, j 位置的元素是第 i 个与第 j 个随机向量(即随机变量构成的向量)之间的协方差。这是从标量随机变量到高维度随机向量的自然推广。
假设X是以n个随机变数组成的列向量,
X=1
2
3
4
矩阵中的第个(i,j)元素是xi与xj的协方差。这个概念是对于标量随机变数方差的一般化推广。
尽管协方差矩阵很简单,可它却是很多领域里的非常有力的工具。它能导出一个变换矩阵,这个矩阵能使数据完全去相关(decorrelation)。从不同的角度看,也就是说能够找出一组最佳的基以紧凑的方式来表达数据。(完整的证明请参考瑞利商)。这个方法在统计学中被称为主成分分析(principal components analysis),在图像处理中称为Karhunen-Loève 变换(KL-变换)。
如果有n阶矩阵A,其矩阵的元素都为实数,且矩阵A的转置等于其本身(aij=aji)(i,j为元素的脚标),则称A为实对称矩阵。
主要性质:
1.实对称矩阵A的不同特征值对应的特征向量是正交的。
2.实对称矩阵A的特征值都是实数,特征向量都是实向量。
3.n阶实对称矩阵A必可对角化,且相似对角阵上的元素即为矩阵本身特征值。
4.若λ0具有k重特征值 必有k个线性无关的特征向量,或者说必有秩r(λ0E-A)=n-k,其中E为单位矩阵。
三、协方差
描述两个变量的相关性
Cov=E[X−E(X)][Y−E(Y)]
相关系数 如果ρ XY=0, 两个变量不相关
四、协方差矩阵
矩阵其实就是一种将某个向量变换为另一个的方法,另外我们也可以将矩阵看作作用于所有数据并朝向某个方向的力【特征值:伸缩常数】。
同时我们还知道了变量间的相关性可以由方差和协方差表达,并且我们希望保留最大方差以实现最优的降维。因此我们希望能将方差和协方差统一表示,并且两者均可以表示为内积的形式,而内积又与矩阵乘法密切相关。因此我们可以采用矩阵乘法的形式表示。若输入矩阵 X 有两个特征 a 和 b,且共有 m 个样本,那么有:
如果我们用 X 左乘 X 的转置,那么就可以得出协方差矩阵:
这个矩阵对角线上的两个元素分别是两特征的【方差】,而其它元素是 a 和 b 的【协方差】。两者被统一到了一个矩阵的,因此我们可以利用协方差矩阵描述数据点之间的方差和协方差,即经验性地描述我们观察到的数据。
我们知道,矩阵乘法对应了一个变换,是把任意一个向量变成另一个方向或长度都大多不同的新向量。在这个变换的过程中,原向量主要发生旋转、伸缩的变化。如果矩阵对某一个向量或某些向量只发生伸缩变换,不对这些向量产生旋转的效果,那么这些向量就称为这个矩阵的特征向量,伸缩的比例就是特征值。特征向量在一个矩阵的作用下作伸缩运动,伸缩的幅度由特征值确定。特征值大于1,所有属于此特征值的特征向量身形暴长;特征值大于0小于1,特征向量身形猛缩;特征值小于0,特征向量缩过了界,反方向到0点那边去了。
关于特征值和特征向量,这里请注意两个亮点。这两个亮点一个是线性不变量的含义,二个是振动的谱含义。
“特征向量”的向量特殊,在矩阵作用下不变方向只变长度。不变方向的特性就被称为线性不变量。有网友说不变量实际是特征空间的不变性,特征值再怎么变也不会离开特征空间,这个说法应是正解,因为这同时解释了复数矩阵,大赞。
…
在i,j下面有个 v={i,j} :可以观察到,调整后的 v 和 Av 在同一根直线上,只是 Av 的长度相对 v 的长度变长了。
此时,我们就称 v 是A 的特征向量,而 Av 的长度是 v 的长度的 λ 倍, λ 就是特征值。
如果把矩阵看作是运动,那么特征值就是运动的速度,特征向量就是运动的方向。
加入A为两列的矩阵如下,{1,3}为a1点,{2,4}为a2点。如下:
