论文地址: DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation
工程地址:github链接
0. 摘要
该论文提出了一种极其高效的用于实时语义分割的网络框架,这个框架从一个轻量级的主干网络开始,通过一些列的附属阶段来聚合有判别力的特征。基于多尺度的特征传播,DFANet减少模型参数的同时保持了良好的感受野并且增强了模型的学习能力,在速度与分割精度之间找到了一个较好的tradeoff。在通用数据及上的实验表明,DFANet计算量减少了八倍的同时提速两倍并且取得了更好的精度。
1. 介绍
论文在这一节提出语义分割任务的多数解决方法无法找到一个较好的精度和速度的tradeoff,多数方法在处理浅层高分特征图的时候耗时过多,有些方法尝试缩小输入图像尺寸或者减少通道数来提速,有效但是损失了边界和小物体的位置细节信息,而且较浅的网络得到的特征图上有判别力的信息不足,为了克服这些问题,有些方法采用了多分支的结构,但是在浅层高分特征图上还是速度过低,而且各分支相互独立,造成学习能力的不足。
语义分割任务通常使用漏斗形的在图像分类任务上进行过预训练的主干网络如ResNet,Xception,DenseNet等等,对于要求实时的推断,则需要轻量级的主干网络通过较少的计算量得到较好的结果。主流语义分割架构中,金字塔型特征图融合方法如空间金字塔池化能够使用浅层的语义信息增强特征,从而降低计算量,但是多数方法特征图的增强是在一个分支的输出上,没能充分利用之前的特征,基于此,提出怎样设计一个融合多层语义来编码特征的轻量级方法的问题。
论文中提到了两种方式来实现跨层特征聚合,一种是在主干网络的输出上进行语义信息和结构信息的融合,一种是在在网络的不同阶段来增强特征图表征能力,如下图,从左到右分别是:多分支,空间金字塔池化,网络层面的特征复用和网络不同阶段的特征复用。
