一、算法介绍
- 堆:堆是一种数据结构,可以把堆看成是一棵完全二叉树,这棵完全二叉树满足:任何一个非叶结点的值都不大于(或不小于)其左右孩子结点的值。若父亲大孩子小,则这样的堆称为大顶堆;若父亲小孩子大,则这样的堆称为小顶堆。
- 堆化:将当前结点(假设为a)的值与其孩子结点进行比较,如果存在大于 a 值的孩子结点,则从中选出最大的一个与a交换,当 a 来到下一层的时候重复上述过程,直到 a 的孩子结点的值都小于 a 的值为止。
二、算法思想
堆排序的执行过程描述(以大顶堆为例)如下:
- 建堆: 从无序序列所确定的完全二叉树的第一个非叶子结点开始,从右往左,由下往上,对每个结点进行堆化。
- 排序: 建堆结束之后,堆顶元素就是最大元素,我们将其和最后一个元素进行交换,那最大元素就放到了下标为 n 的位置,此时,无序序列的关键字减少1个,有序序列的关键字增加1个。然后,我们再对前面 n−1 个元素进行堆化,再将堆顶元素放到下标为 n−1 的位置。重复这个过程,直到堆中剩余一个元素,排序也就完成了。
三、算法过程
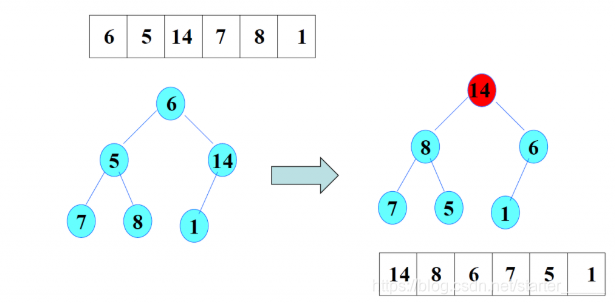
现在要完成6个整数 { 6,5, 14,7, 8, 1 } 的大顶堆排序
(1)建堆
- 调整14,14>1,满足堆定义,不需要调整。
- 调整5,5<7,5<8,不满足堆定义,故交换8和5,交换后5成为了叶子结点,故结束调整。
- 调整6,6<8,6<14,不满足堆定义,故交换6和14。继续调整6,6>1,满足堆定义,不需要调整
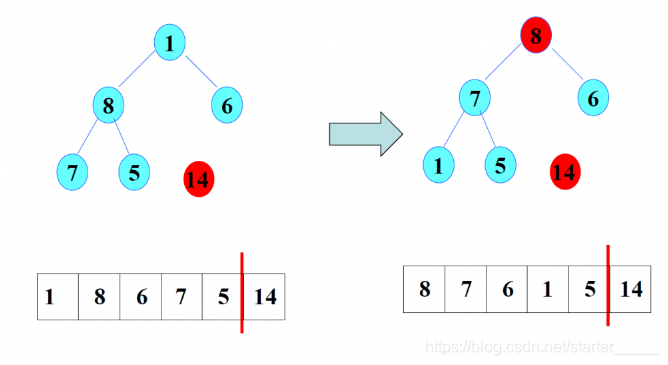
(2)排序1
- 将堆顶14与最后一个元素1进行交换,无序序列的关键字减少1个,有序序列的关键字增加1个。
- 调整1,1<8,1<6,交换1和8。继续调整1,1>5,1>7,交换1和7,交换后1成为叶子结点,故结束调整
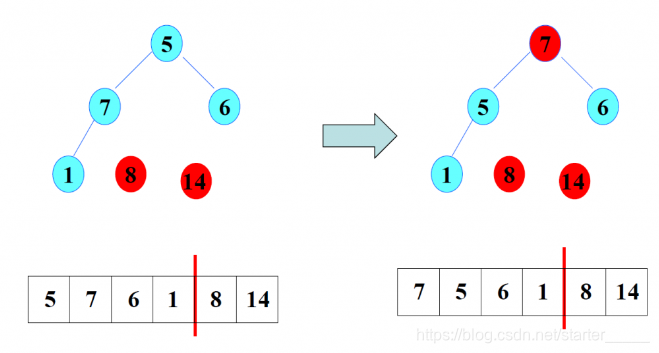
(3)排序2
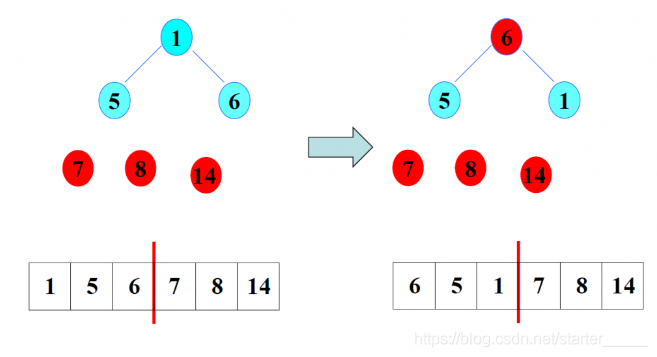
(4)排序3
(5)排序4
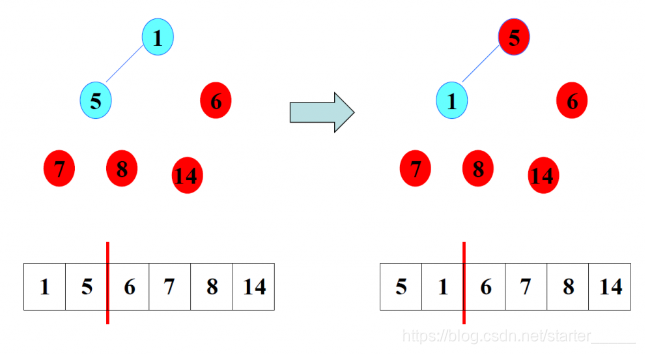
(6)排序5
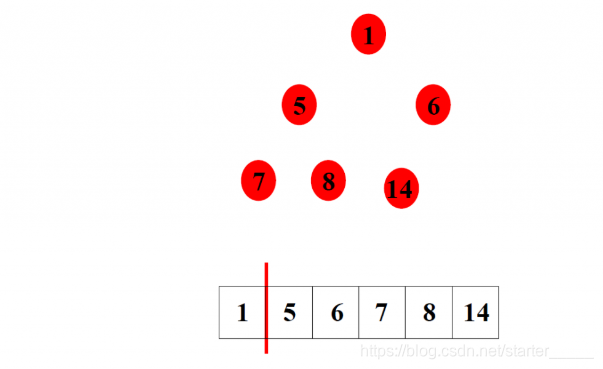
四、堆排序的插入删除操作
(1)插入结点
需要在插入结点后保持堆的性质,因此需要先将要插入的结点x放在最底层的最右边,插入后满足完全二叉树的特点;然后把 x 依次向上调整到合适位置以满足堆的性质。
(2)删除结点
当删除堆的一个结点时,原来的位置就会出现一个空缺,填充这个空缺的方法就是,把最底层最右边的叶子的值赋给该空缺并下调到合适位置,最后把该叶子删除。
五、实现
void translate(int R[],int low,int high) // 在数组R[low]到R[high]的范围内对在位置low的结点进行调整
{
int i=low; // 父结点
