原文地址:https://blog.csdn.net/zhanglh046/article/details/78485985
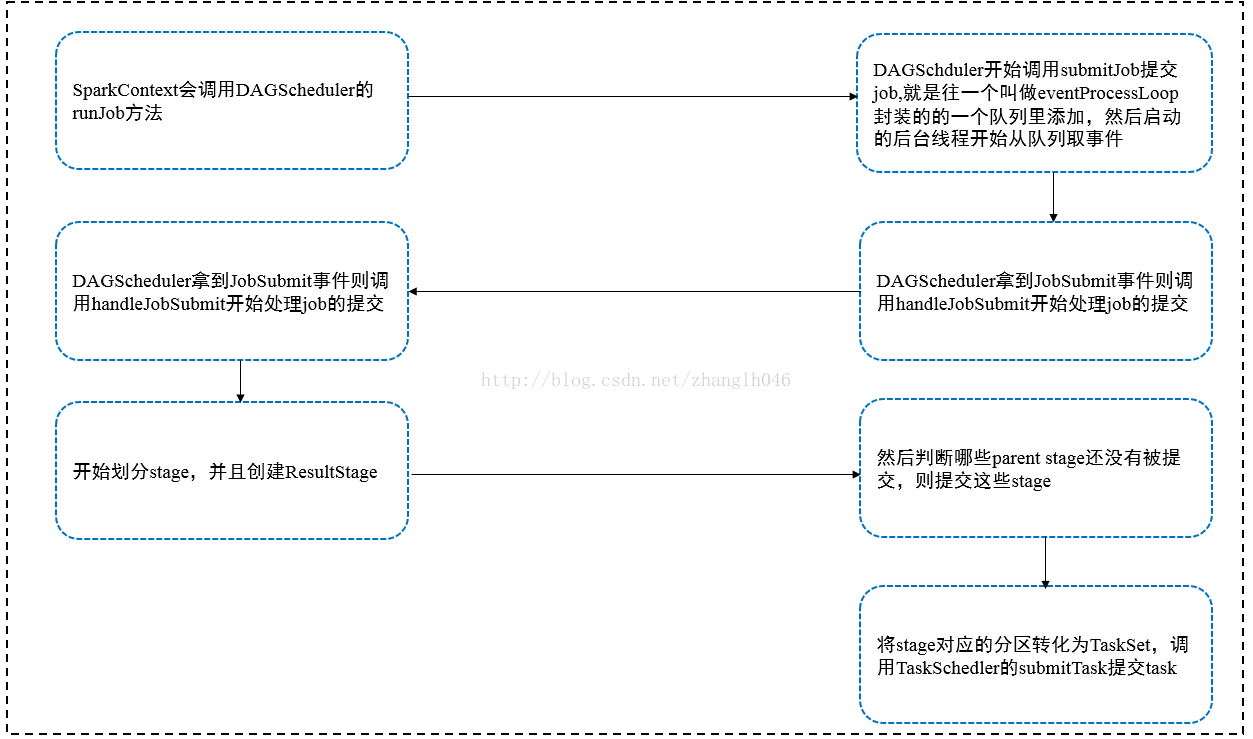
一、核心属性
- TaskScheduler taskScheduler: task调度器。
- AtomicInteger nextJobId:获取下一个jobId。
- Int numTotalJobs:job总数。
- AtomicInteger nextStageId: 下一个stageId。
- HashMap[Int, HashSet[Int]] jobIdToStageIds:jobId和对应的所有stageId的映射。
- HashMap[Int, Stage] stageIdToStage: stageId -> Stage映射。
- HashMap[Int, ShuffleMapStage] shuffleIdToMapStage:shufflleId 到MapStage之间的映射。
- HashMap[Int, ActiveJob] jobIdToActiveJob:jobId-> ActiveJob之间的映射。
- HashSet[Stage] waitingStages: 正处于等待的Stages。
- HashSet[Stage] runningStages:正处于运行阶段的Stages。
- HashSet[Stage] failedStages:正处于失败阶段的stages。
- HashSet[ActiveJob] activeJobs:激活的job。
- HashMap[Int, IndexedSeq[Seq[TaskLocation]]]cacheLocs: 每一个被缓存的RDD分区的位置,即RDD 的id -> 所有分区id(每一个分区的位置信息集合)。
- ScheduledExecutorService messageScheduler:后台单线程调度器。
- DAGSchedulerEventProcessLoop eventProcessLoop:一个缓存时间的队列,可以根据入队的事件,执行对应的方法。
二、重要方法
1、提交作业的处理
DAGScheduler在初始化的时候,就会启动eventProcessLoop,DAGSchedulerEventProcessLoop继承了EventLoop,启动之后,会启动一个后台线程,从队列BlockingQueue里取各种event,然后根据取出的event,进行不同的处理。
class DAGScheduler {
//……
eventProcessLoop.start()
}
abstract class EventLoop[E](name: String){
def start(): Unit = {
if (stopped.get) {
throw new IllegalStateException(name + " has already been stopped")
}
onStart()
eventThread.start()
}
private val eventThread = new Thread(name) {
// 设置成后台守护线程
setDaemon(true)
override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
}
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") with Logging {
private[this] val timer = dagScheduler.metricsSource.messageProcessingTimer
// 重载EventLoop的方法
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
}
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
// 如果是JobSubmitted,则调用handleJobSubmitted方法
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
// 如果是MapStageSubmitted,则调用handleMapStageSubmitted方法
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
// 如果是StageCancelled,则调用handleStageCancellation方法
case StageCancelled(stageId) =>
dagScheduler.handleStageCancellation(stageId)
// 如果是JobCancelled,则调用handleJobCancellation方法
case JobCancelled(jobId) =>
dagScheduler.handleJobCancellation(jobId)
// 如果是JobGroupCancelled,则调用handleJobGroupCancelled方法
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
// 如果是AllJobsCancelled,则调用doCancelAllJobs方法
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
// 如果是ExecutorAdded,则调用handleExecutorAdded方法
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
// 如果是ExecutorLost,则调用handleExecutorLost方法
case ExecutorLost(execId, reason) =>
val filesLost = reason match {