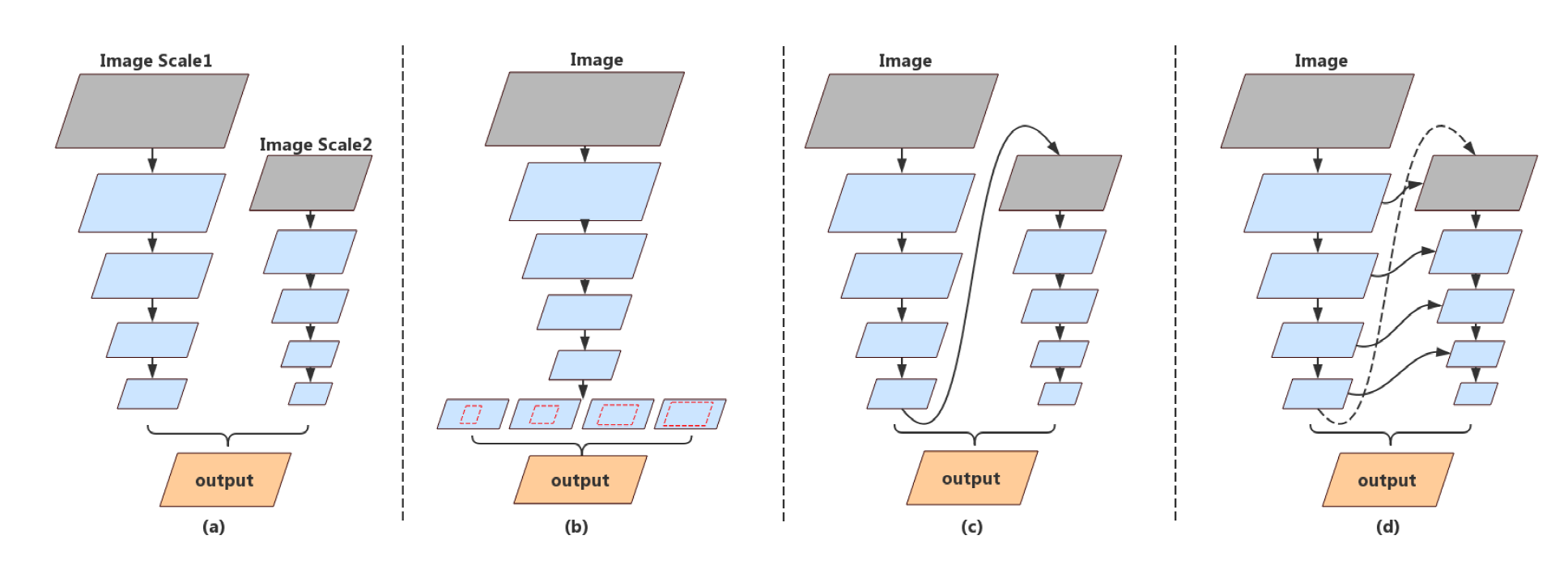
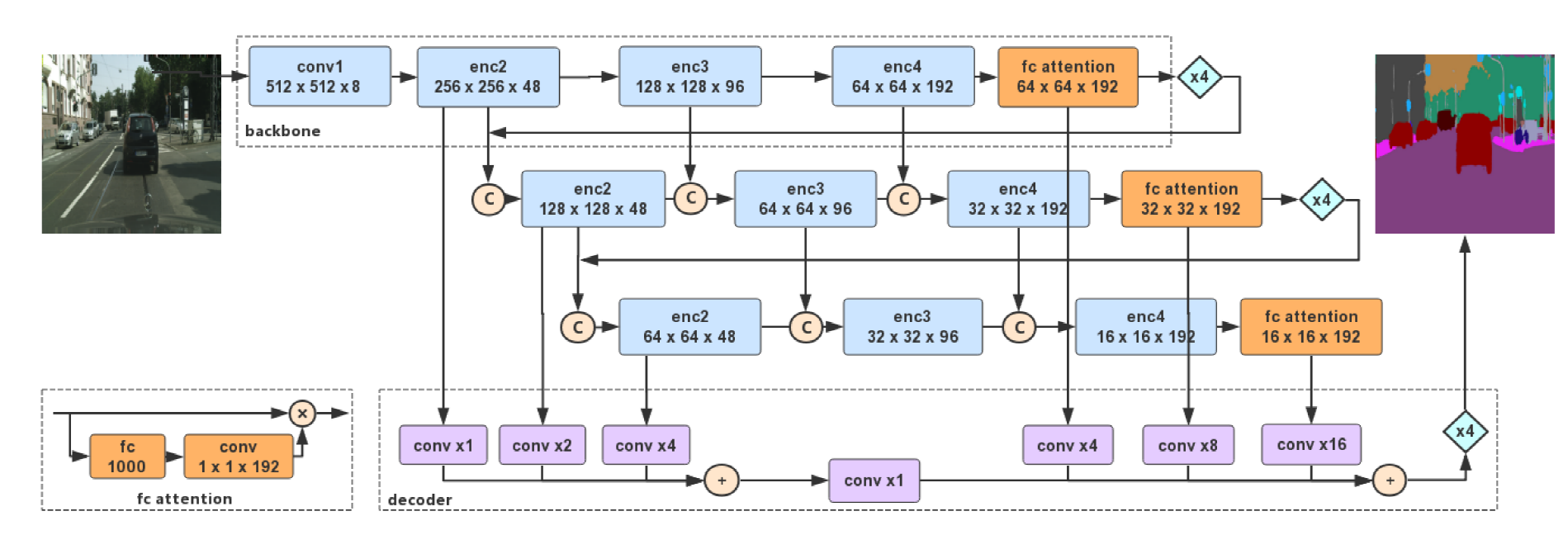
论文提出的深度特征聚合网络DFANet包含三个部分,轻量级的主干网络,子网聚合模块和跨阶段的聚合模块。
鉴于深度可分离卷积的高效操作,论文对Xception网络进行微调作为主干网络,末尾加上一个全连接注意力模块保留最大的感受野。
子网聚合模块则浅层特征图进行上采样以作为输入到下一层网络中调整预测结果。从另一个角度来看,子网聚合也可以被看作一个从粗糙到精细的过程。
子阶段聚合模块融合了不同阶段的特征表示,通过结合相同维度的各层结果进行感受野和高层结构细节信息的传递。
