1,概念简介
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。
卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-like topology)特征,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程(feature engineering)要求,并被大量应用于计算机视觉、自然语言处理等领域。
卷积神经网络可用于分类,检索,识别(分类和回归),分割,特征提取,关键点定位(姿势识别)等等。
2,与神经网络的对比
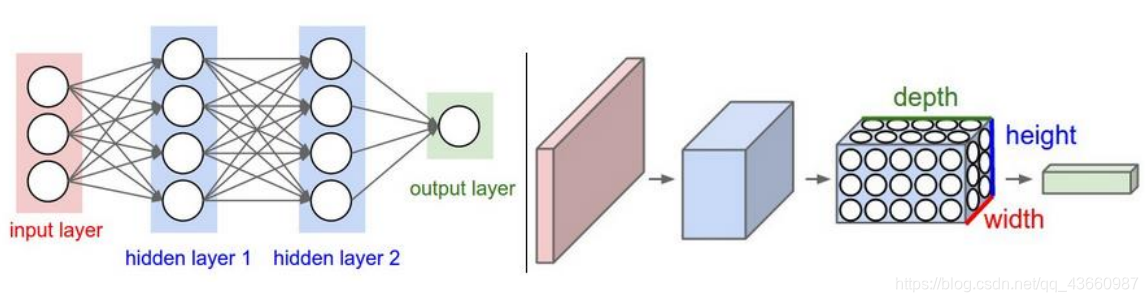
左图为神经网络(全连接结构),右图为卷积神经网络。卷积神经网络组成:输入层;卷积层;激活函数;池化层;全连接层(INPUT - CONV - RELU - POOL - FC)

3,卷积层
假设输入图像的大小为(32,32,3),卷积核大小为(5,5,3)。卷积核的深度和输入图像的深度必须一致(这里为3)。
卷积(特征提取)的结果是对于特定大小的区域(大小和卷积核大小相同)提取一个特征值来代表该区域,遍历图片的所有区域便得到一个由特征值组成的特征图。在卷积过程中可指定卷积核的个数(大小都相同),便可得到多个特征图。