case SlaveLost(_, true) => true
case _ => false
}
dagScheduler.handleExecutorLost(execId, filesLost)
// 如果是BeginEvent,则调用handleBeginEvent方法
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
// 如果是GettingResultEvent,则调用handleGetTaskResult方法
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
// 如果是CompletionEvent,则调用handleTaskCompletion方法
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
// 如果是TaskSetFailed,则调用handleTaskSetFailed方法
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
// 如果是ResubmitFailedStages,则调用resubmitFailedStages方法
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
}
}
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
// 声明一个final的stage,ResultStage
var finalStage: ResultStage = null
try {
// 创建ResultStage这个final stage,如果是hadoopRDD,但是HDFS文件已经被删除,就会抛出异常
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
// 然后根据jobId,finalStage等信息创建一个Active Job
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
// 清除缓存的RDD对应的分区的位置信息
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
// 把新创建的job放到jobId->ActiveJob映射集合中
jobIdToActiveJob(jobId) = job
// acitve job集合添加这个job
activeJobs += job
// finalStage设置这个active job
finalStage.setActiveJob(job)
// 根据jobId取出对应的stageId列表
val stageIds = jobIdToStageIds(jobId).toArray
// 取出对应的Stage信息
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 提交Stage
submitStage(finalStage)
}2、stage的划分过程
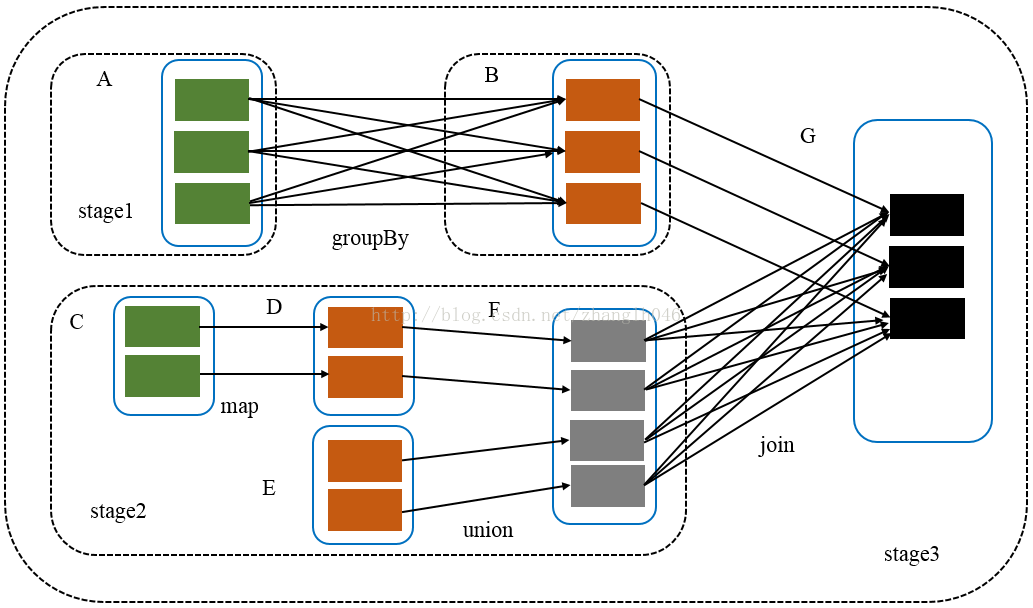
- 首先对finalRDD 调用creatResultStage方法,通过getOrCreateParentStages获取所有的parent stage列表作为parent stage,然后还需要创建自己本身的ResultStage,比如先创建上游的stage1 和 stage2,然后再创建自己stage3
- getOrCreateParentStages会调用 getShuffleDependencies 获得 G 所有直接宽依赖A和F,然后对A和F调用
- 对A调用getOrCreateShuffleMapStage, shuffleIdToMapStage 中获取判断为None, 对 A 调用 getMissingAncestorShuffleDependencies, 返回为空,因为它已经是最上游的RDD了,再调用createShuffleMapStage,由于A已经没有parent stage了,所以直接创建stage1 返回了
- 对F调用getOrCreateShuffleMapStage,shuffleIdToMapStage 中获取判断为None, 对 F 调用getMissingAncestorShuffleDependencies, 返回为空,因为其上游全是窄依赖,所以返回为空,然后对F调用createShuffleMapStage,直接创建stage2返回了
- 把 List(stage1,stage2) 作为 stage3 的 parents stages 创建 stage3
2.1 创建ResultStage
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
// 根据jobId获取或者创建该RDD的parent stage
val parents = getOrCreateParentStages(rdd, jobId)
// 产生下一个stage id
val id = nextStageId.getAndIncrement()
// 根据final RDD往后推计算出来的所有stage作为parent stage,然后将parent stage列表创建
// Result Stage,并且创建最后的stage
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
// 把这个stage放入DAGScheduler维护的映射列表中
stageIdToStage(id) = stage
// 更新jobId->stageId的映射
updateJobIdStageIdMaps(jobId, stage)
// 返回ResultStage
stage
}
2.2 创建或者获取ShuffleMapStage,将所有宽依赖划分出来的stage直接作为parent stages