int j=i*2; // 左孩子
int temp=R[i]; // 记录父结点
while(j<=high)
{
if(j<high && R[j]<R[j+1]) // 若右孩子比较大,则把j指向右孩子
j++;
if(temp<R[j])
{
R[i]=R[j]; // 将R[j]调整到父结点的位置
i=j; // 修改i和j的值,以便继续向下调整
j=2*i;
}
else
break; // 父结点较大,调整结束
}
R[i]=temp; // 将被调整结点的值放入最终位置
}
void heapSort(int R[],int n)
{
int i;
int temp;
for(i=n/2;i>=1;i--) // 建立初始堆
{
translate(R,i,n);
}
for(i=n;i>=2;i--)
{
temp=R[i]; // 无序序列的堆顶和最后一个元素交换
R[i]=R[1];
R[1]=R[i];
translate(R,1,i-1);
}
}
六、算法性能分析
(1)时间复杂度分析
对于函数 translate(),显然 j 走了一条从当前结点到叶子结点的路径,完全二叉树的高度为 floor(log(n+1)),即对每一个结点调整的时间复杂度为 O(log n)
对于函数 heapSort(),基本操作总次数应该是两个并列的 for 循环中的基本操作次数之和,第一个循环的基本操作次数为 O(log n)*(n/2),第二个循环的基本操作次数为 O(log n)*(n-1),因此整个算法的基本操作次数为 O(log n)*(n/2) + O(log n)*(n-1),故其平均时间复杂度、最坏时间复杂度、最好时间复杂度均为 O(nlog n)
堆排序和快速排序的最好时间复杂度都是 O(nlog n),那么两者之间有什么不同呢?
-
10w 数据量两种排序速度基本相当,但是堆排序交换次数明显多于快速排序;10w+数据,随着数据量的增加快速排序效率要高的多,数据交换次数快速排序相比堆排序少的多。
-
实际应用中,堆排序的时间复杂度要比快速排序稳定,快速排序的最差的时间复杂度是O(n^2),平均时间复杂度是O(nlog n)。堆排序的时间复杂度稳定在O(nlog n)。但是从综合性能来看,快速排序性能更好。
(2)空间复杂度分析
空间复杂度为 O(1)
(3)稳定性
我们知道堆的结构是节点 i 的孩子为 2i 和 2i+1 节点,大顶堆要求父节点大于等于其2个子节点,小顶堆要求父节点小于等于其2个子节点。在一个长为n的序列,堆排序的过程是从第n/2开始和其子节点共3个值选择最大(大顶堆)或者最小(小顶堆),这3个元素之间的选择当然不会破坏稳定性。但建堆的过程是从右往左,从下往上选择非叶子结点,当非叶子结点为n/2-1,n/2-2,…这些个父节点选择元素时,就会破坏稳定性。有可能第 n/2 个父节点交换先把后面一个元素交换过去了,而第 n/2-1 个父节点没有把后面一个相同的元素交换,那么这2个相同的元素之间的稳定性就被破坏了。所以,堆排序不是稳定的排序算法。