{1,2}
{3,4}
v也是一个点记为列的形式:
{5}
{6}
或者{5,6}
则Av就是v的变换后的点。
…
协方差
在百度百科上,协方差是被这样定义的,协方差在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
首先,我们来看一下协方差的计算公式:
Cov=E[X−E(X)][Y−E(Y)]
从公式上看,协方差是两个变量与自身期望做差再相乘,然后对乘积取期望。也就是说,当其中一个变量的取值大于自身期望,另一个变量的取值也大于自身期望时,即两个变量的变化趋势相同,此时,两个变量之间的协方差取正值。反之,即其中一个变量大于自身期望时,另外一个变量小于自身期望,那么这两个变量之间的协方差取负值。
正如上图所示,当x与y变化趋势一致时,两个变量与自身期望之差同为正或同为负,其乘积必然为正,所以其协方差为正;反之,其协方差为负。所以协方差的正负性反映了两个变量的变化趋势是否一致。
再者,当x和y在某些时刻变化一致,某些时刻变化不一致时,如下图所示,在第一个点,x与y虽然变化,但是y的变化幅度远不及x变化幅度大,所以其乘积必然较小,在第二个点,x与y变化一致且变化幅度都很大,因此其乘积必然较大,在第三个点,x与y变化相反,其乘积为负值,这类点将使其协方差变小,因此,我们可以认为协方差绝对值大小反映了两个变量变化的一致程度。
因此,两个变量相关系数的定义为协方差与变量标准差乘积之比。
总的来说,协方差反映了两个变量之间的相关程度。
协方差矩阵
在现实生活中,我们在描述一个物体时,并不会单单从一个或两个维度去描述,比如说,在描述一个学生的学习成绩时,就会从他的语文、数学、英语、物理、化学等等很多个维度去描述。在进行多维数据分析时,不同维度之间的相关程度就需要协方差矩阵来描述,维度之间的两两相关程度就构成了协方差矩阵,而协方差矩阵主对角线上的元素即为每个维度上的数据方差。
对于2维的数据,任意两个维度之间求其协方差,我们可以得到
(xx)(xy)(yx)(yy)
,这4个协方差(方差可以理解成特殊的协方差)就构成了协方差矩阵。
(xx)(xy)
(yx)(yy)
如果说x与y是正相关关系,即y必然随着x的增加而增加,同样x也随着y的增加而增加,即y与x呈正相关关系,所以有
(xy)=(yx)
,因此协方差矩阵必然是一个实对称矩阵,其主对角线元素为方差,其余为协方差。接下来我们从2维数据分布情况,来看协方差矩阵的几何意义。
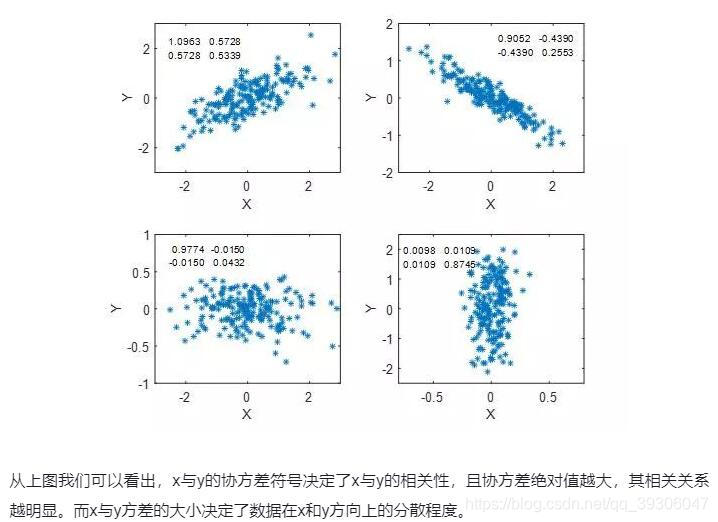
从上图我们可以看出,x与y的协方差符号决定了x与y的相关性,且协方差绝对值越大,其相关关系越明显。而x与y方差的大小决定了数据在x和y方向上的分散程度。
协方差矩阵的特征分解
上文中,我们解释了协方差代表了不同维度之间的相关关系,如果说某些维度之间没有相关关系,则协方差为0,那么,以2维数据为例,我们来看一下,当不同维度之间数据没有相关关系时,即协方差矩阵为单位阵时,数据分布的整体形状。
当数据协方差矩阵为单位阵时,该组数据被称为白数据,白数据在很多场合都有应用,比如在数据传输加密中,将原始数据转化成白数据,切断不同维度之间的关联关系,在访问数据时,再对数据进行解密。现在我们一起来看一下,怎么将白数据转化成真实观察数据的线性变换。
协方差矩阵表示了不同方向上数据分布的离散程度,现在我们试图用一个向量和一个数字来表示协方差矩阵,向量应该指向数据分布最离散的方向,而这个数应该是该方向上数据投影的方差。
x是一个非零向量,A是一个实对称矩阵。瑞利熵有一个非常重要的性质,即它的最大值等于矩阵A最大的特征值,而最小值等于矩阵A的最小的特征值.