// 将所有宽依赖划分出来的stage直接作为parent stages
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
// 遍历final RDD中直接获取的宽依赖,然后递归创建ShuffleMapStage
// 并且将所有上游或者祖先的stage全部返回,以供创建ResultStage
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
2.3 获取宽依赖的集合
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
// 用于存放宽依赖的集合
val parents = new HashSet[ShuffleDependency[_, _, _]]
// 存放已经访问过的RDD集合
val visited = new HashSet[RDD[_]]
// 存放处于等待访问状态的RDD,最后被放入的最先出栈
val waitingForVisit = new Stack[RDD[_]]
// 初始RDD的先放入等待的栈中
waitingForVisit.push(rdd)
// 只要等待访问的栈不为空
while (waitingForVisit.nonEmpty) {
// 就弹出第一个RDD
val toVisit = waitingForVisit.pop()
// 只要这个RDD还没有被访问过
if (!visited(toVisit)) {
// 添加到访问过的rdd集合中
visited += toVisit
// 获取这个RDD的依赖列表,然后遍历依赖
toVisit.dependencies.foreach {
// 如果是宽依赖,则添加该依赖到宽依赖的集合
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
// 窄依赖的话直接放到等待队列,等待下一次被弹出,继续遍历
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
2.4 获取或者创建ShuffleMapStage
private def getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
// 看是否存在该shuffleId
shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
// 如果存在直接返回对应的ShuffleMapStage
case Some(stage) =>
stage
// 否则创建ShuffleMapStage
case None =>
// 为final RDD的所有直接宽依赖查找上游或者祖先还有哪一些宽依赖,并且根据栈里的顺序
// 创建stage
getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
// 如果不存在这个shuffleId,则创建
if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
createShuffleMapStage(dep, firstJobId)
}
}
// 如果final RDD的所有直接宽依赖都没有上游或者祖先的宽依赖,则直接创建stage
createShuffleMapStage(shuffleDep, firstJobId)
}
}
2.5 当finalRDD 的直接宽依赖的上游或者祖先还存在宽依赖,我们需要全部查找出来
private def getMissingAncestorShuffleDependencies(
rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = {
// 声明一个ancestor的栈数据结构存放宽依赖
val ancestors = new Stack[ShuffleDependency[_, _, _]]
// 存放应访问过的RDD
val visited = new HashSet[RDD[_]]
// 处于等待访问的RDD栈
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
// 弹出这个RDD
val toVisit = waitingForVisit.pop()
// 如果还没被访问过
if (!visited(toVisit)) {
// 添加到访问过的RDD集合
visited += toVisit
// 根据RDD获取宽依赖集合
getShuffleDependencies(toVisit).foreach { shuffleDep =>
// 查看该shuffleId是否已经存在
if (!shuffleIdToMapStage.contains(shuffleDep.shuffleId)) {
// 如果不包含则放入ancestor堆栈
ancestors.push(shuffleDep)
// 并且该RDD放入等待访问列表,如果继续有宽依赖,则继续放入ancestor中
waitingForVisit.push(shuffleDep.rdd)
} // 否则依赖和他的祖先已经注册了
}
}
}
ancestors
}3、 提交Stage
生成finalStage的同时建立起所有stage依赖关系,然后通过finalStage生成一个作业实例,最后提交调度阶段
private def submitStage(stage: Stage) {
// 获取该stage对应的jobId
val jobId = activeJobForStage(stage)
// 检查该jobId是否有效
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
// 如果stage既不处于等待阶段也不处于运行节点,而且还不是失败的stage即该stage还没有开始处理
