一 填空题
1.数据的逻辑结构是从 逻辑 关系上描述数据,它与数据的 具体存储 无关,是独立于计算机的。
2.在一个带头结点的单循环链表中,p指向尾结点的直接前驱,则指向头结点的指针head可用p表示为head= p->next->next .尾结点表示为 p->next
3.栈顶的位置是随着 入栈 和 出栈 操作而变化的。
4.在串S=“structure”中,以t为首字符的子串有 12 个
第一个t为首的子串有t、tr、tru.、truck、truct、tructu、tructur、tructure等8个
第二个t为首的有t、tu、tur、ture4个一共是12个
不需要去掉
5.假设一个9阶的上三角矩阵A按列优先顺序压缩存储在一堆数组B中、其中B[0]存储矩阵中第一个元素a[1][1],则B[31]中存放的元素是 a[4][8]
九阶:9*9上三角:非零元素在右上半部分。按列:1+2+3+4+5+6+7=28个,第一列存储1个第二列存储2个,以此类推。第8列需要存储四个(31+1-28=4)。B[0~31]共32个。故答案是a(4,8)。第四行第8列。
6.已知一棵完全二叉树中共有768结点,则该树中共有 384 个叶子结点和 1 个只具有左孩子的结点和 0 个只具有右孩子的结点。
设二叉树度为0结点个数为n0,度为1的结点个数为n1,度为2结点个数为n2
于是n0 + n1 + n2 = 768
按照二叉树的性质:n0 = n2 + 1,代入得
2n2 + n1 + 1 = 768,显然n1为奇数
考虑到完全二叉树中,最多只有1个度为1的结点 ,因此n1 =1
所以n2 = 383
n0 = 384
7.AOV网是一种 有向无环 的图。
8.在单链表上难以实现的排序方法有 快速排序 和 堆排序 。
9.在有序表(12,24,36,48,60,72,84)中二分查找关键字72时所需进行的关键字比较次数为:
2 。
第一次二分查找取序列中间值48,比较72>48
第二次查找取48右侧的子序列60,72,84的中值72,比较72==72,返回。查找完成
10.对于一棵具有n个结点的二叉树,用二叉链表存储时,其指针总数为 2n 个, n+1个指针是空闲的,有 n-1 指向孩子结点。
n个节点则有2n个链域,除了根节点没有被lchild和rchild指向,其余的节点必然会被指到。所以指针总数为2n个,指向了孩子节点的指针则为n-1个,因为n个节点的二叉树,除根结点以外都有自己的父亲结点或者说其都是一个孩子节点,所以有n-1个指针指向他们。那剩下的就是空闲指针了,共有2n-(n-1)=n+1个。
11.若对一棵完全二叉树从0开始进行结点的编号,并按此编号把它顺序存储到一堆数组A中,即编号为0的结点存储到A[0]中。其余类推。则A[i]元素的左孩子元素为 A[2i+1] ,右孩子元素为 A[2i+2] ,双亲元素为 A[(i-1)/2] 。
画图找规律。
12.在一个具有n个顶点的无向完全图中,包含有 n(n-1)/2 条边,在一个具有n个顶点的有向完全图中包含有 n(n-1) 条边。
定义:具有n个顶点和n(n-1)/2条边的无向图称为完全无向图,具有n个顶点,n(n-1)条弧的有向图称为完全有向图。完全无向图和完全有向图都称为完全图。显然,完全图具有最多的边数,即任意一对顶点间均有边或弧相连。
记不住就画图找规律!
