机器学习(九)--聚类
基于不同的聚类规则会有不同的方法,那么常见的有基于哪一些聚类呢?
- 基于距离的聚类
- 基于密度的聚类
- 基于网格的聚类
基于距离的聚类,我们先看下有多少种衡量距离的方法(具体的方法原理大家可以去查找相关的书籍)
- 绝对值距离
- 欧氏距离
- 闵可夫斯基距离
- 切比雪夫距离
- 马氏距离
- Lance和Williams距离
- 离散变量的距离计算
在聚类之前我们要进行数据中心化和标准化变换,方便使到各个变量平等地发挥作用。所谓中心化简单来说就是特征均值为0,标准化就是除标准差(还有一个极差标准化)
基于距离的聚类
- 层次聚类法
层次聚类法应用还是非常广泛的,大家可以看下图,原理都是层次聚类法实现的


层次聚类的思想是怎么样的呢?
难点1,如何计算类与类之间的距离?
各种类与类之间距离计算的方法
- 最短距离法
- 最长距离法
- 中间距离法
- 类平均法
- 重心法
- 离差平方和法
难点2,分成几类?
自己指定,要看经验,目前还没有很好的方法
- 动态聚类:K-means(K-均值)方法
算法思想

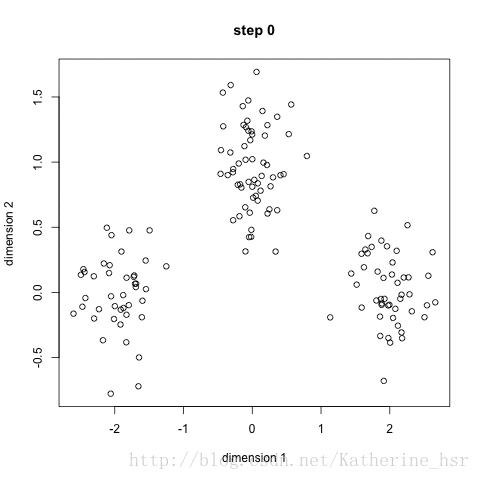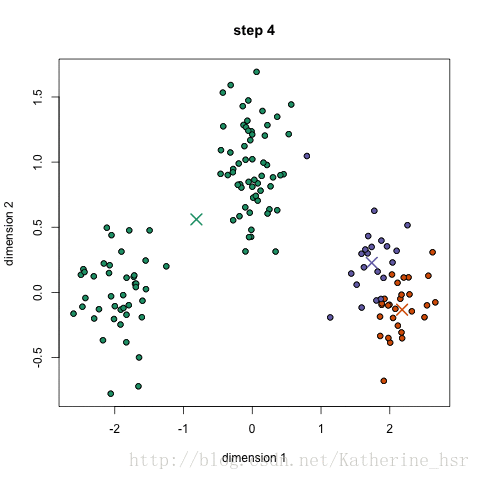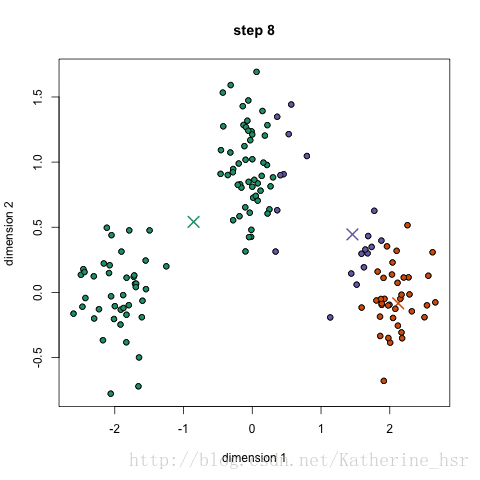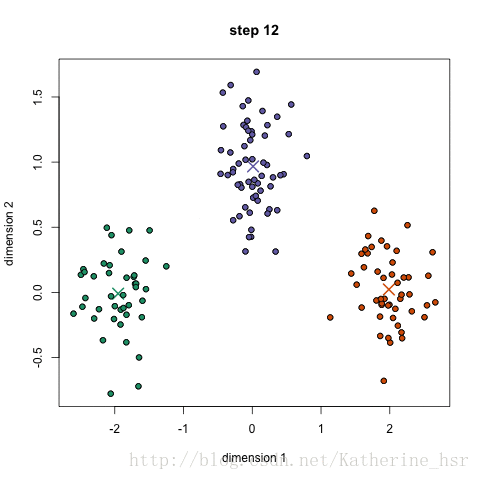
K-means聚类优缺点

- 动态聚类:K-Medians(K中心)聚类

衡量指标为总代价S,总代价S的不同,得出的结果也不一样,比如总代价S可以取
![]()
优缺点

K-Medians是K-Means的一种变体,是用数据集的中位数而不是均值来计算数据的中心点。
K-Medians的优势是使用中位数来计算中心点不受异常值的影响;缺点是计算中位数时需要对数据集中的数据进行排序,速度相对于K-Means较慢。
基于密度的聚类
我们知道像K-Means这种基于距离的不能处理非球形的簇,比如下图

- DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
DBSCAN是基于密度的方法之一,该算法将具有足够高密度的区域划分为簇,并可以发现任何形状的聚类
我们先了解DBSCAN的一些概念,其中半径r和M是我们自己指定(先验给出)的

到最后密度相连的都会划分为一个聚类

算法思想

算法描述

模型优缺点:
优点:不需要知道簇的数量
缺点:需要确定距离r和M
DBSCAN对用户定义的参数很敏感,细微的不同都可能导致差别很大的结果,而参数的选择无规律可循,只能靠经验确定。
基于密度算法还有很多,比如OPTICS放法、DENCLUE方法,大家可以自行去了解
基于网格的聚类
- CLIQUE算法


大家可能看到这里就会有点云里雾里了,简单来说就是,你要确定一个步长,把空间划分为格子,当格子里面的数量大于你定的密度阈值就叫稠密单元
怎么判断一个网格是否是稠密单元,其实是有技巧的
首先遍历所有列,算列的网格点数总和,假如这一列点数加起来还没有我们的密度阈值大,就不用考虑这一列了
其次遍历所有行,算行的网格点数总和,假如这一行点数加起来还没有我们的密度阈值大,就不用考虑这一行了
最后取行列交叉地方才考虑,这样大大降低了复杂度
CLIQUE聚类就是把稠密单元连接在一起通过你定义的邻接网格定义,能连接在一起的分为一类

聚完类之后可能还会遇到一个问题,怎么判断我这个点属于那一个类呢?
因为聚类完出来之后,要想知道聚类方法,二维空间来说,每一个方格都要起码两个不等式,比如1<=x<=2 AND 1<=y<=2是A类,空间那么网格,写那么多不等式来表达聚类太复杂,有没有优化一点的表达方式呢?如下图,中间哪一个大矩形,其实也是用两个不等式就可以表达出来了,就不需要矩形里面每一个格子都写两个不等式,这种叫生成簇的最小化描述

最小覆盖
