深度学习点云语义分割:CVPR2019论文阅读
Point Cloud Oversegmentation with
Graph-Structured Deep Metric Learning
摘要
本文提出了一个新的超级学习框架,用于将三维点云过度分割为超点。本文将此问题转化为学习三维点的局部几何和辐射测量的深度嵌入,从而使物体边界呈现高对比度。嵌入计算使用轻量级神经网络在点的局部邻域上操作。最后,本文将点云过分集描述为一个与学习嵌入相关的图划分问题。这种新方法允许本文在密集的室内数据集(S3DIS)和稀疏的室外数据集(vKITTI)上设置一个新的尖端点云过分集(显著的边缘)。本文的最佳解决方案需要比以前在S3DIS上发布的方法少五倍多的超级点才能达到类似的性能。此外,本文还展示了本文的框架可以用来改进基于超点的语义分割算法,同时也为这项工作创造了一个新的技术水平。
- Introduction
此外,本文还定义了本文的点云过分割的最终目标,即通过提供语义上纯粹的重叠来辅助语义分割方法。本文证明,本文的方法可以与文献[27]中的超点图方法相结合,显著地改进分割步骤,从而实现语义分割。
本文的贡献如下:
•本文提出了第一个三维点云过度分割的超级框架;
•本文引入了图形结构的对比损失,它可以与本文的交叉划分加权策略相结合,在对象边界生成具有高对比度的点嵌入;
•本文引入局部点嵌入器,这是一种轻量级架构,灵感来自[36],以紧凑的方式嵌入三维点的局部几何和辐射测量;
•本文显著改善了两个已知且非常不同的数据集的点云过度分段的最新技术;
•在结合超点图语义分割方法的基础上,本文的方法也提高了这项工作的技术水平。
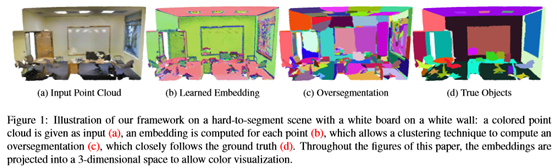
- Related work
超级像素/超级体素:
有大量关于将图像过度分割为超级像素[44]和视频过度分割为超级体素[51]的文献。这些方法可以分为两组:基于图的方法利用像素的连接性[11,16,31]和基于簇的方法利用像素的相对位置[1,46,52,28]。最近,深度学习方法被成功地用于开发超混合过分割方法,无论是基于图的方法[32],还是基于簇的方法[24]。
三维点云的过度分段:
上述方法在图像上表现良好,但依赖于像素的规则结构。三维点云作为分布不规则的无序点集,需要特别关注。[4] 提出了二维局部变分图方法[11]的三种扩展,并研究了构造图、边权和子图合并的不同策略。[43]介绍了一种图结构方法,该方法利用激光雷达传感器的结构去除与边界点相对应的边缘。[34]提出了一种基于k-均值算法和八叉树的聚类方法。但是,此方法对群集的初始化仍然敏感。[12] 利用RGBD图像的视觉显著性初始化聚类。[30]提出了一种不需要初始化的聚类方法,因此对激光雷达点云的不规则密度不太敏感。同样,[17]引入了一个无初始化的分割模型,该模型被描述为一个图结构优化问题。所有这些方法都依赖于手工制作的几何和/或色度特征。
三维点云深度学习:
[36]中的工作开创了将深度学习用于三维点云处理的先河。然而,迄今为止,这种用法仅用于语义分割[29、45、9、41、38、37、53、49]、对象检测[56]或重建[15]。据本文所知,还没有开发出利用基于深度学习的嵌入来生成超点的有监督的三维点过度分段技术。
度量学习:
度量学习旨在学习具有与给定任务相对应的属性的数据点之间的相似函数[25]。在实际应用中,嵌入函数将每个数据点与调谐到给定目标的特征向量相关联。这些目标可以与分类[13,40]或聚类[42,19]以及许多其他应用相关(参见[2]了解有用的分类)。在深入学习的背景下,这可以通过使用精心选择的损失来实现,例如对比损失[8,5];三重损失[20]或其一些变体[48]。值得注意的是,度量学习最近被用于提高三维点语义分割任务的学习特征的质量[10]。然而,本文的任务是不同的,因为本文的嵌入是通过一个图划分问题而不是分类来实现的。
- Method
本文的目标是产生一个高质量的三维点云过分割,以便它可以反过来用于基于超点的语义分割算法。这转化为以下三个属性:
(P1)对象纯度:重叠点不能重叠在对象上,特别是当它们的语义不同时;
(P2)边界回忆:重叠点之间的界面必须与物体之间的边界重合;
(P3)规律性:重叠点的形状和轮廓必须简单。
本文的方法可以分为两个步骤:在第3.1节中,本文提出了局部云嵌入器,一个简单的神经网络,它将每个点与一个紧凑的嵌入相关联,该嵌入器捕获其局部几何和辐射测量。在第3.2节中,本文描述了如何使用基于图或基于簇的过分割算法从该嵌入计算点云过分割。
本文的目标是将一个紧凑的维度嵌入ei关联到每个点,该嵌入ei描述其点特征(位置、颜色等)及其局部邻域的几何和辐射测量。如[47]所建议,嵌入被限制在m单位球面Sm内,以防止在训练阶段崩溃,并使它们彼此之间的距离标准化。为此,本文引入了本地点嵌入器(LPE),这是一个受PointNet[36]启发的轻量级网络。
然而,与PointNet不同,LPE并不试图从整个输入点云中提取信息,而是基于纯本地信息对每个点进行编码。在这里,本文描述网络的不同单元。空间变换:该单元采用目标点pi及其局部k邻域pi的位置,如图2所示。它规范化了圆周率周围邻域的坐标,使得点位置的标准偏差等于1(3)。然后,利用由小点网络PTN(4)计算的2×2旋转矩阵,将该邻域绕z轴旋转。如[23]所倡导的,这些步骤旨在标准化每个点的邻域云的位置。这有助于下一个网络学习位置分布。