可以得出,协方差矩阵最大特征值所对应的特征向量指向方差最大的方向,在该方向上数据投影方差的大小即为特征值。方差第二大方向即为第二大特征方向,因为协方差矩阵为实对称矩阵,该方向与第一特征方向垂直。
上图中,协方差矩阵的特征值分别为25和1,特征值表示特征向量方向的数据方差,协方差矩阵中的主对角元素表示沿x和y轴方向的方差分量。
首先本文的特征向量是数学概念上的特征向量,并不是指由输入特征值所组成的向量。数学上,线性变换的特征向量是一个非简并的向量,其方向在该变换下不变。该向量在此变换下缩放的比例称为特征值。一个线性变换通常可以由其特征值和特征向量完全描述。如果我们将矩阵看作物理运动,那么最重要的就是运动方向(特征向量)和速度(特征值)。因为物理运动只需要方向和速度就可以描述,同理矩阵也可以仅使用特征向量和特征值描述。
矩阵运算的法则和实际内部的值并没有什么关系,只不过定义了在运算时哪些位置需要进行哪些操作。因为矩阵相当于定义了一系列运算法则的表格,那么其实它就相当于一个变换,这个变换(物理运动)可以由特征向量(方向)和特征值(速度)完全描述出来。
线性变换
在解释线性变换前,我们需要先了解矩阵运算到底是什么。因为我们可以对矩阵中的值统一进行如加法或乘法等运算,所以矩阵是十分高效和有用的。
如下所示,如果我们将向量 v 左乘矩阵 A,我们就会得到新的向量 b,也即可以表述说矩阵 A 对输入向量 v 执行了一次线性变换,且线性变换结果为 b。因此矩阵运算 Av = b 就代表向量 v 通过一个变换(矩阵 A)得到向量 b。下面的实例展示了矩阵乘法(该类型的乘法称之为点积)是怎样进行的:
A v b
{2 1} 0.75 1.75
{1.5 2} 0.25 1.625
所以矩阵 A 将向量 v 变换为向量 b。下图展示了矩阵 A 如何将更短更低的向量 v 映射到更长更高的向量 b:
我们可以馈送其他正向量到矩阵 A 中,每一个馈送的向量都会投影到新的空间中且向右边变得更高更长。
假定所有的输入向量 V 可以排列为一个标准表格,即:
而矩阵可以将所有的输入向量 V 投影为如下所示的新空间,也即所有输出向量组成的 B:
下图可以看到输入向量空间和输出向量空间的关系,
如果假设矩阵就是一阵风,它通过有形的力量得出可见的结果。而这一阵风所吹向的方向就是特征向量,因此特征向量就表明矩阵所要变换的方向。
如上图所示,特征向量并不会改变方向,它已经指向了矩阵想要将所有输入向量都推向的方向。因此,特征向量的数学定义为:存在非零矩阵 A 和标量λ,若有向量 x 且满足以下关系式,那么 x 就为特征向量、λ为特征值。
Ax=λx
【特征向量x同样是线性变换的不变轴(x不变),所有输入向量沿着这条轴压缩或延伸。线性变换中的线性正是表明了这种沿直线轴进行变换的特性】一般来说几阶方阵就有几个特征向量,如 3*3 矩阵有 3 个特征向量,n 阶方阵有 n 个特征向量,每一个特征向量表征一个维度上的线性变换方向。
因为特征向量提取出了矩阵变换的主要信息,因此它在矩阵分解中十分重要,即【沿着特征向量对角化矩阵】。因为这些特征向量表征着矩阵的重要特性,所以它们可以执行与深度神经网络中自编码器相类似的任务。引用 Yoshua Bengio 的话来说:
矩阵分解最常见的是特征分解(eigen-decomposition),即我们将矩阵分解为一系列的特征向量和特征值。
主成分分析(PCA)
PCA 是一种寻找高维数据(图像等)模式的工具。机器学习实践上经常使用 PCA 对输入神经网络的数据进行预处理。通过聚集、旋转和缩放数据,PCA 算法可以去除一些低方差的维度而达到降维的效果,这样操作能提升神经网络的收敛速度和整体效果。
因为样本标准差和方差都是先求距离的平方再求平方根,因此距离一定是正数且不会抵消。假设我们有如下数据点(散点图):
PCA 如线性回归那样会尝试构建一条可解释性的直线贯穿所有数据点。每一条直线表示一个「主成分」或表示自变量和因变量间的关系。数据的维度数就是主成分的数量,也即每一个数据点的特征维度。PCA 的作用就是分析这些特征,并选出最重要的特征。PCA 本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据「去相关」,也就是让它们在不同正交方向上没有相关性。通常我们认为信息具有较大的方差,而噪声有较小的方差,信噪比就是信号与噪声的方差比,所以我们希望投影后的数据方差越大越好。因此我们认为,最好的 k 维特征是将 n 维样本点转换为 k 维后,每一维上的样本方差都很大。
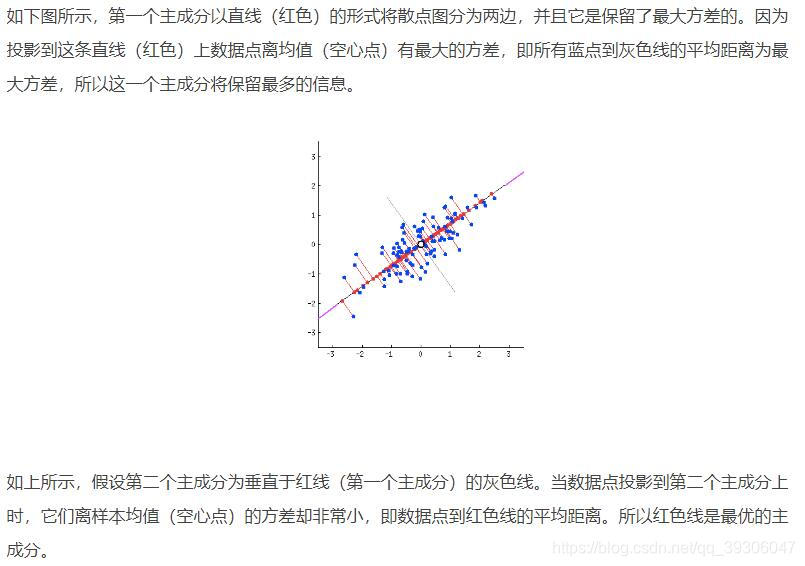
如下图所示,第一个主成分以直线(红色)的形式将散点图分为两边,并且它是保留了最大方差的。因为投影到这条直线(红色)上数据点离均值(空心点)有最大的方差,即所有蓝点到灰色线的平均距离为最大方差,所以这一个主成分将保留最多的信息。
如上所示,假设第二个主成分为垂直于红线(第一个主成分)的灰色线。当数据点投影到第二个主成分上时,它们离样本均值(空心点)的方差却非常小,即数据点到红色线的平均距离。所以红色线是最优的主成分。
协方差矩阵
前面我们已经了解矩阵其实就是一种将某个向量变换为另一个的方法,另外我们也可以将矩阵看作作用于所有数据并朝向某个方向的力。同时我们还知道了变量间的相关性可以由方差和协方差表达,并且我们希望保留最大方差以实现最优的降维。因此我们希望能将方差和协方差统一表示,并且两者均可以表示为内积的形式,而内积又与矩阵乘法密切相关。因此我们可以采用矩阵乘法的形式表示。若输入矩阵 X 有两个特征 a 和 b,且共有 m 个样本,那么有:
如果我们用 X 左乘 X 的转置,那么就可以得出协方差矩阵:
这个矩阵对角线上的两个元素分别是两特征的方差,而其它元素是 a 和 b 的协方差。两者被统一到了一个矩阵的,因此我们可以利用协方差矩阵描述数据点之间的方差和协方差,即经验性地描述我们观察到的数据。
寻找协方差矩阵的特征向量和特征值就等价于拟合一条能保留最大方差的直线或主成分。因为特征向量追踪到了主成分的方向,而最大方差和协方差的轴线表明了数据最容易改变的方向。根据上述推导,我们发现达到优化目标就等价于将协方差矩阵对角化:即除对角线外的其它元素化为 0,并且在对角线上将特征值按大小从上到下排列。协方差矩阵作为实对称矩阵,其主要性质之一就是可以正交对角化,因此就一定可以分解为特征向量和特征值。
