如何度量一个算法的效率呢?
一种方法是事后统计的方法,先将算法实现,然后输入适当的数据运行,测算其时间和空间开销。
事后统计的方法至少有以下缺点:
① 编写程序实现算法将花费较多的时间和精力;
② 所得实验结果依赖于计算机的软硬件等环境因素,有时容易掩盖算法本身的优劣。
通常我们采用事前分析估算的方法——渐进复杂度(asymptoticcom-plexity),它是对算法所消耗资源的一种估算方法。
一、算法的时间复杂度
撇开与计算机软硬件有关的因素,影响算法时间代价的最主要因素是问题规模。
问题规模(problom scope)是指输入量的多少,一般来说,它可以从问题描述中得到。
一个显而易见的事实是:
几乎所有的算法,对于规模更大的输入需要运行更长的时间。
要精确地表示算法的运行时间函数常常是很困难的,即使能够给出,也可能是一个相当复杂的函数,函数的求解本身也是相当复杂的。
基本语句(basicstatement)是执行次数与整个算法的执行次数成正比的语句,
基本语句对算法运行时间的贡献最大,是算法中最重要的操作。
这种衡量效率的方法得出的不是时间量,而是一种增长趋势的度量。
换言之,只考查当问题规模充分大时,算法中基本语句的执行次数在渐近意义下的阶,称作算法的渐进时间复杂度,简称时间复杂度(timecomplexity),通常用大O(读作“大欧”)记号表示。
定义1-1 若存在两个正的常数 c和 n0,对于任意 n ≥ n0,都有 T(n)≤ cf(n),
则称T(n)= O(f(n))(或称算法在O(f(n))中)。
该定义说明了函数T(n)和f(n)具有相同的增长趋势,并且T(n)的增长至多趋同于函数f(n)的增长。大 O记号用来描述增长率的上限,也就是说,当输入规模为n时,算法耗费时间的最大值,

算法的时间复杂度分析实际上是一种估算技术,若两个算法中一个总是比另一个“稍快一点”时,它并不能判断那个“稍快一点”的算法的相对优越性。
但是在实际应用中,它被证明是很有效的,尤其是确定算法是否值得实现的时候。
常见的时间复杂度如下:
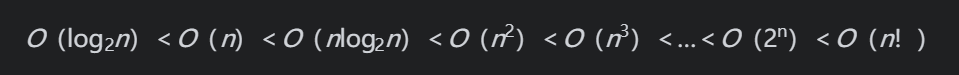
算法的时间复杂度是衡量一个算法优劣的重要标准。
一般来说,具有多项式时间复杂度的算法是可接受的、可使用的算法;
而具有指数时间复杂度的算法,只有当问题规模足够小的时候才是可使用的算法。
如下给出了多项式增长和指数增长的比较。
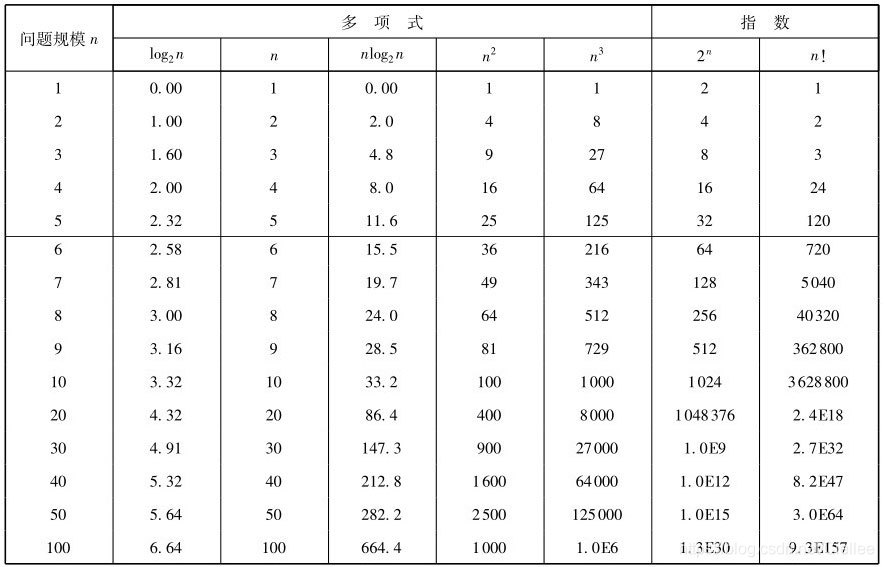
二、算法的空间复杂度
算法在运行过程中所需的存储空间包括:
① 输入/输出数据占用的空间;
② 算法本身占用的空间;
③ 执行算法需要的辅助空间。
其中,输入/输出数据占用的空间取决于问题,与算法无关;
算法本身占用的空间虽然与算法相关,但一般其大小是固定的。