13.在所有内部排序算法中,速度最快的是 快速排序 。
二、单选题
1.算法指的是( D 解决问题的有限运算序列 )。
2.线性表采用链式存储时,结点的存储地址( B 连续与否均可 )
3.将长度为n的单链表接在长度为m的单链表之后的算法的时间复杂度为( C O(m) )
4.由两个栈共享一个向量空间的好处是:( B 节省存储空间,降低上溢发生的机率 )
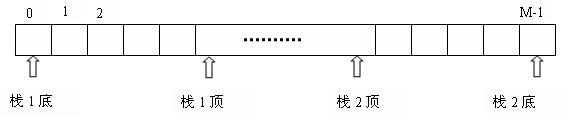
双向栈——两个栈共享同一存储空间
当程序中同时使用两个栈时,可以将两个栈的栈底设在向量空间的两端,让两个栈各自向中间延伸。如下图所示:当一个栈的元素较多,超过向量空间的一半时,只要另一个栈的元素不多,那么前者就可以占用后者的部分存储空间。只有当整个向量空间被两个栈占满(即两个栈顶相遇)时,才会发生上溢,因此两个栈共享一个长度为m的向量空间
5.设有如下遗产继承规则:丈夫和妻子可以互相继承遗产;子女可以继承父亲或母亲的遗产;子女间不能相互继承。表示该遗产继承关系最适合的数据结构应该是( B 图 )
6.在数据结构中,从逻辑上可以把数据结构分成( C 线性结构和非线性结构 )
7.以下数据结构中不属于线性数据结构的是( C 二叉树)
8.算法的时间复杂度是指( C 算法执行过程中所需要的基本运算次数 )
9.哈夫曼树是( C 树的路径长度最短的二叉树?可能有问题,我最后这套试卷不是满分 )
10.由带权9,1,3,5,6的五个叶子结点生成的哈夫曼树的带权路径长度为( C 52 )
算法步骤如下:
①有n棵权值分别为w1,w2,,wn的二叉树,将其组合成一个森林集合F={T1,T2,Tn},其中每棵二叉树Ti中都只有一个权值为wi的根节点,其左右孩子为空。
②在森林F中选出两棵根节点的权值最小的树,将这两棵树合并为一棵新树,为了保证新树仍是二叉树,需要增加一个新结点作为新树的根,并将所选的两棵树的根分别作为新树的左、右孩子,不用区分先后,将左、右孩子的权值之和作为新树根的权值。
③对新的森林集合F重复步骤②,直到森林F中只剩下一棵树为止,最后生成的二叉树为哈夫曼树。
11.深度为k的完全二叉树所含叶子结点的个数最多为( C 2^(K-1) )
找规律!
12.具有10个叶结点的二叉树中有( B 9 )个度为2的结点。
公式:对任何一棵二叉树,如果叶子结点数为n0,度为2的结点数为n2,则一定有n0=n2+1。所以n2=n0-1=9。
三、简答题
1.对于给定的五个实数w={8,5,13,2,6},试构造哈夫曼树,并求出该树的最小带权路径长度。
构造的哈夫曼树是:
(34)
/
(13) (21)
/ \ /
6 (7) 8 13
/
2 5
WPL = 62+23 + 53 + 82+ 13*2 = 75

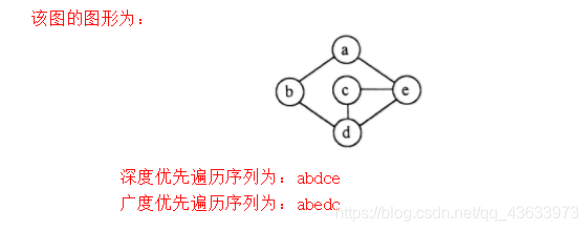
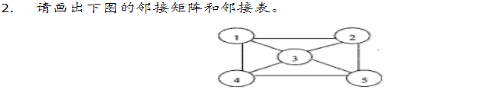
2.已知一个无向图的顶点集为{a,b,c,d,e},其邻接矩阵如下所示

(1)画出该图的图形;
(2)根据邻接矩阵从顶点a出发进行深度优先遍历和广度优先遍历,写出相应的遍历序列。
邻接矩阵:
定义
邻接矩阵(Adjacency Matrix)是表示顶点之间相邻关系的矩阵。设G=(V,E)是一个图,其中V={v1,v2,…,vn} [1] 。G的邻接矩阵是一个具有下列性质的n阶方阵:
①对无向图而言,邻接矩阵一定是对称的,而且主对角线一定为零(在此仅讨论无向简单图),副对角线不一定为0,有向图则不一定如此。
