 版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
原理
朴素贝叶斯(Naive Bayes)法是基于贝叶斯定理和特征条件独立的假设(这是一个较强的假设,虽然使得方法变得简单,但有时会牺牲一定的分类准确率)的分类方法,属于生成(Generative Approach)方法的一种。
为什么说它属于生成方法呢?
它通过训练数据集学习联合概率分布 , 所以就可以从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度。
具体的,我们的目标是求后验概率 , 即已知输入 取值,求输出 的概率,其中概率最大的就是分类结果。
而由条件概率公式 :
其中先验概率分布 k = 1,2,…n 可以直接从训练数据得到。
对于条件概率
展开如下面,发现它是有指数级的参数,其估计实际是不可能的。:
这里就体现朴素贝叶斯方法简单(朴素)的特点:我们对这里的条件概率分布做了条件独立性的假设。
这里条件假设独立假设等于说 用于分类的特征在类确定的条件下都是条件独立的。
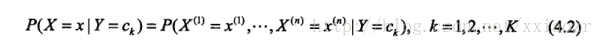
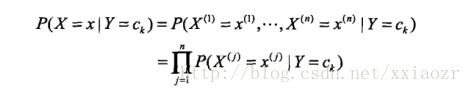
而我们的目标
中分母由P(X)全概率公式展开为:
再带入上面的条件独立性假设公式:
而最后我们选择是概率最大的结果,所以贝叶斯分类器可以表示为:
注意到,分母对于所有的
都是相同的,所以实际上最后分类器只用求:
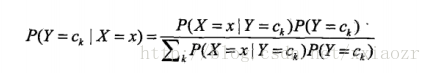
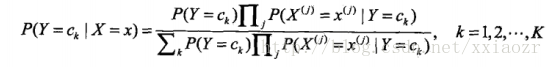
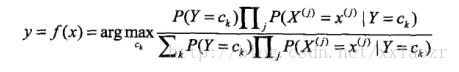
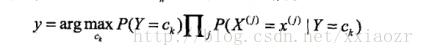
实战
待补充
参考
本文内容是博主总结于《统计学习方法》《机器学习实战》。