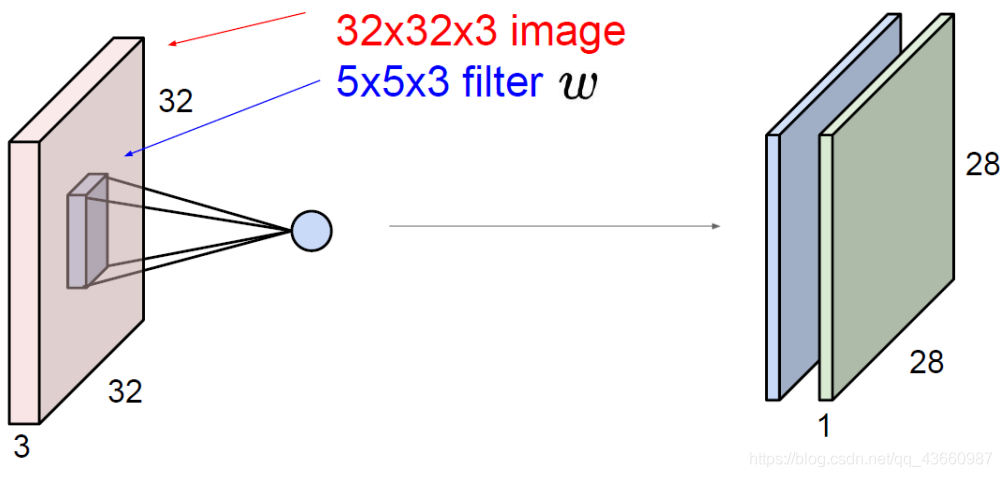 卷积的对象除了输入的图像外,还可以是特征图:
卷积的对象除了输入的图像外,还可以是特征图:
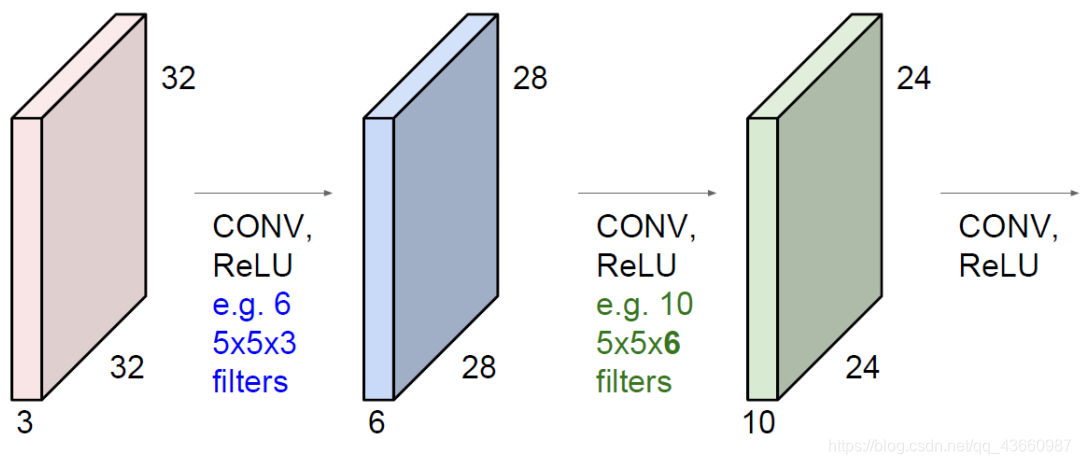 实际卷积的结果(根据提取特征的结果进一步完成分类或回归的任务):
实际卷积的结果(根据提取特征的结果进一步完成分类或回归的任务):

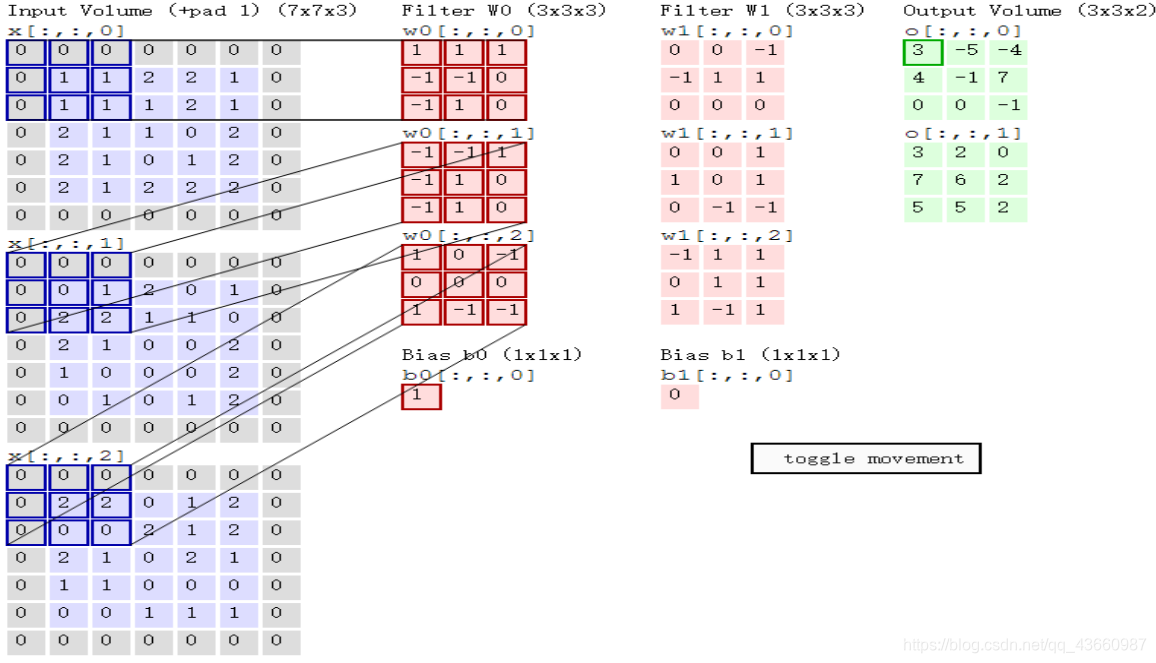
卷积的计算示例:
输入图像大小(7,7,3),指定卷积核大小(3,3,3),通过卷积核窗口的移动(从左到右,由上至下)去遍历图像的所有区域(做内积运算,即对应元素相乘再求和),然后对各个深度的结果求和再加上偏置项b,得到最终结果。各个卷积核中的参数通过卷积神经网络的前向传播和反向传播调节
滑动步长(stride)

滑动步长越大,得到的特征图越小,一般情况希望特征值越多越好,因此滑动步长一般较小,但考虑到计算量,滑动步长不能过小。
在卷积过程中不同的像数点对结果贡献的信息量有可能不同。为了更好地利用边缘像素点的信息,在边缘外围增加若干个填充层(pading),下图为0填充:

计算输出大小:
输入大小为:W1 x H1 x D1;需要指定的超参数:filter个数(K),filter大小(F),步长(S),边界填充(P)
输出大小的公式:
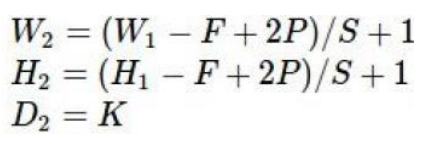

卷积参数(权重)共享原则
每个特征图上所有的特征值都进行权重w共享,并拥有自己的偏置项b,故对于上图的卷积操作共涉及的参数个数计算如下:

4,池化层
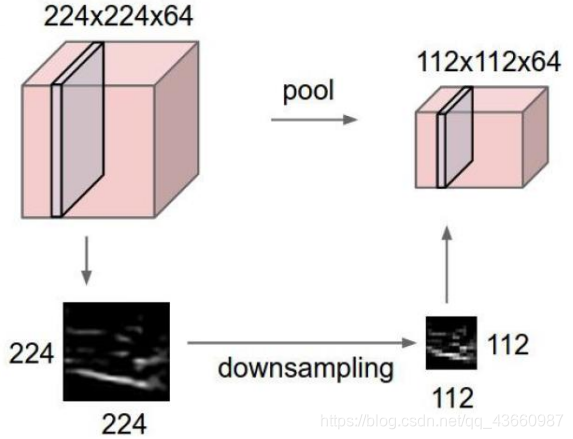
池化层(Pooing layer)一般是对特征图进行特征压缩(利用区域内均值或最大值代表该区域,无权重参数)操作(下采样)。
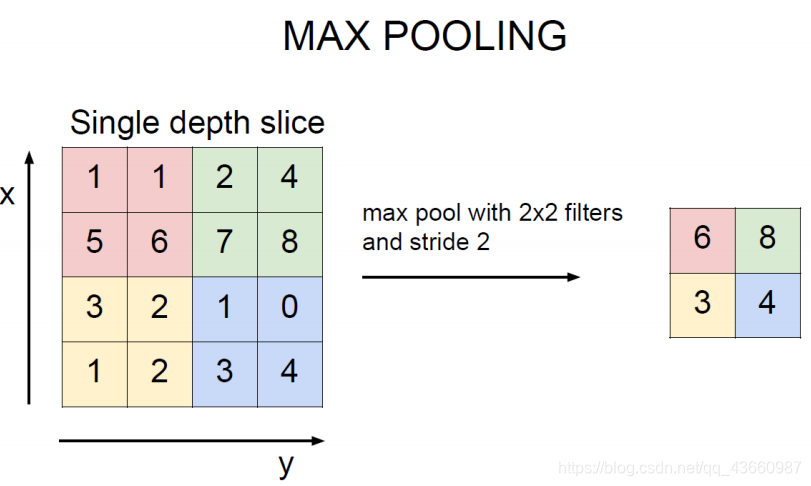
Pooing操作结果示例:
5,前向传播和反向传播原理
5.1 卷积层的前向传播:
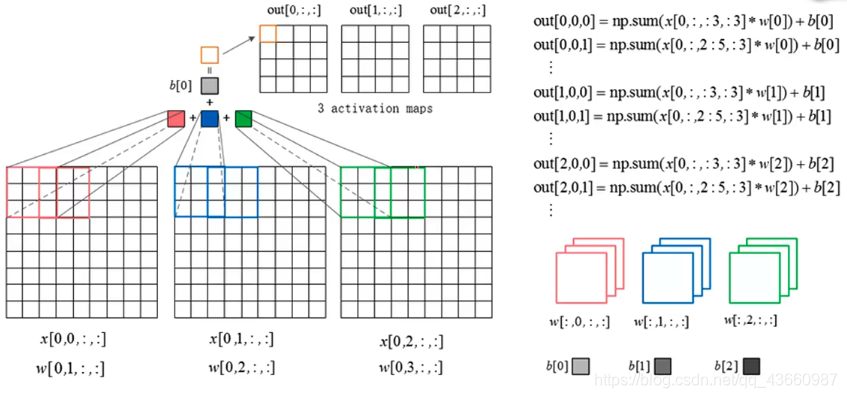
这里输入图像的数据x有4个维度分别代表编号(一般在实际操作中都是通过batch对输入数据进行批量操作的,这里是去一个batch中的第一个图片举例说明),图片通道数(RGB),图片高h,图片宽w。上图选择3个卷积核,其中4个维度分别代表卷积核的编号,与图片通道数相对应的编号,卷积核的高和宽。