所以,算法的空间复杂度(spacecomplexity)是指在算法执行过程中所需要的辅助空间数量,也就是除算法本身和输入/输出数据所占用的空间外,算法临时开辟的存储空间。
如果算法所需的辅助空间相对于问题规模来说是一个常数,我们称此算法为原地(或就地)工作;
否则,这个辅助空间数量也应该是问题规模的函数,通常记作:
S(n)=O(f(n))
三、算法分析举例
1. 非递归算法的时间性能分析
对非递归算法时间复杂度的分析,关键是建立一个代表算法运行时间的求和表达式,然后用渐进符号表示这个求和表达式。

示例:
(1) 时间复杂度为 O(1),称为常量阶.
++x;
(2) 时间复杂度为 O(n),称为线性阶.
for(int i = 1; i<=n; ++i)
++x
(3) 时间复杂度为 O(n2),称为平方阶.
for(i = 1; i<=n; i++)
for(j = 1; j<=n; j++)
++x;
(4) 时间复杂度为 O(n3),称为立方阶.
for(i = 1; i<=n; i++)
for(j = 1; j<=n; j++)
{
c[i][j] = 0;
for( k = 1; k<=n; ++k )
c[i][j] += a[i][k] * b[k][j];
}
(5) 时间复杂度为 O(log_2^n),称为对数阶
for( i=1; i<=n; i=2*i )
++x;
假设其执行次数为 T(n), 则有 2^T(n)<= n, 即 T(n)≤log_2^n
2. 递归算法的时间性能分析
对递归算法时间复杂度的分析,关键是根据递归过程建立递推关系式,然后求解这个递推关系式。
通常用扩展递归技术将递推关系式中等式右边的项根据递推式进行替换,这称为扩展,扩展后的项被再次扩展,依此下去,就会得到一个求和表达式。
3. 最好、最坏和平均情况
对于某些算法,即使问题规模相同,如果输入数据不同,其时间开销也不同。
此时,就需要分析最好、最坏以及平均情况的时间性能。
例如,顺序查找法
int Find( int a[], int n){
for( i = 0; i< n , i ++)
if(a[i] == k) break;
return i;
}
顺序查找从第一个元素开始,依次比较每一个元素,直到找到k为止,而一旦找到了k,算法也就结束了。
如果数组的第一个元素恰好就是k,算法只要比较1次就行了,这是最好情况;
如果数组的最后一个元素是k,算法就要比较n次,这是最坏情况;
如果在数组中查找不同的元素k,假设数据等概率分布,则平均要比较n/2次,这是平均情况。
一般来说,最好情况不能代表算法性能,因为它发生的概率太小,对于条件的考虑太乐观了。
但是,当最好情况出现的概率较大的时候,应该分析最好情况;
分析最差情况有一个好处——可以知道算法的运行时间最坏能坏到什么程度,这一点在实时系统中尤其重要;
通常需要分析平均情况的时间代价,因为算法要处理不同的输入数据,而且输入数据有不同的分布。
