学习率(Learning_rate)
表示了每次参数更新的幅度大小
若过大 则参数容易在最小值附近不断跳跃
若过小 则参数收敛会变慢
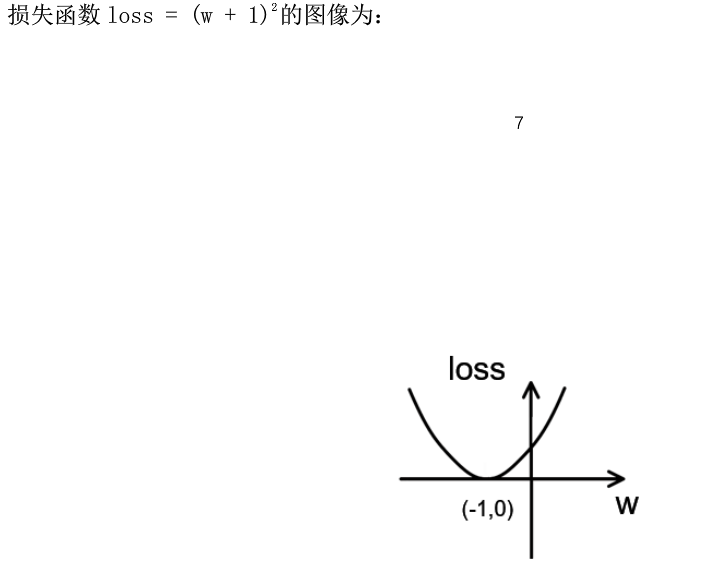
于是 如何设置学习率?
使用
指数衰减学习率

Tensorflow代码:
global_step = tf.Variable(0,trainable=False) learning_rate = tf.train.exponential_decay( LEARNING_RATE_BASE, global_step, LEARNING_RATE_STEP,LEARNING_RATE_DECAY, staircase=True/False )

例子:
import tensorflow as tf LEARNING_RATE_BASE = 0.1 #最初学习率 LEARNING_RATE_DECAY = 0.99 #学习率衰减率 LEARNING_RATE_STEP = 1 #多少轮后更新学习率 #定义全局步数计数器 global_step = tf.Variable(0,trainable=False) learning_rate = tf.train.exponential_decay( LEARNING_RATE_BASE, global_step, LEARNING_RATE_STEP,LEARNING_RATE_DECAY, staircase=True ) #定义待优化参数 w = tf.Variable(tf.constant(5,dtype=tf.float32)) #定义损失函数loss loss = tf.square(w+1) #定义反向传播方法 train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step) #生成会话 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) for i in range(100): sess.run(train_step) learning_rate_val = sess.run(learning_rate) global_step_val = sess.run(global_step) w_val = sess.run(w) loss_val = sess.run(loss) print ("%s步后:global_step: %f , w: %f, Learning_rate = %f , loss = %f " %(i, global_step_val, w_val, learning_rate_val, loss_val))
得到最终结果:
0步后:global_step: 1.000000 , w: 3.800000, Learning_rate = 0.099000 , loss = 23.040001 1步后:global_step: 2.000000 , w: 2.849600, Learning_rate = 0.098010 , loss = 14.819419 2步后:global_step: 3.000000 , w: 2.095001, Learning_rate = 0.097030 , loss = 9.579033 3步后:global_step: 4.000000 , w: 1.494386, Learning_rate = 0.096060 , loss = 6.221961 4步后:global_step: 5.000000 , w: 1.015167, Learning_rate = 0.095099 , loss = 4.060896 5步后:global_step: 6.000000 , w: 0.631886, Learning_rate = 0.094148 , loss = 2.663051 6步后:global_step: 7.000000 , w: 0.324608, Learning_rate = 0.093207 , loss = 1.754587 7步后:global_step: 8.000000 , w: 0.077684, Learning_rate = 0.092274 , loss = 1.161403 8步后:global_step: 9.000000 , w: -0.121202, Learning_rate = 0.091352 , loss = 0.772287 ...... 90步后:global_step: 91.000000 , w: -0.999985, Learning_rate = 0.040069 , loss = 0.000000 91步后:global_step: 92.000000 , w: -0.999987, Learning_rate = 0.039668 , loss = 0.000000 92步后:global_step: 93.000000 , w: -0.999988, Learning_rate = 0.039271 , loss = 0.000000 93步后:global_step: 94.000000 , w: -0.999989, Learning_rate = 0.038878 , loss = 0.000000 94步后:global_step: 95.000000 , w: -0.999990, Learning_rate = 0.038490 , loss = 0.000000 95步后:global_step: 96.000000 , w: -0.999990, Learning_rate = 0.038105 , loss = 0.000000 96步后:global_step: 97.000000 , w: -0.999991, Learning_rate = 0.037724 , loss = 0.000000 97步后:global_step: 98.000000 , w: -0.999992, Learning_rate = 0.037346 , loss = 0.000000 98步后:global_step: 99.000000 , w: -0.999992, Learning_rate = 0.036973 , loss = 0.000000 99步后:global_step: 100.000000 , w: -0.999993, Learning_rate = 0.036603 , loss = 0.000000
学习率不断减小