当协方差矩阵分解为特征向量和特征值之后,特征向量表示着变换方向,而特征值表示着伸缩尺度。在本例中,特征值描述着数据间的协方差。我们可以按照特征值的大小降序排列特征向量,如此我们就按照重要性的次序得到了主成分排列。
对于 2 阶方阵,一个协方差矩阵可能如下所示:
3 1
1 2
在上面的协方差矩阵中,3(xx) 和 2(yy) 分别代表变量 x 和变量 y 的方差,而副对角线上的 0.63 代表着变量 x 和 y 之间的协方差。因为协方差【xy=yx】矩阵为实对称矩阵(即 Aij=Aji),所以其必定可以通过正交化相似对角化。因为这两个变量的协方差为正值,所以这两个变量的分布成正相关性。如下图所示,如果协方差为负值,那么变量间就成负相关性。
注意如果变量间的协方差为零,那么变量是没有相关性的,并且也没有线性关系。因此,【如果两个变量的协方差越大,相关性越大】,投影到主成分后的损失就越小。我们同时可以考虑协方差和方差的计算式而了解他们的关系:
计算协方差的优处在于我们可以通过协方差的正值、负值或零值考察两个变量在高维空间中相互关系。
总的来说,协方差矩阵定义了数据的形状,协方差决定了沿对角线对称分布的强度【协方差越大,相关性越大】,而方差决定了沿 x 轴或 y 轴对称分布的趋势【方差就是xx和yy,在协方差为0时候那个大那个就离散分布广】。
基变换
因为协方差矩阵的特征向量都是彼此正交的,所以变换就相当于将 x 轴和 y 轴两个基轴换为主成分一个基轴。也就是将数据集的坐标系重新变换为由主成分作为基轴的新空间,当然这些主成分都保留了最大的方差。
我们上面所述的 x 轴和 y 轴称之为矩阵的基,即矩阵所有的值都是在这两个基上度量【变换,就是特征向量变换而来】而来的。但矩阵的基【就是原来的矩阵通过特征向量来变成新的矩阵。就相当于矩阵旋转了角度得到新的坐标矩阵】是可以改变的,通常一组特征向量就可以组成该矩阵一组不同的基坐标,原矩阵的元素可以在这一组新的基中表达。
在上图中,我们展示了相同向量 v 如何在不同的坐标系中有不同的表达。黑色实线代表 x-y 轴坐标系而红色虚线是另外一个坐标系。在第一个坐标系中 v = (1,1),而在第二个坐标系中 v = (1,0)。因此矩阵和向量可以在不同坐标系中等价变换。在数学上,n 维空间并没有唯一的描述,所以等价转换矩阵的基也许可以令问题更容易解决。
最后我们简单地总结一下 PCA 算法的基本概念和步骤:
首先我们得理解矩阵就相当于一个变换,变换的方向为特征向量,变换的尺度为特征值。PCA 的本质是将方差最大的方向作为主要特征,并且在各个正交方向上将数据「去相关」,即让它们在不同正交方向上没有相关性。所以我们希望将最相关的特征投影到一个主成分上而达到降维的效果,投影的标准是保留最大方差。而在实际操作中,我们希望计算特征之间的协方差矩阵,并通过对协方差矩阵的特征分解而得出特征向量和特征值。如果我们将特征值由大到小排列,相对应的特征向量所组成的矩阵就是我们所需降维后的数据。下面我们将一步步实现 PCA 算法。