②在无向图中,任一顶点i的度为第i列(或第i行)所有非零元素的个数,在有向图中顶点i的出度为第i行所有非零元素的个数,而入度为第i列所有非零元素的个数。
③用邻接矩阵法表示图共需要n^2个空间,由于无向图的邻接矩阵一定具有对称关系,所以扣除对角线为零外,仅需要存储上三角形或下三角形的数据即可,因此仅需要n(n-1)/2个空间。
在图的邻接矩阵表示法中:
① 用邻接矩阵表示顶点间的相邻关系
② 用一个顺序表来存储顶点信息
图的矩阵
设G=(V,E)是具有n个顶点的图,则G的邻接矩阵是具有如下性质的n阶方阵:
【例】
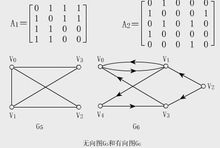
下图中无向图G 5 和有向图G 6 的邻接矩阵分别为A1 和A 2 。
网络矩阵
若G是网络,则邻接矩阵可定义为:
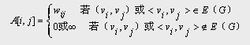
其中:
w ij 表示边上的权值;
∞表示一个计算机允许的、大于所有边上权值的数。
【例】下面带权图的两种邻接矩阵分别为A 3 和A 4 。
二叉树深度优先遍历和广度优先遍历
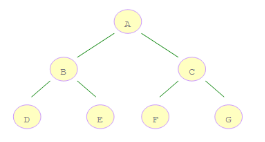
对于一颗二叉树,深度优先搜索(Depth First Search)是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。以上面二叉树为例,深度优先搜索的顺序
为:ABDECFG。怎么实现这个顺序呢 ?深度优先搜索二叉树是先访问根结点,然后遍历左子树接着是遍历右子树,因此我们可以利用堆栈的先进后出的特点,
现将右子树压栈,再将左子树压栈,这样左子树就位于栈顶,可以保证结点的左子树先与右子树被遍历。
广度优先搜索(Breadth First Search),又叫宽度优先搜索或横向优先搜索,是从根结点开始沿着树的宽度搜索遍历,上面二叉树的遍历顺序为:ABCDEFG.
可以利用队列实现广度优先搜索。
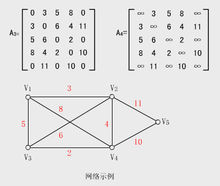
3.已知一个图的顶点集V和边集E分别为:
V={1,2,3,4,5,6,7},E={(1,2)3,(1,3)5,(1,4)8,(2,5)10,(2,3)6,(3,4)15,(3,5)12,(3,6)9,(4,6)4,(4,7)20,(5,6)18,(6,7)25};
(1)画出其邻接表;
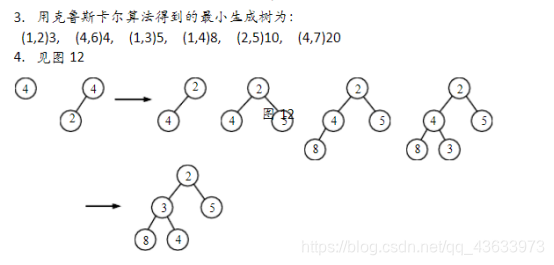
(2)用布鲁斯卡尔算法得到最小生成树,试写出在最小生成树中依次得到的各条边。

自己的感想:如果是v1、v2、v3···用下标,不是直接用值。
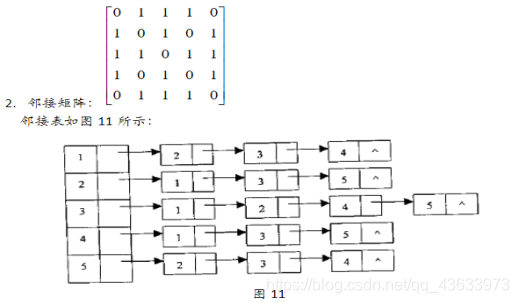
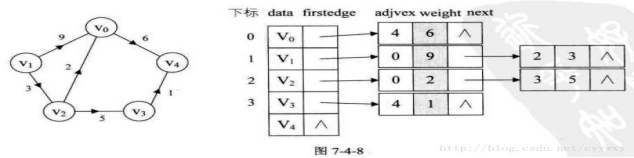
②邻接表
邻接表存储的基本思想:对于图的每个顶点vi,将所有邻接于vi的顶点链成一个单链表,称为顶点vi的边表(对于有向图则称为出边表),所有边表的头指针和存储顶点信息的一维数组构成了顶点表。
邻接表有两种结点结构:顶点表结点和边表结点.。

顶点表 边表
其中:vertex:数据域,存放顶点信息。 firstedge:指针域,指向边表中第一个结点。 adjvex:邻接点域,边的终点在顶点表中的下标。 next:指针域,指向边表中的下一个结点。
adjacency
英 [ə’dʒeɪsnsɪ] 美 [ə’dʒeɪsənsɪ]
n.邻接
vertex
英 [ˈvɜ:teks] 美 [ˈvɜ:rteks]
n.
