一. CNN诞生背景
问题一:CNN最早在图像识别领域提出,像素数据很难通过人的理解来提取特征,即特征工程。
问题二:普通神经网络(NN)采用全连接结构(下左图),会使得需要训练的参数过多,超过了现在硬件的计算能力,且容易引起过拟合。
解决方案:
1. (SIFT + SVM): 最初是使用只能用SIFT等算法提取特征,然后结合后**
优点:对图像一定程度的缩放,平移和旋转等具有不变性。
缺点:
- 精度不高,难以突破。
- 使用SVM前需要进行繁琐的预处理工作。
2. CNN出现:
优点:
- 同样对图像一定程度的缩放,平移和旋转等具有不变性。
- SIFT+SVM相比,提取等特征更加有效,精度高
- 采用局部连接(左图),权值共享和池化层的降采样,避免了全联接网络(右图)的参数过多引起过拟合及梯度弥散问题。

对于上面两个图的一点理解:
- 左图:类似于普通神经网路的全联接,不同的是,我们经典神经图输入层是一维数据,这里是保留空间结构的像素输入。
- 右图:说明了局部连接的合理性。图像在空间上的像素点,相隔太远就不一定有什么关联了,那么可以选择一个感受野(receptive field),使得隐藏层中的节点只接受感受野的连接,然后再把感受野平移,将各个局部信息综合起来,得到全局信息。
二. CNN介绍
与普通神经网络相比,卷积神经网络CNN除了输入层和输出层,其隐藏层包含特有的是卷积层和池化层。
本部分内容包括:
- CNN中的基本组成结构
- 卷积层和池化层的工作原理。
2.1 CNN的基本结构
| CNN结构 | 描述 | 该层的数据形式 |
|---|---|---|
| 输入层 | 用于数据的输入,但在CNN中不是一维向量,而是保留图片的结构形式输入。 | n * m 的矩阵,记为 X,也就是下图中黄色的部分,代表原来的输入图像像素。 |
| 卷积层 | 使用固定尺寸和权值的卷积核(也称滤波器),在感受野内以一定步长移动,对X进行滤波,加偏置,最后激活,最终组合成一个特征图(feature map )的过程。 | 对单个卷积核得到的单个节点: *f(W*X+b) |
| 池化层 | 与卷积核类似,使用固定尺寸的池化视野,以一定步长移动,用max_pooling/mean_pooling对卷积层得到的特征图进行差采样,加偏置,最后激活,最终组合成一个更小的特征图 | 取池化区域内的最大值作为特征 |
| 全连接层 | 通常在CNN的尾部进行重新拟合,减少特征信息的损失 | |
| 输出层 | 用于输出结果 |
上面表格可以用经典的LeNet5(如下图)来理解,注意LeNet5含有多个多个卷积和池化的隐含层。

当然中间还可以使用一些其他的功能层:
- 归一化层(Batch Normalization):在CNN中对特征的归一化
- 切分层:对某些(图片)数据的进行分区域的单独学习
- 融合层:对独立进行特征学习的分支进行融合
可参考这篇文章(深度学习之卷积神经网络CNN及tensorflow代码实现示例)
2.2 卷积层
卷积层是神经网络的隐含层,包括滤波过程,加偏置bias和激活过程。
2.2.1滤波过程
先用下面的动态图理解卷积核的滤波过程,其中:
- 绿色矩形代表图片的像素点(X)
- 黄色矩形代表卷积核的尺寸(感受野)
- 红色数字代表卷积核(滤波器)的权(W)