三个部分之后是一个简单的解码模块,生成最终的预测结果。
论文主要的贡献在于:
- 实时语义分割的SOTA效果
- 新型的语义分割网络,多个互联的编码信息流以融合高层语义信息
- 充分利用不同尺度感受野的特征图和高层特征图的调整
- 修改Xception,尾部加入一个FC注意力模块增强特征图感受野。
2. 相关工作
- 实时语义分割:SegNet(池化索引结构),ENet(减少下采样次数),ESPNet(新型空间金字塔池化),ICNet(多尺度图像作为输入),BiSeNet(双路网络架构)
- 深度可分离卷积
- 结构位置信息丰富的浅层语义信息
- 语义编码:FC注意力模块
- 特征聚合
3. DFANet网络架构
如下图所示,网络其实也是编解码结构,编码结构是三个Xception主干网络的聚合,还有一些连接这些信息的子阶段,解码器是一个简单的上采样重建模块。
4. 实验
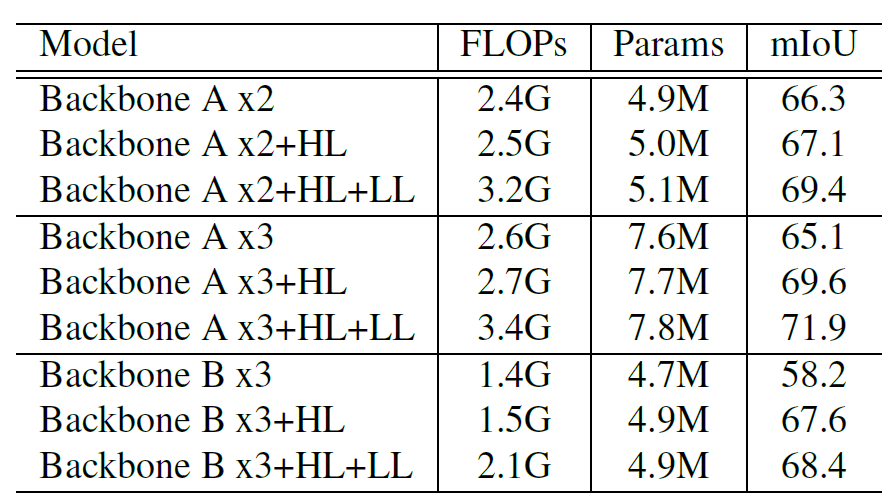
主干网络不同的修改方式
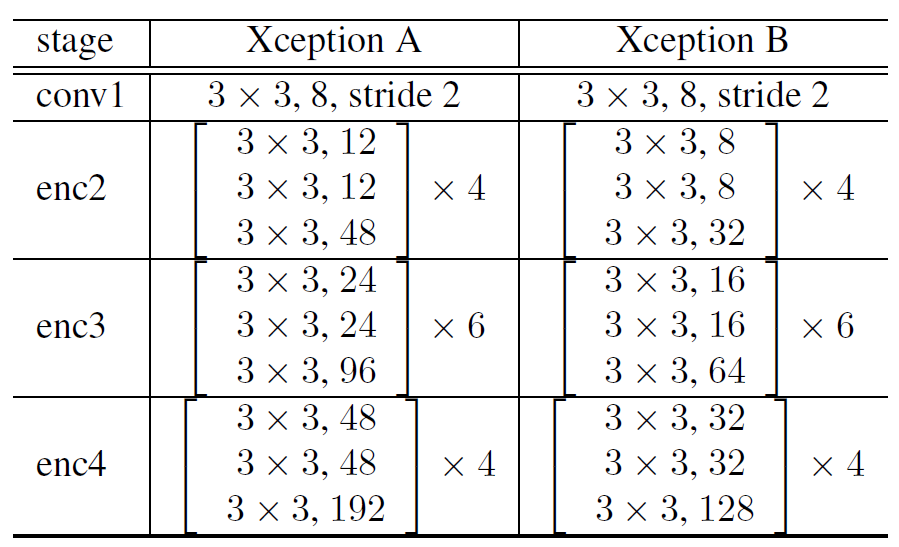
不同的结构

不同程度的特征聚合
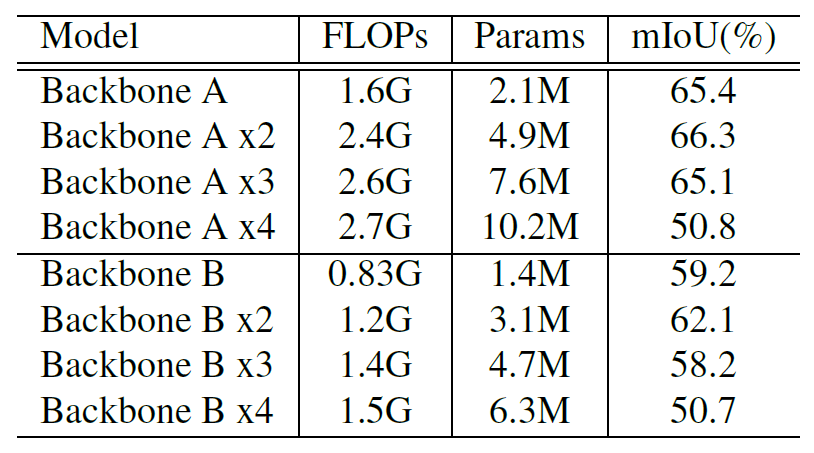
DFANet三个主干网络的输出
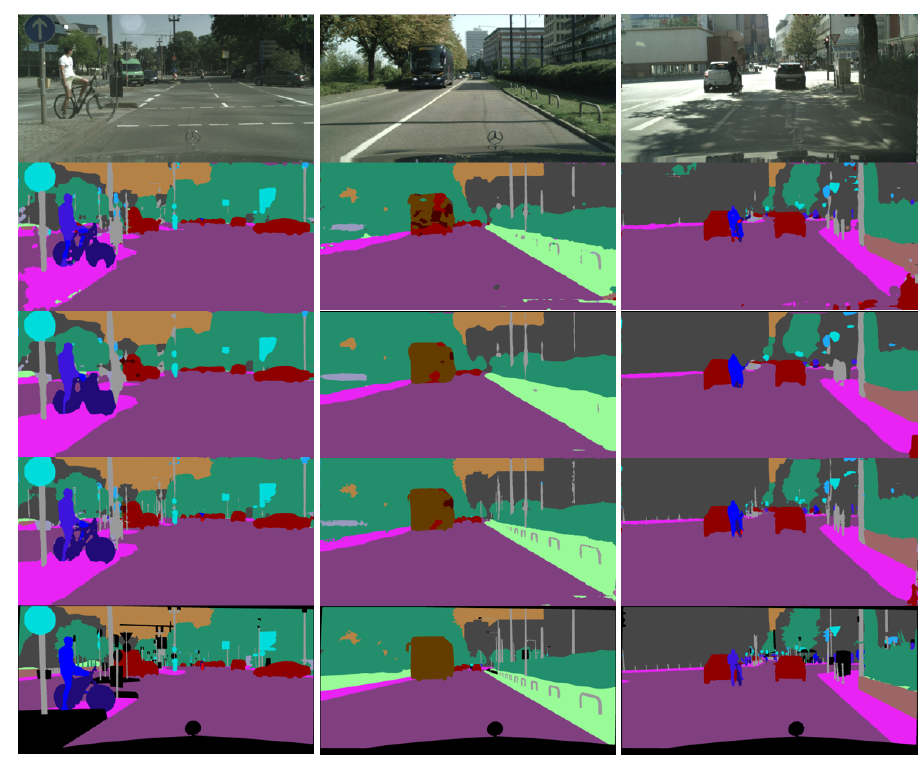
浅层和深层的特征聚合
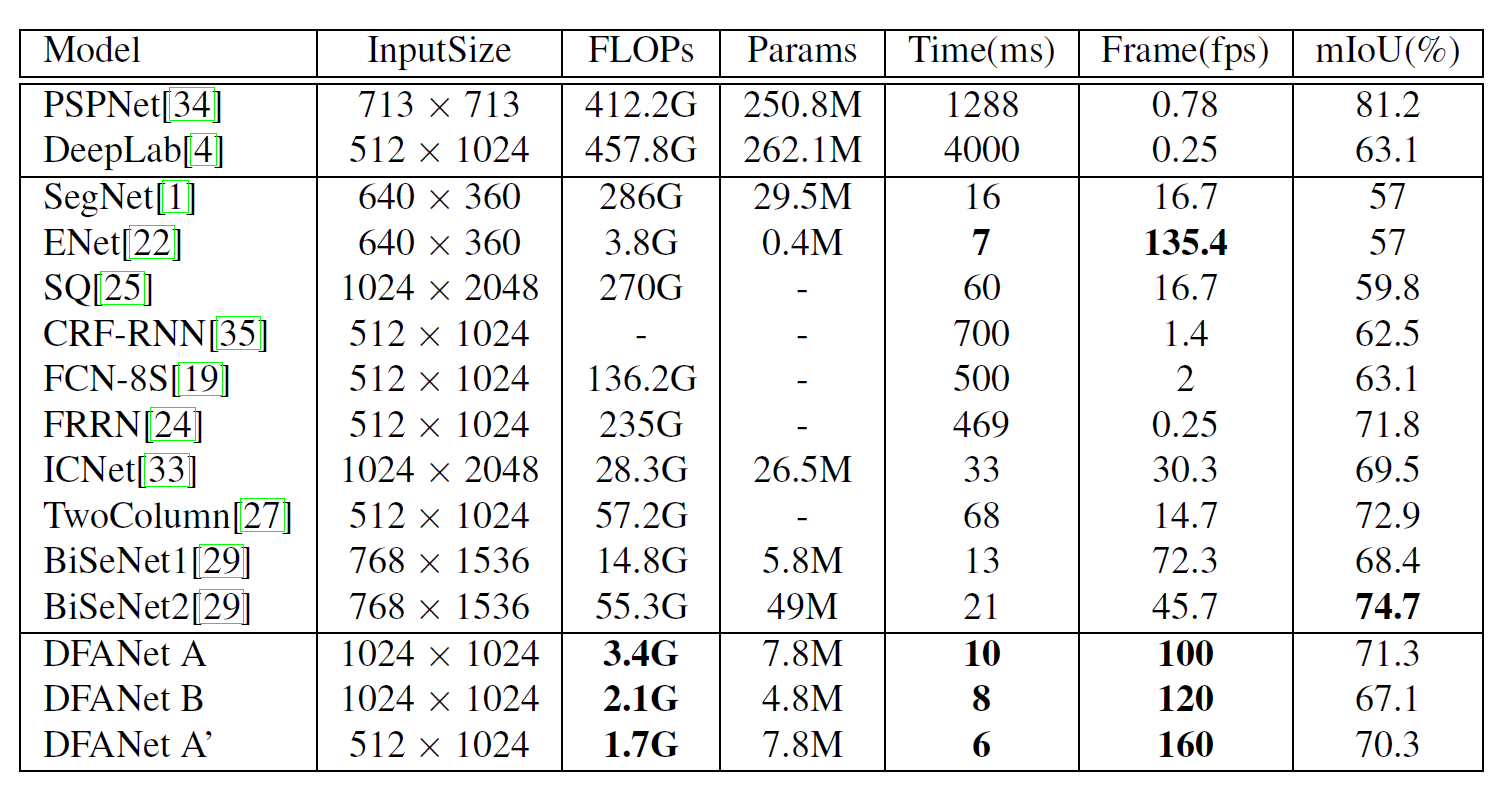
Ciryscapes BenchMarl
CamVid BenchMark

欢迎扫描二维码关注微信公众号 深度学习与数学 [每天获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]