顶点;最高点;<数>(三角形、圆锥体等与底相对的)顶;(三角形、多边形等的)角的顶点
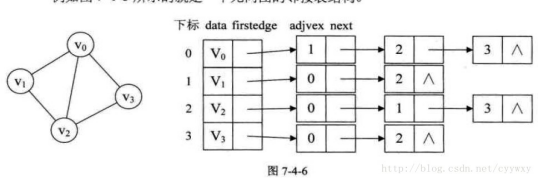
若是有向图,邻接表的结构是类似的,如图7-4-7,以顶点作为弧尾来存储边表容易得到每个顶点的出度,而以顶点为弧头的表容易得到顶点的入度,即逆邻接表。
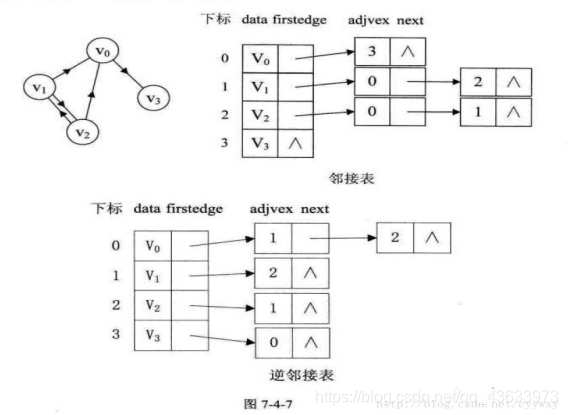
对于带权值的网图,可以在边表结点定义中再增加一个weight的数据域,存储权值信息即可,如图7-4-8所示。
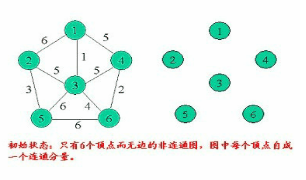
克鲁斯卡尔算法
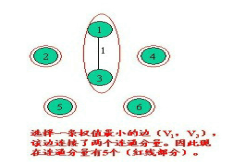
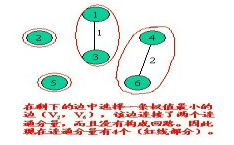
克鲁斯卡尔算法的基本思想是以边为主导地位,始终选择当前可用(所选的边不能构成回路)的最小权植边。所以Kruskal算法的第一步是给所有的边按照从小到大的顺序排序。这一步可以直接使用库函数qsort或者sort。接下来从小到大依次考察每一条边(u,v)。
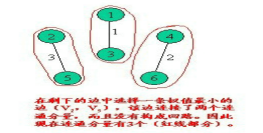
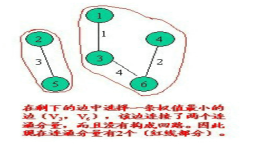
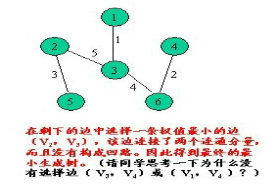
具体实现过程如下:
<1> 设一个有n个顶点的连通网络为G(V,E),最初先构造一个只有n个顶点,没有边的非连通图T={V,空},图中每个顶点自成一格连通分量。
<2> 在E中选择一条具有最小权植的边时,若该边的两个顶点落在不同的连通分量上,则将此边加入到T中;否则,即这条边的两个顶点落到同一连通分量上,则将此边舍去(此后永不选用这条边),重新选择一条权植最小的边。
<3> 如此重复下去,直到所有顶点在同一连通分量上为止。
四、算法填空题
1.void ABC(BTNode*BT)
{
if(BT){
ABC(BT->left);
ABC(BT->right);
cout<data<<’’;
}
}
该算法的功能是:
后序遍历(LRD)是二叉树遍历的一种,也叫做后根遍历、后序周游,可记做左右根。后序遍历有递归算法和非递归算法两种。在二叉树中,先左后右再根,即首先遍历左子树,然后遍历右子树,最后访问根结点。
后序遍历首先遍历左子树,然后遍历右子树,最后访问根结点,在遍历左、右子树时,仍然先遍历左子树,然后遍历右子树,最后遍历根结点。即: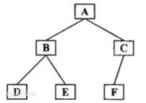
若二叉树为空则结束返回,
否则:
(1)后序遍历左子树(2)后序遍历右子树(3)访问根结点
如右图所示二叉树
后序遍历结果:DEBFCA
已知前序遍历和中序遍历,就能确定后序遍历。 [1]
1、先序遍历(根左右)
先序遍历先从二叉树的根开始,然后到左子树,再到右子树,,如图
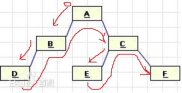
先序遍历序列是ABDCEF,重点是记住第一个字母“A”是根,出发点是根“A”
2、中序遍历(左根右)
中序遍历先从左子树开始,然后到根,再到右子树,如图3
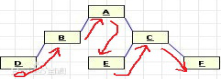
即中序遍历序列是DBAECF,重点是记住中序遍历的根位置,是在序列的第一个字母和最 后一个字母之间,出发点是左子树的最下边的左边的开始,(为什么到A之后直接跳过C呢?因为C也是E和F的根,所以按照中序遍历规律,先到E再到C再到F)
3、后序遍历(左右根)
后序遍历先从左子树开始,然后到右子树,再到根,如图
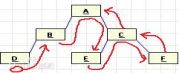