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 获取stage还没有提交的parent stage
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
// 如果不存在没有提交的parent stage,则直接把该stage进行提交
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
// 如果存在没有提交的parent stage,则把该stage加入到等待运行的stage列表中,同时递归调用submitStage方法
// 直到找到开始的调度阶段
for (parent <- missing) {
submitStage(parent)
}
// 然后该stage放入到等待stage列表中
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
4、获取stage还没有提交的parent stage
private def getMissingParentStages(stage: Stage): List[Stage] = {
// 存在parent stage的stage
val missing = new HashSet[Stage]
// 访问过的RDD集合
val visited = new HashSet[RDD[_]]
// 处于等待访问状态的RDD的栈
val waitingForVisit = new Stack[RDD[_]]
def visit(rdd: RDD[_]) {
// 如果指定RDD还没有被访问过
if (!visited(rdd)) {
// 添加到访问过的RDD集合中
visited += rdd
// RDD是否有没有被缓存的分区
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
// 如果有为被缓存的分区
if (rddHasUncachedPartitions) {
// 遍历该RDD的依赖
for (dep <- rdd.dependencies) {
dep match {
// 如果是宽依赖
case shufDep: ShuffleDependency[_, _, _] =>
// 创建ShuffleMapStage
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
// 如果该宽依赖还有未被提交的stage,则添加该stage到missing中
if (!mapStage.isAvailable) {
missing += mapStage
}
// 如果是窄依赖,则直接放入访问等待栈
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
// 返回parent stage列表
missing.toList
}
5、提交任务
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// 将正在添加的分区集合里的信息清空
stage.pendingPartitions.clear()
// 标志出将要计算的分区的索引,即还没有被计算的分区
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
val properties = jobIdToActiveJob(jobId).properties
// 将该stage添加到正在运行的stage
runningStages += stage
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
// 获取<taskId,Seq[TaskLocation]>映射
//每一个分区创建一个task,给每一个task计算最佳的位置,然后生成<partitionId,以及该分区所对应的最佳位置>映射
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
// 为stage创建新的尝试
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// 我们可能需要保持在stage里的task以避免序列化多次
// 广播task的二进制,用于分发task到executors,注意我们广播序列化RDD和每一个task的副本,我们将要反序列化
// 这既意味着task会获取不同的RDD副本
var taskBinary: Broadcast[Array[Byte]] = null
try {
// 对于ShuffleMapTask,序列化和广播(rdd,shuffleDep)
// 对于ResultTask,序列化和广播(rdd,func)
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
// 广播task的二进制数据
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
// 开始构建task
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
// 获取task所在的location
val locs = taskIdToLocations(id)
// 获取对应的partition
val part = stage.rdd.partitions(id)
// 创建ShuffleMapTask
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
// 获取分区
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
// 获取task所在的location
val locs = taskIdToLocations(id)
// 创建ResultTask
