基本概念
哈夫曼树又叫最优二叉树,它是由 n 个带权叶子结点构成的所有二叉树中带权路径长度 WPL 最短的二叉树。
-
路径:指从一个结点到另一个结点之间的分支序列。
-
路径长度:指从一个结点到另一个结点所经过的分支数目。
-
树的路径长度:树中所有叶子结点的路径长度之和。
-
权:给树的每个结点赋予一个具有某种实际意义的实数,我们称该实数为这个结点的权。
-
带权路径长度:在树形结构中,我们把从树根到某一结点的路径长度与该结点的权的乘积,叫做该结点的带权路径长度。
-
树的带权路径长度:树中所有叶子结点的带权路径长度之和。
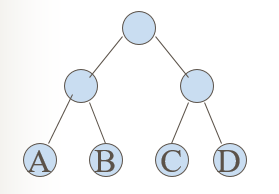
如图所示,叶子结点 A、B、C、D 的权值分别为 7、5、2、4,因为 A 到根结点的分支数目为2,所以 A 的路径长度为2,A 的带权路径长度为 5*2=10、3*2=6、4*2=8,故这棵二叉树的带权路径长度为 WPL=14+10+6+8=38
哈夫曼树的构造方法
给定 n 个权值,用这 n 个权值来构造赫夫曼树的算法描述如下:
(1)将这 n 个权值分别看作只有根结点的 n 棵二叉树,这些二叉树构成的集合记为 F
(2)在森林 F 中选择两棵根结点权值最小的二叉树,作为一棵新二叉树的左、右子树,标记新二叉树的根结点权值为其左右子树的根结点权值之和。
(3)从F中删除被选中的那两棵二叉树,同时把新构成的二叉树加入到森林 F 中。
(4)重复(2)、(3)操作,直到森林中只含有一棵二叉树为止,此时得到的这棵二叉树就是哈夫曼树。
哈夫曼树的构造实例
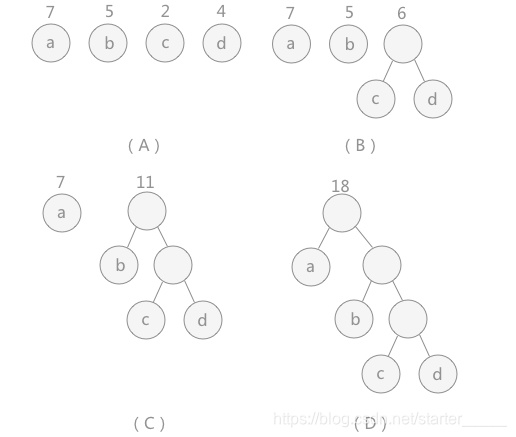
(A)给定了四个结点a,b,c,d,权值分别为7,5,2,4,将其看成4棵只有根的二叉树
(B)找出现有权值中最小的两个根 ,即权值为 2 和 4 的两个根结点。构建一个新的二叉树,树根的权值为 2 + 4 = 6,同时将原有权值中的 2 和 4 删掉,将新的权值 6 加入
(C)找出现有权值中最小的两个根 ,即权值为 6 和 5 的两个根结点。构建一个新的二叉树,树根的权值为 6 + 5 = 11,同时将原有权值中的 6 和 5 删掉,将新的权值 11 加入
(D)找出现有权值中最小的两个根 ,即权值为 7 和 11 的两个根结点。构建一个新的二叉树,树根的权值为 7 + 11 = 18,同时将原有权值中的 7 和 11 删掉,将新的权值 18 加入,集合 F 中只剩下一棵树,得到哈夫曼树。
注:对于同一组结点,构造出的哈夫曼树可能不是唯一的,例如:若a、b、c、d 这4个结点的权值分别为3、2、2、2时,选取权值最小的结点会有两种不同的选择,如 b 和 c 或者 b 和 d
哈夫曼编码
哈夫曼编码就是在哈夫曼树的基础上构建的,这种编码方式最大的优点就是用最少的字符包含最多的信息内容。根据发送信息的内容,通过统计文本中相同字符的个数作为每个字符的权值,建立哈夫曼树。
- 使用前缀编码:任意一个编码不能成为其它任意编码的前缀
- 对于树中的每一个子树,统一规定其左孩子标记为 0 ,右孩子标记为 1 。
- 用到哪个字符时,从哈夫曼树的根结点开始,依次写出经过结点的标记,最终得到的就是该结点的哈夫曼编码。
- 文本中字符出现的次数越多,在哈夫曼树中的体现就是越接近树根。编码的长度越短。
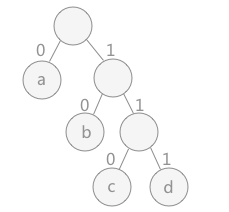
如图所示,字符 a 用到的次数最多,其次是字符 b 。字符 a 在哈夫曼编码是 0 ,字符 b 编码为 10 ,字符 c 的编码为 110 ,字符 d 的编码为 111 。
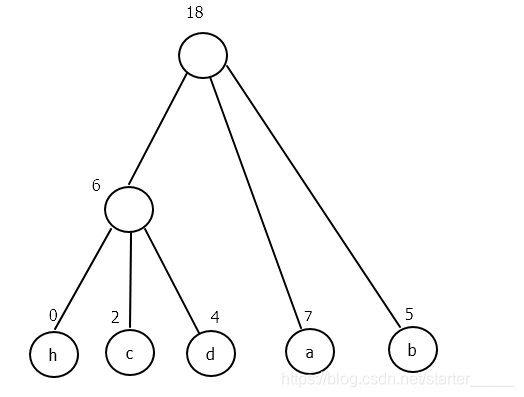
哈夫曼n叉树
下面以哈夫曼三叉树为例
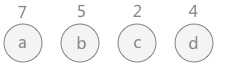
(1)序列无法直接构造哈夫曼三叉树,需要补上一个权值为0的结点h
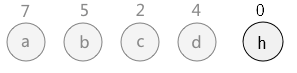
(2)仿照上述哈夫曼二叉树选取结点进行合并,最终会得到