1.Haffman树
我们先以成绩评级举例分析,一步一步的认识Haffman树和Haffman编码。
| 分数 | 0~59 | 60~69 | 70~79 | 80~89 | 90~100 |
|---|---|---|---|---|---|
| 成绩 | 不及格 | 及格 | 中等 | 良好 | 优秀 |
| 所占比例 | 5% | 15% | 40% | 30% | 10% |
如果是要真实实现这个功能,当然有更好的逻辑实现。但是这里为了便于分析,就拿这样的伪代码举例了。通过if 判断语句进行成绩评级。
if (a >= 0 && a < 60) {
b = "不及格";
} else if (a >= 60 && a < 70) {
b = "及格";
} else if (a >= 70 && a < 80) {
b = "中等";
} else if (a >= 80 && a < 90) {
b = "良好";
} else if (a >= 90 && a <= 100) {
b = "优秀";
}
统计成绩的判断语句执行次数:5 * 1 + 15 * 2 + 40 * 3 + 30 * 4 + 10 * 5 = 325
if (a >= 70 && a < 80) {
b = "中等";
} else if (a >= 80 && a < 90) {
b = "良好";
} else if (a >= 60 && a < 70) {
b = "及格";
} else if (a >= 90 && a <= 100) {
b = "优秀";
} else if (a >= 0 && a < 60) {
b = "不及格";
}
判断成绩的语句要执行的次数为:40 * 1 + 30 * 2 + 15 * 3 + 10 * 4 + 5 * 5 = 210
通过两种方案的对比,我们发现改变权值(权重,频率,也可理解出现的次数或比例)大的元素先执行,判断语句的执行次数降低了,是不是隐隐约约有点感觉,其实这就是压缩思路的雏形。为了有更进一步的了解,接着往下看:
我们先把这两科二叉树简化成叶子结点带权(重)的二叉树,如下图所示。其中A表示不及格、B表示及格、C表示中等、D表示良好、E表示优秀。每个叶子的分支线上的数字就是前面提到的成绩所占比例数。
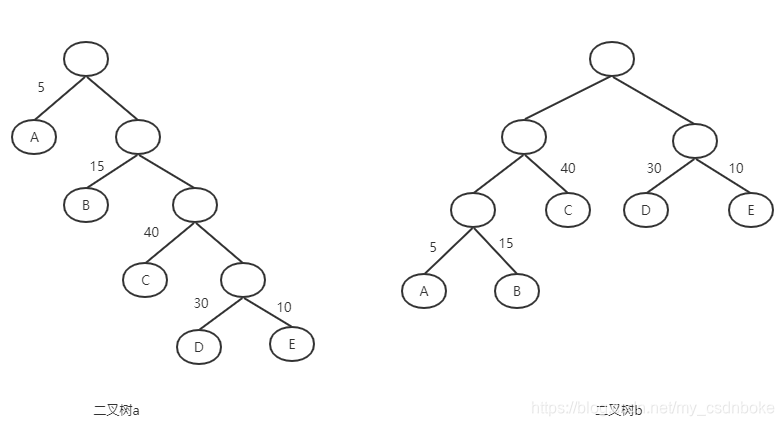
哈夫曼大叔说,从树中一个结点到另一个结点之间的分支构成两个结点之间的路径,路径上的分支数目称作路径长度。每一个结点和它的父节点之间的路径长度为1,在二叉树a中,根结点到D结点有4段,所以根结点到D结点的路径长度为4,二叉树b中根结点到D结点,有2段,所以根结点到结点D的路径长度为2. 树的路径长度就是从树根到每一个结点的路径长度之和。二叉树a的树路径长度就为1 + 1 + 2 + 2 + 3 + 3 + 4 + 4 = 20。二叉树b的树路径长度就为1 + 2 + 3 + 3 + 2 + 1 + 2 + 2 = 16.
如果考虑到带权的结点,结点的带权路径长度为从该结点到树根之间的路径长度与结点上权的成乘积。树的带权路径长度为树中所有叶子结点的带权路径长度之和。二叉树a的带权路径长度为:
5x1+1x1+15x2+2x1+40x3+3x1+30x4+10x4 = 321(其它结点权重值为1,未标明)
我们通常把带权路径长度最小的二叉树称作哈夫曼树。既然知道了哈夫曼树的概念,那么如何过构造一颗哈夫曼树呢?还是上面的成绩例子进行分析,主要有以下几个步骤
- 1.先把有权值的叶子结点按照从小到大的顺序排列成一个有序序列,即:A 5,E 10,B 15,D 30,C 40。
- 2.取头两个最小权值的结点作为一个新结点N1的两个子结点,注意相对较小的是左孩子,这里就是A为N1的左孩子,E为N1的右孩子,如下图(1)所示。新结点的权值为两个叶子权值的和5+10=15。
- 3.将N1替换A与E,插入有序序列中,保持从小到大排列。即:N1 15,B 15,D 30,C 40。
- 4.重复步骤2,将N1与B作为一个新结点N2的两个子结点。如图(2),N2的权值=15 + 15 = 30。