即后序遍历序列式DBECFCA,重点是知道了根是最后面一个字母“A”, 出发点是左子树的最下边左边。
四、道了先序遍历和中序遍历,或者是后序遍历和中序遍历,判断出后序遍历,或者是先序遍历的方法
比如知道先序遍历是ABDCEF,中序遍历是DBAECF,那么可以从先序遍历知道这个二叉树的根是A,(如果是选择题,可以快速判断出后序遍历的序列最后面一个字母肯定是A,然后选择最后面有A的选项)
从中序遍历看出A把DB和ECF隔开,即DB \A \ECF,因此可以知道DB属于左子树,ECF属于右子树
如果是填空题就要写出该二叉树的图,先写出左子树,从中序遍历知道DB是右子树,把DB看成一个整体,则从先序遍历判断可以确定B是D的根,这样就确定出左子树的图是
把ECF右子树看成一个整体,则从先序遍历可以知道C是E和F的根,确定出右子树是
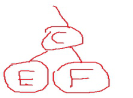
然后把两个子树连在根“A”的下面,再根据后序遍历规律读出序列就可以了

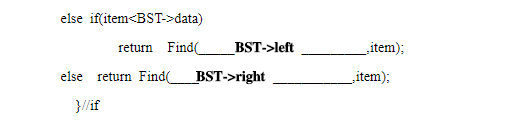
2、二叉树搜索树的查找——递归算法
bool Find(BTreeNode*BST,ElemType& item)
{ if (BSTNULL)
return false;//查找失败
else {
if (itemBST->data){
item=BST->data;//查找成功
return ;}
else if (itemdata)
return Find( ,item);
else return Find( ,item);
}

五、编程题
1、编写一个函数实现单链表的倒置。
struct Node
{
int data;
struct Node*next;
};
非递归(迭代)方式
node* reverseList(node* H)
{
if (H == NULL || H->next == NULL) //链表为空或者仅1个数直接返回
return H;
node* p = H, *newH = NULL;
while (p != NULL) //一直迭代到链尾
{
node* tmp = p->next; //暂存p下一个地址,防止变化指针指向后找不到后续的数
p->next = newH; //p->next指向前一个空间
newH = p; //新链表的头移动到p,扩长一步链表
p = tmp; //p指向原始链表p指向的下一个空间
}
return newH;
}
老师的代码:
//倒置
typedef struct Node
{
int data;//数据域
struct Node *next;//指针域
} TNode;
TNode*reverse(TNode*head)
{
TNode *p,*q;
p=q=head;
head=NULL;
while(p!=NULL)
{
q=p->next;
p->next=head;
head=p;
p=q;
}
return head;
}
2、统计出单链表HL中结点的值等于给定X的结点数。(有多少个结点的值是x)



最后自己的感想:本次考试满分100分,我好像只考了93分。这是期末的原题卷子,是我在考前整理的,考前一题一题的过,我比较笨,而且很疑惑这样做到底是不是无用功,即浪费时间还效率低。我一直觉得自己很笨记忆力很差,但是不这样做笔记又好像我还是什么都不会。现在过了几个月了,发现这些知识我又忘记了。想了想还是重新整理下吧,万一找不到工作就只能考研了,这些知识也许又要学一遍。
我现在处于一个很迷茫的状态,很多知识很多知识需要学习,好多好多,我有时候压力很大,好不容易学的差不多了,结果过几天放着没看就又忘记了,好想哭。代码敲了就忘,也是没谁了,加油吧!!!要努力呀!希望2019可以减肥成功~,另外可以把web安全学习好,争取学会挖洞,然后这学期争取考个好成绩!!加油!