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
if (tasks.size > 0) {
logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
// 将task里对应的分区的id将入到pendingPartitions
stage.pendingPartitions ++= tasks.map(_.partitionId)
logDebug("New pending partitions: " + stage.pendingPartitions)
// 将stage对应的task集合封装成TaskSet,调用TaskScheduler的submitTasks开始提交任务
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
// 如果stage不存在任务标记,则表示stage已经调度完成
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
//提交该Stage的正在等在的Child Stages
submitWaitingChildStages(stage)
}
}
6、handleTaskCompletion处理任务完成
private[scheduler] def handleTaskCompletion(event: CompletionEvent) {
// 根据CompletionEvent获取task信息以及stageId
val task = event.task
val taskId = event.taskInfo.id
val stageId = task.stageId
val taskType = Utils.getFormattedClassName(task)
outputCommitCoordinator.taskCompleted(
stageId,
task.partitionId,
event.taskInfo.attemptNumber, // this is a taskattempt number
event.reason)
// Reconstructtask metrics. Note: this may be null if the task has failed.
val taskMetrics: TaskMetrics =
if (event.accumUpdates.nonEmpty) {
try {
TaskMetrics.fromAccumulators(event.accumUpdates)
} catch {
case NonFatal(e) =>
logError(s"Error when attempting to reconstruct metrics for task $taskId", e)
null
}
} else {
null
}
// 向ListenerBus上广播CompletionEvent的事件
listenerBus.post(SparkListenerTaskEnd(
stageId, task.stageAttemptId, taskType, event.reason, event.taskInfo, taskMetrics))
// 如果当前stage已经被取消,则直接返回
if (!stageIdToStage.contains(task.stageId)) {
// Skip allthe actions if the stage has been cancelled.
return
}
val stage = stageIdToStage(task.stageId)
event.reason match {
// 如果处理task成功
case Success =>
// 从stage的pendingPartitions移除当前task对应的partitionId
stage.pendingPartitions -= task.partitionId
task match {
// 如果是ResultTask
case rt: ResultTask[_, _] =>
val resultStage = stage.asInstanceOf[ResultStage]
resultStage.activeJob match {
// 如果ResultStage对应的job还存在
case Some(job) =>
// 判断该stage上如果还有分区未完成
if (!job.finished(rt.outputId)) {
// 更新accumulator
updateAccumulators(event)
// 将该stage标记为完成,因为这是最后一个stage,所以只要stage完成了,表示job已经完成
job.finished(rt.outputId) = true
job.numFinished += 1
// 如果整个job已经完成
if (job.numFinished == job.numPartitions) {
// 标记该stage已经完成,然后从runningStages中移除
markStageAsFinished(resultStage)
// 清理job的状态和stage
cleanupStateForJobAndIndependentStages(job)
// 向ListenerBus上广播JobSucceeded的事件
listenerBus.post(
SparkListenerJobEnd(job.jobId, clock.getTimeMillis(), JobSucceeded))
}
// 触发JobWaiter的taskSucceeded方法
try {
job.listener.taskSucceeded(rt.outputId, event.result)
} catch {
case e: Exception =>
// TODO: Perhaps we want to mark the resultStage asfailed?
