聚类算法
聚类算法是一种非监督学习算法,根据数据集的分布特征,将其聚集为相互比较近的多个集合,集合的数量通常指定。
经典算法 k-means
k-means是经典的聚类算法,其算法流程如下:
- 随机或者有区分的选取k个点作为k个种类的中心
- 分别计算所有点到每个中心的距离,并将其归入最近的类
- 再次计算每个类中所有点的平均中心
- 将每个类的中心位置更新,重复2,3直到每个点的所属类不在变化,或者达到设定的条件
例如下图:
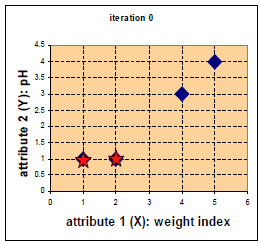
从左到右依次给点编号为1,2,3,4,最开始选取1,2为两类的中心,则计算的
第一类:1
第二类:2,3,4
从新计算第二类的中心,由于其有三个点,其平均位置向右上方移动,第二个点离中心边远。因此第二次计算后分类为
第一类:1,2
第二类:3,4
从新计算中心,每个点的所属类都不在变化,算法结束
从上面可以看出,该算法相对简单,但是容易陷入局部最优,对于初始的每个类的中心的选择具有比较大的依赖
hierarchical cluster算法,层次聚类
算法流程:
共计k个点
- 对所有的数据点,每个点当做一个类,依次计算其量量之间的距离
- 将相邻最近的类归为一类,总类数减少为k-1
- 持续进行上述过程,直到达到结束标准
算法特点:
- 对于不知道预先有几个类的情况有比较好的表现
- 两个类之间的距离的计算有多种方法,
- 计算两个类中最近两个点的距离,容易让两个近点将离得很远的点聚合到一起
- 计算两个类中最远两个点的距离,容易让两个本来应该聚合的类因为特殊点很难聚合
- 两辆求距离获得平均值。