如前所述,语义纯度属性(P1)是超点的第一个质量。曾经可以想象,把估计(9)解的语义纯度的度量作为损失函数。然而,GMP是一个非连续的非凸优化问题,在图上计算连通分量是不可微的。这使得直接针对分区属性进行优化非常困难,甚至是不可能的。相反,本文注意到,如果实现了border recall属性(P2)(即,超级点和对象共享相同的边界),那么(P1)随之发生。因此,本文提出了一种称为图结构对比损失的替代损失,重点在于正确检测对象之间的边界。为此,本文定义了入口一组内部边缘为 同一对象内的点。

本文使用了一种改进版的“0-cut追踪算法”[26],主要有两个不同点:
•为了防止在高对比度区域产生许多小的超点,本文贪婪地合并(9)中定义的目标能量,只要它们小于给定的阈值;
•本文从[26]中试探性地改进了前进步骤(8),使得正则化强度沿着迭代几何地增加了一个因子(0.7)。
这有助于提高检索到的较低的optima的质量,从而提高过度分段的质量。 为了限制重叠点的大小,本文将它们的三维坐标嵌入(9)乘以参数αspatial,如[1]所示。 这决定了超级点可以达到的最大大小。在所有的实验中,本文把m的嵌入维数设为4。本文为LPE选择了一个光架构,参数小于15000。附录中详细说明了每个数据集的确切网络配置。

- Numerical Experiments
本文在两个不同性质的数据集上评估本文的方法。第一个是S3DIS[3],由办公室环境中房间的密集室内扫描组成。第二个是vKITTI[9],一个模拟稀疏激光雷达采集的室外城市场景数据集。注意,只有S3DIS有单独的对象注释。本文将vKITTI的对象看作是邻接图G中语义标签的连通成分,对于vKITTI,本文考虑了算法在有无颜色信息的情况下的性能。这两个数据集都是大规模的(S3DIS接近6亿点,vKITTI接近1500万点)。本文使用规则的体素网格对它们进行子采样(对于S3DIS为3cm宽,对于vKITTI为5cm宽)。在每个体素中,本文平均包含点的位置和颜色。这样可以减少计算时间和内存负载。

- Conclusions
在本文中,本文提出了第一个超级三维点云过分割框架。使用一个简单的点 嵌入网络和一个新的图形结构损失函数,本文能够实现显著的改善相比,最先进的点云过度分段。当与基于超点的语义分割方法相结合时,本文的方法也为语义分割的研究开辟了一个新的领域。
视频插图可在https://youtu.be/bKxU03tjLJ4上获取。源代码将在superpointgraph
repository2的更新中提供给社区和经过培训的网络。今后的工作将着重于改进广义最小分块问题的求解方法,以更好地处理球有界变量,提高其计算性能。