job.listener.jobFailed(new SparkDriverExecutionException(e))
}
}
// 如果ResultStage对应的job已经完成
case None =>
logInfo("Ignoring result from " + rt + " because its job has finished")
}
// 如果是ShuffleMapTask
case smt: ShuffleMapTask =>
// 获取ShuffleMapStage
val shuffleStage = stage.asInstanceOf[ShuffleMapStage]
// 更新累加器
updateAccumulators(event)
// 获取map状态和executorId
val status = event.result.asInstanceOf[MapStatus]
val execId = status.location.executorId
logDebug("ShuffleMapTask finished on " + execId)
if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) {
logInfo(s"Ignoring possibly bogus $smt completion from executor $execId")
} else {
shuffleStage.addOutputLoc(smt.partitionId, status)
}
// 如果runningStages还包括该ShuffleMapStage,
// 但是ShuffleMapStage所有分区已经完成计算,表示该stage已经完成
if (runningStages.contains(shuffleStage) && shuffleStage.pendingPartitions.isEmpty) {
// 标记shuffleStage已经完成
markStageAsFinished(shuffleStage)
logInfo("looking for newly runnable stages")
logInfo("running: " + runningStages)
logInfo("waiting: " + waitingStages)
logInfo("failed: " + failedStages)
mapOutputTracker.registerMapOutputs(
shuffleStage.shuffleDep.shuffleId,
shuffleStage.outputLocInMapOutputTrackerFormat(),
changeEpoch= true)
// 清理缓存的分区对应location信息
clearCacheLocs()
// 如果有task失败,我们重新提交shuffleStage
if (!shuffleStage.isAvailable) {
submitStage(shuffleStage)
} else {
// 标记所有job的map stage已经完成
if (shuffleStage.mapStageJobs.nonEmpty) {
val stats = mapOutputTracker.getStatistics(shuffleStage.shuffleDep)
for (job <- shuffleStage.mapStageJobs) {
markMapStageJobAsFinished(job, stats)
}
}
//提交该Stage的正在等在的Child Stages
submitWaitingChildStages(shuffleStage)
}
}
}
// 如果是重新提交,则把task对应的分区重新添加到stage的pendingPartitions
case Resubmitted =>
logInfo("Resubmitted " + task + ", so marking it as still running")
stage.pendingPartitions += task.partitionId
// 如果获取失败
case FetchFailed(bmAddress, shuffleId, mapId, reduceId, failureMessage) =>
// 获取对应失败的stage
val failedStage = stageIdToStage(task.stageId)
// 获取shuffleId对应的MapStage
val mapStage = shuffleIdToMapStage(shuffleId)
if (failedStage.latestInfo.attemptId != task.stageAttemptId) {
logInfo(s"Ignoring fetch failure from $task as it's from $failedStage attempt" +
s" ${task.stageAttemptId} and there is a more recentattempt for that stage " +
s"(attemptID ${failedStage.latestInfo.attemptId}) running")
} else {
// 若果runningStages包含failedStage
if (runningStages.contains(failedStage)) {
logInfo(s"Marking $failedStage (${failedStage.name}) as failed " +
s"due toa fetch failure from $mapStage (${mapStage.name})")
markStageAsFinished(failedStage, Some(failureMessage))
} else {
logDebug(s"Received fetch failure from $task, but its from $failedStage which is no " +
s"longerrunning")
}
if (disallowStageRetryForTest) {
abortStage(failedStage, "Fetch failure will notretry stage due to testing config",
None)
} else if (failedStage.failedOnFetchAndShouldAbort(task.stageAttemptId)) {
abortStage(failedStage, s"$failedStage (${failedStage.name}) " +
s"hasfailed the maximum allowable number of " +
s"times: ${Stage.MAX_CONSECUTIVE_FETCH_FAILURES}. " +
s"Mostrecent failure reason: ${failureMessage}", None)
} else {
if (failedStages.isEmpty) {
// Don'tschedule an event to resubmit failed stages if failed isn't empty, because
// in that case the eventwill already have been scheduled.
// TODO: Cancel running tasks in the stage
logInfo(s"Resubmitting $mapStage (${mapStage.name}) and " +
s"$failedStage (${failedStage.name}) due to fetch failure")
messageScheduler.schedule(new Runnable {
override def run(): Unit = eventProcessLoop.post(ResubmitFailedStages)
}, DAGScheduler.RESUBMIT_TIMEOUT, TimeUnit.MILLISECONDS)
}
failedStages += failedStage
failedStages += mapStage
}
// Mark themap whose fetch failed as broken in the map stage
if (mapId != -1) {
mapStage.removeOutputLoc(mapId, bmAddress)
mapOutputTracker.unregisterMapOutput(shuffleId, mapId, bmAddress)
}
// TODO: mark the executor as failed only if there were lots of fetchfailures on it
if (bmAddress != null) {
handleExecutorLost(bmAddress.executorId, filesLost = true, Some(task.epoch))
}
}
case commitDenied: TaskCommitDenied =>
// Do nothinghere, left up to the TaskScheduler to decide how to handle denied commits
case exceptionFailure: ExceptionFailure=>
// Tasks failedwith exceptions might still have accumulator updates.
updateAccumulators(event)
case TaskResultLost =>
// Do nothinghere; the TaskScheduler handles these failures and resubmits the task.
case _: ExecutorLostFailure | TaskKilled | UnknownReason =>
//Unrecognized failure - also do nothing. If the task fails repeatedly, theTaskScheduler
// will abort the job.
