论文地址 :Rethinking Atrous Convolution for Semantic Image Segmentation
论文代码:Github链接
1. 摘要
文章主要的工作:
- 使用空洞卷积来调整滤波器的感受野并控制特征图分辨率
- 使用不同空洞率的空洞卷积的串联或者并行操作来分割不同尺度的目标,捕获不同尺度的语义信息
- 扩展的ASPP
- 实现和训练的细节
- 没有了DesneCRF的后处理
2. 介绍
使用DCNN做语义分割取得了一定的效果但是存在两个问题。其一,为了使DCNN学习到更加抽象的特征,采用了多次池化操作和带步长的卷积,使得特征图分辨率降低,但同时这不利于密集预测任务,因为后者需要空间位置信息。为了克服这个问题,引入空洞卷积——通过去掉最后几层的上采样和下采样来获得更加密集的特征图,这样还能在不适用额外参数的情况下控制分辨率。
其二,如何捕获不同尺度的目标。目前主要有四种不同的方法,如下图:
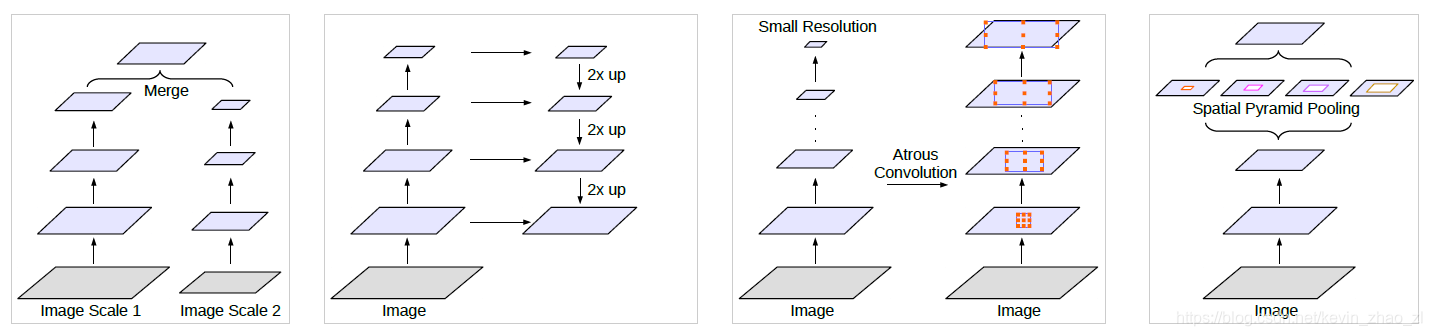
- Image Pyramid:对输入图像进行缩放分别输入网络最后合在一起:小的输入用于捕获long-range context,大的输入用于捕获小物体。但是这样做会使得深层的DCNN计算代价高
- 编解码结构:在编码结构中获取不同尺度的特征并在解码结构中复原
- 额外的后处理以精细画边框,比如DenseCRF
- 空间金字塔池化
3. 方法
在模块串联合金子塔池化的框架中应用带有不同空洞率的空洞卷积和BN层。空洞卷积作为语义模块和SPP的工具,论文提出的模型具有较好的通用性,可以移植到其他网络中。这个模型将ResNet最后一个block多次复制并串联,然后联通ASPP模块,ASPP模块中包含几个并行的空洞卷积,这几个空洞卷积直接应用在特征图而不是信念图上。训练时层上加上BN层。而且,为了捕获全局语义,ASPP还叠加了了图像级别的特征。
3.1 用于密集特征提取的空洞卷积
克服多次池化和带步长的卷积对密集预测任务的影响。
3.2 使用空洞卷积设计更深的模型

如上图,简单地复制ResNet最后一个block几次并且并行起来并不利于网络获取深层语义信息,因为这样使得图像的特征集中在最后几层比较小的特征图中,但是连续的带步长卷积不利于语义分割,所以使用了空洞卷积来设计最终的output_stride(原始图像尺寸之于输出特征图尺寸的倍数),如下图所示:

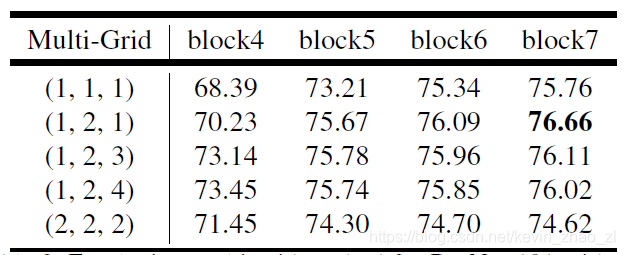
初次之外还引入了Multi-grid Method,上图中Block4至7,采用Multi-grid来描述这三层的空洞率,比如,当output_stride=16时,Multi_Grid=(1,2,4),相应的空洞率为(2,4,8)。
3.3 ASPP
ASPP中虽然包含几个不同的空洞率的卷积操作,但是当空洞率越来越大时,有效的滤波器的权重数越来越小。比如在65 X 65的特征图上应用3 X 3的滤波器,非但不能捕获全局图像语义,其效果还退化到与1 X 1滤波器效果一致,因为仅有中心的滤波器权重是有效的。
因此,ASPP模块中包含几个并行的空洞卷积,这几个空洞卷积直接应用在特征图而不是信念图上。训练时层上加上BN层。而且,为了捕获全局语义,ASPP还叠加了了图像级别的特征。
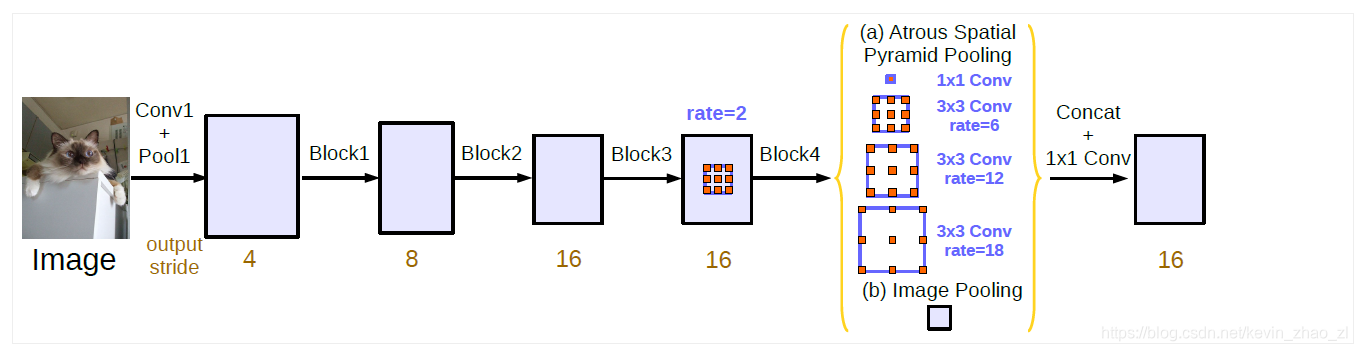
如上图所示,ASPP模块中有一个1x1的卷积层和三个3x3的卷积层,空洞率分别为6,12,18,output_stride为16(每一层都有256个滤波器并且后跟BN层);而且ASPP中还增加了image-level特征,最后在模型输出的特征图上进行1x1的卷积(256个滤波器并且后跟BN层)并进行插值上采样至所需的空间维度尺寸。
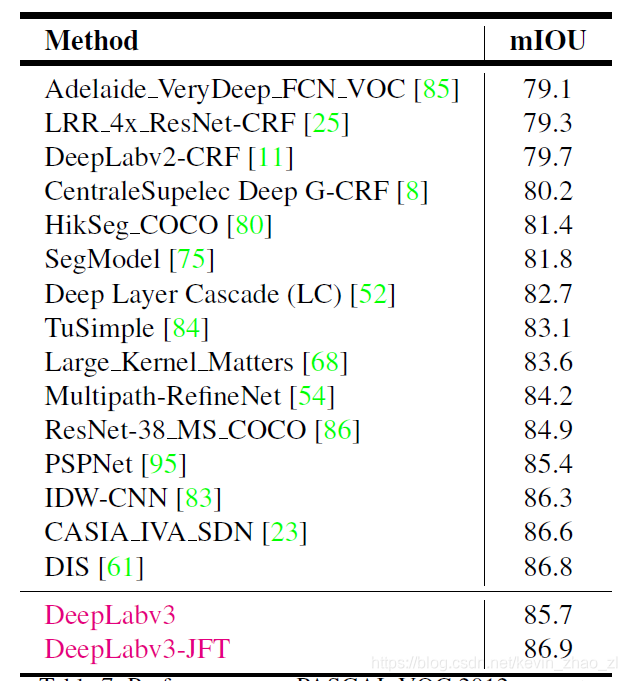
4. 实验
4.1 ResNet50 v.s. ResNet101

4.2 block4中应用不同的Multi-grid
4.3 ASPP
在block4中应用Multi-grid以及ASPP中使用不同的空洞率:

4.4 FINAL