5.2 卷积层的反向传播:
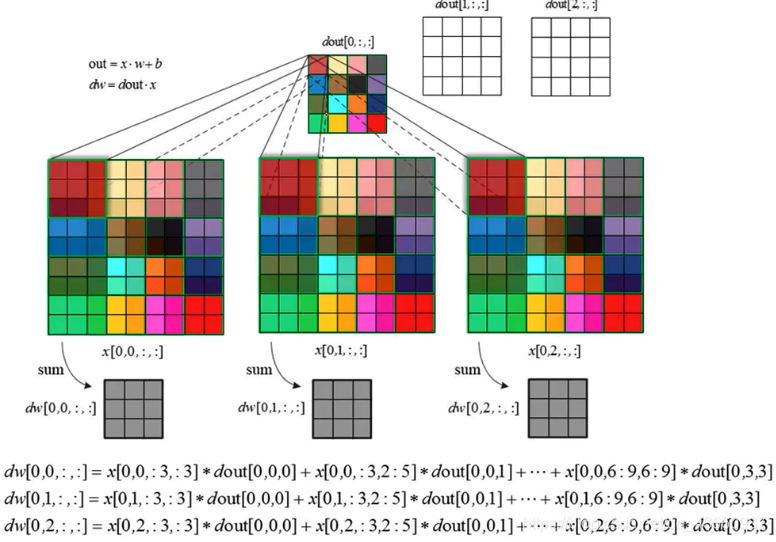
卷积层的反向传播的目的是为了更新权重参数w,上图展示了第一个卷积核的反向传播过程,为了更新参数w。因此要先算出dJ/dw。假设上一层会传过来一个梯度dJ/dout,根据链式求导法则,因此dJ/dw = dJ/dout * dout/dw =dJ/dout * x 。在计算机中方便为变量命名的缘故,将dJ/dout记为dout,dJ/dw记为dw,即图中的情况。后面也用这个记号来讲。
首先要清楚:dw 和 w 的尺寸是一样的。一个点乘以一个区域还能得到一个区域。那么反向传播过程就相当于:用dout中的一个元素乘以输入层划窗里的矩阵便得到一个dw矩阵;然后滑动滑窗,继续求下一个dw,依次下去,最后将得到的多个dw相加,执行 w = w - dw 就完成了反向传播的计算。
5.3 池化层的前向传播和反向传播
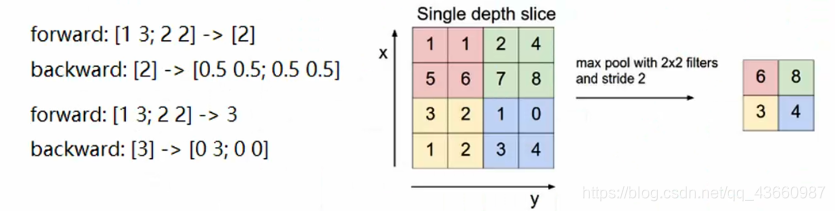
上图分别对应mean和max两种池化方式前向传播和反向传播的结果。对于mean池化方式在反向传播时是将对应值直接均摊到对应区域;对于max池化方式在反向传播时是只在原来最大值处有值(前后相同),对应区域的其他位置均为0。