}
}
7、handleStageCancellation 取消stage
private[scheduler] def handleStageCancellation(stageId: Int) {
// 获取该stage,如果存在,贼取消job
stageIdToStage.get(stageId) match {
case Some(stage) =>
val jobsThatUseStage: Array[Int] = stage.jobIds.toArray
jobsThatUseStage.foreach { jobId =>
handleJobCancellation(jobId, s"because Stage $stageId was cancelled")
}
case None =>
logInfo("No active jobs to kill for Stage " + stageId)
}
}
8、handleJobCancellation 取消job
private[scheduler] def handleJobCancellation(jobId: Int, reason: String = "") {
// 如果没有注册的job,取消了什么都不用做
if (!jobIdToStageIds.contains(jobId)) {
logDebug("Trying to cancel unregistered job " + jobId)
} else {
failJobAndIndependentStages(
jobIdToActiveJob(jobId), "Job %d cancelled %s".format(jobId, reason))
}
}
private def failJobAndIndependentStages(
job: ActiveJob,
failureReason: String,
exception: Option[Throwable] = None): Unit = {
val error = new SparkException(failureReason, exception.getOrElse(null))
var ableToCancelStages = true
val shouldInterruptThread=
if (job.properties == null) false
else job.properties.getProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL, "false").toBoolean
// Cancel allindependent, running stages.
// 根据job取出所有的stage id
val stages = jobIdToStageIds(job.jobId)
if (stages.isEmpty) {
logError("No stages registered for job " + job.jobId)
}
stages.foreach { stageId =>
val jobsForStage: Option[HashSet[Int]] = stageIdToStage.get(stageId).map(_.jobIds)
if (jobsForStage.isEmpty || !jobsForStage.get.contains(job.jobId)) {
logError(
"Job %dnot registered for stage %d even though that stage was registered for thejob"
.format(job.jobId, stageId))
} else if (jobsForStage.get.size == 1) {
// 如果找不到该stage则抛出错误
if (!stageIdToStage.contains(stageId)) {
logError(s"Missing Stage for stage with id $stageId")
} else {
// 调用taskScheduler取消task,并且标记stage已经完成
val stage = stageIdToStage(stageId)
if (runningStages.contains(stage)) {
try { // cancelTasks will fail if a SchedulerBackend does not implementkillTask
taskScheduler.cancelTasks(stageId, shouldInterruptThread)
markStageAsFinished(stage, Some(failureReason))
} catch {
case e: UnsupportedOperationException =>
logInfo(s"Could not cancel tasks for stage $stageId", e)
ableToCancelStages= false
}
}
}
}
}
if (ableToCancelStages) {
// SPARK-15783important to cleanup state first, just for tests where we have some asserts
// against the state. Otherwise we have a *little* bit of flakinessin the tests.
cleanupStateForJobAndIndependentStages(job)
job.listener.jobFailed(error)
listenerBus.post(SparkListenerJobEnd(job.jobId, clock.getTimeMillis(), JobFailed(error)))
}
}
9、doCancelAllJobs 取消所有的job
private[scheduler] def doCancelAllJobs() {
// Cancel allrunning jobs.
runningStages.map(_.firstJobId).foreach(handleJobCancellation(_,
reason = "as part of cancellation of all jobs"))
activeJobs.clear() // These should already be empty by this point,
jobIdToActiveJob.clear() // but just in case we lost track of some jobs...
}
10、resubmitFailedStages 重新提交失败的stage
private[scheduler] def resubmitFailedStages() {
if (failedStages.size > 0) {
logInfo("Resubmitting failed stages")
clearCacheLocs()
val failedStagesCopy = failedStages.toArray
failedStages.clear()
for (stage <- failedStagesCopy.sortBy(_.firstJobId)) {
submitStage(stage)
}
}
}