- 用一个卷积核上的各个权值w(黄色区域里的红色数字)乘以感受野上的各个像素值x。
- 感受野内所有wx再相加求和,得到一个高阶特征映射记录下来。
- 然后卷积核以步长为1继续移动,将移动后的各个高阶特征用保留空间结构的方式分别存下来,形成右边红色矩形的卷积特征(但这还没有加偏置和激活,不是最后的feature map)。
2.2.2 偏置和激励过程
- 偏置过程:就是上面红色的矩形图上的数值都再加一个权可以表示为:
- 激励过程:经过一个ReLU函数等,得到最后的卷积层的feature map(多个特征核输出多个)。
2.2.3 卷积层总结
- 卷积层其实就是神经网络的隐藏层,只是隐藏层中的节点是有空间结构的,是一个feature map。
- 卷积层中同一个feature map每个节点都是由卷积核滤波再加上偏置和激活形成的。
- 卷积层中一个feature map形成的不同节点,是同个卷积核以一定步长移动而形成的过程。
- 卷积层中每个feature map 代表提取的一个特定的高阶特征,如边,角等。不同卷积核形成的feature map 也不相同。
- 对于单个feature map,在整个过程中卷积核上的W权值是保持不变的,这叫权值共享。
2.3 池化层
当输入经过卷积层后,若感受视野比较小,布长stride比较小,得到的feature map (特征图)还是比较大,可以通过池化层来对每一个 feature map 进行降维操作,这叫差采样,输出的 feature map 的个数还是不变的。
池化层也有一个“池化视野(filter)”来对feature map矩阵进行扫描,对“池化视野”中的矩阵值进行计算,一般有两种计算方式:
- Max pooling:取“池化视野”矩阵中的最大值
- Average pooling:取“池化视野”矩阵中的平均值
扫描的过程中同样地会涉及的扫描布长stride,扫描方式同卷积层一样,先从左到右扫描,结束则向下移动布长大小,再从左到右。如下图示例所示:
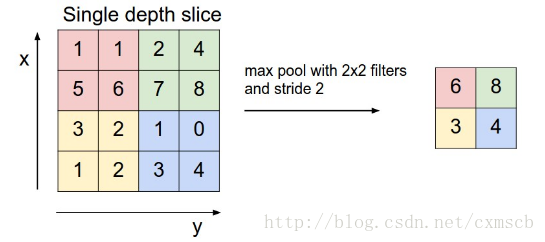
三. 经典的CNN LeNET5
LeNET5有以下几个特点:
- 每个卷积层都有卷积,池化和非线性激活函数
- 降采样(Subsample)的平均池化层
- Sigmoid或tanh激活函数
- C1卷积层:6个卷积核,卷积核尺寸 , 参数个数: ; 其中 +1表示偏置参数。
- Map大小(参照上面的动态图想)
- C3卷积层:16个卷积核,卷积核尺寸 ,这里16个feature map不是全部连接到前面6个Feature Map.C3中的每个Feature Map是连接到S2中的所有6个或者几个Feature Map的,表示本层的Feature Map是上一层提取到的Feature Map的不同组合。这好比人的视觉系统,底层的结构构成上层更抽象的结构,例如边缘构成形状或者目标的部分。 的,有的只连接来几个,增加模型的多样性。
C5卷积层:120个卷积核,卷积核尺寸 ,从上一层得到的图片输入也是 ,构成全连接。
S2、S4都是采用 的平均池化层。
四. 一些问题
1. CNN训练的模型对图像缩放,平移和旋转不变性,具有很强的泛化能力,这怎么理解?
- 平移不变性:
- 对conv层,卷积核对于特定的特征才会有较大激活值,所以不论 上一层的某一特征平移到何处,卷积核都会找到该特征并在此处呈现较大的激活值。
- 对pooling层,以max-pooling为例,若是2x2的池化,那么特征在2x2的区域中平移,得到的结果是一样的。
- 旋转不变性:
- 没有“旋转不变性”,只能通过data argumentation这种方式(人为地对样本做 镜像、旋转、缩放等操作)让CNN自己去学习旋转不变性。
2. SIFT + SVM 和 CNN 的对比,优势在哪里?
- 优点:
- 同样对图像一定程度的缩放,平移和旋转等具有不变性。
- SIFT+SVM相比,提取等特征更加有效,精度高
3. 全联接的神经网络和 CNN 的对比,有什么差别?
采用局部连接,权值共享和池化层的降采样,避免了全联接网络(右图)的参数过多引起计算量过大,过拟合及梯度弥散问题。
4.CNN-LeNet-5 中,输入层,卷积层C1,分别对应普通NN的什么?
传统NN结构图(上图)和LeNet-5中,输入层和卷积层图(下图)分别是这样的:


注意:
- 两个图的小圆圈都是代表相同的含义,只是普通NN中,各个节点是线性排列,而在CNN中,各个节点是有空间结构的。
- 同样的,输入层只是我们的输入数据,没有激活函数,隐藏层和输出层包含激活函数。
5. 神经网络中偏置项b和CNN中的偏置项b的内在寓意是什么,两个一样吗?
- 偏置b的作用:代表里一直偏好,当输入的某个样本偏向某一类时,偏置项b较大,使得该类有比较大的得分输出。
- 两偏置的作用是一样的,但是形式不一样,在神经网络中,代表一个向量多维,CNN中的b是有空间结构的b。
6.为什么CNN中卷积核只提取一个特征,这是为什么?
每一个卷积核只要能提取一个特征,这是权值共享的原因,权值共享后,卷积核只对图像上某个特定区域有较高的得分值,得分较高这部分成为我们选取的特征。查看
7. NN和CNN中隐藏层的参数个数是由什么决定的?
- 在NN是全联接结构,隐藏层的参数个数由输入样本特征维数、偏置、隐藏层节点数决定
- CNN中参数的个数由卷积核的尺寸,卷积核数量,加上偏置决定
8. CNN中如何训练的呢?
卷积神经网络的训练其实和NN的训练过程大体类似,都是采用基于BP算法的训练方式,进行随机梯度下降。
- 首先,通过前向传播计算各层节点的激活值。
- 然后,通过后向传播计算各层之间的误差,
- 如果遇到了pooling,若采用的是avg pooling,那么相应的也就将误差进行均分,反向传播;
- 如果是max pooling,那么可以只将相连的最大节点的误差进行传播,其他节点误差为0;
- 至于卷积操作,和普通的神经网络没啥子大的区别,无非就是权值共享了,因为如果是普通的神经网络,那么w一般针对的是全连接;而CNN是应用了权值共享减少参数个数,并且还进行了Feature Map之间的组合。