- 5.将N2替换N1与B,插入有序序列中,保持从小到大排列。即N2 30,D 30, C 40。
- 6.重复步骤2。将N2与D作为一个新结点N3的两个子结点。如图(3)所示,N3的权值=30+30=60
- 7.将N3替换N2与D,插入有序序列中,保持从小到大排列。即:C 40, N3 60。
- 8.重复步骤2。将C与N3作为一个新结点T的两个子结点,如图(4)所示。由于T即是根结点,完成哈夫曼树的构造。

2.Haffman编码
当然,哈夫曼研究这种最优树的目的不是为了我们可以转化一下成绩,他的更大目的是为了解决当年远距离通信(主要是电报)的数据传输的最优问题。
比如我们有一段文字内容为"BADCADFEED"要网络传输给别人,显然用二进制的数字(0和1)来表示是很自然的想法,我们现在这段文字只有6个字母ABCDEF,那么我们可以用相应的二进制数据表示,如下表所示:
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 二进制字符 | 1 | 0 | 10 | 11 | 100 | 101 |
那么进行编码后得到的二进制数据为:01111011110110010011,传入这段二进制数据,接收方收到数据后,根据对应的表格进行解码,先查0得到B, 再查1得到A,再查1,又得到A,显然解码出问题了,无法得到解码二进制数据得到原数据。所以我们想到的是并不能简单随意指定数据中各个元素的二进制编码,需要有一定的规则。没错,就是考虑用Haffman数来存数据,进行二进制编码。由于构建Haffman树,需要知道各个元素的权值,也就是频率,现在我们假设6个字母的频率(权值)为A 27,B 8,C 15,D 15,E 30,F 5,合起来正好是100%,图(5)为构造Haffman树的过程的权值显示,图(6)为将权值左分支(孩子)改为0,右分支(孩子)改为1后的Hafuman树。

此时,我们对这6个字母用其从树根(根结点)到叶子(结点)所经过路径的0或1来编码,可以得到下表这样的定义
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 二进制字符 | 01 | 1001 | 101 | 00 | 11 | 1000 |
我们将文字内容"BADCADFEED"再次编码,得到二进制串:
1001010010101001000111100(共25位),接收数据的一方,就可以对照表格,将二进制数据进行还原了。如果按8位占用1个字节,不足8位,高位补0,这份二进制数据占用5byte,但是原数据呢,一个英文字母占用1个字节算,也是占用10byte, 也就是说我们的数据被压缩了,大大节约了存储或传输成本。相信读者现在应该可以明白微信的图片压缩方案即哈夫曼压缩为什么是无损压缩了,存储的不是像素信息,而是二进制数据,解码图片时,对照相应的编码,还原数据,即图片的具体像素信息。
储或传输成本。相信读者现在应该可以明白微信的图片压缩方案即哈夫曼压缩为什么是无损压缩了,存储的不是像素信息,而是二进制数据,解码图片时,对照相应的编码,还原数据,即图片的具体像素信息。
