背景: 前几天了解了spark了运行架构,spark代码提交给driver时候会根据rdd生成DAG,那么实际DAG在代码中是如何生成的呢?
首先了解,spark任务中的几个划分点:
1.job:job是由rdd的action来划分,每一个action操作是在spark任务执行时是一个job。(action的区分:rdd分为行动操作和转化操作,因为我们知道rdd是惰性加载的,除非遇到行动操作,前面的所有的转化操作才会执行,这也就是为什么spark任务由job来划分执行了,区分行动操作和转化操作最简单的方法就是看,rdd放回的值,如果返回的是一个rdd则是转化操作,例如map,如果返回的是一个其他的数据类型则是行动操作,例如count)
2.stage:根据rdd的宽窄依赖来划分(shuffle来区分),遇到shuffle,则将shuffle之前的窄依赖归来一个stage;
3.task:task是由最后的executor执行的最小任务,它最终落到各个executor上,实现分布式执行;
简单的归纳一下他们的关系:job -> stage -> task (job中有多个stage,stage中有多个task);
spark运行时,一个任务由client提交,再由driver划分逻辑实现图DAG,最后分配给各个executor上执行task;
思考:任务是如何分配监听的?hash分配,随机分配?
spark在任务拆分的时候,参考下图:
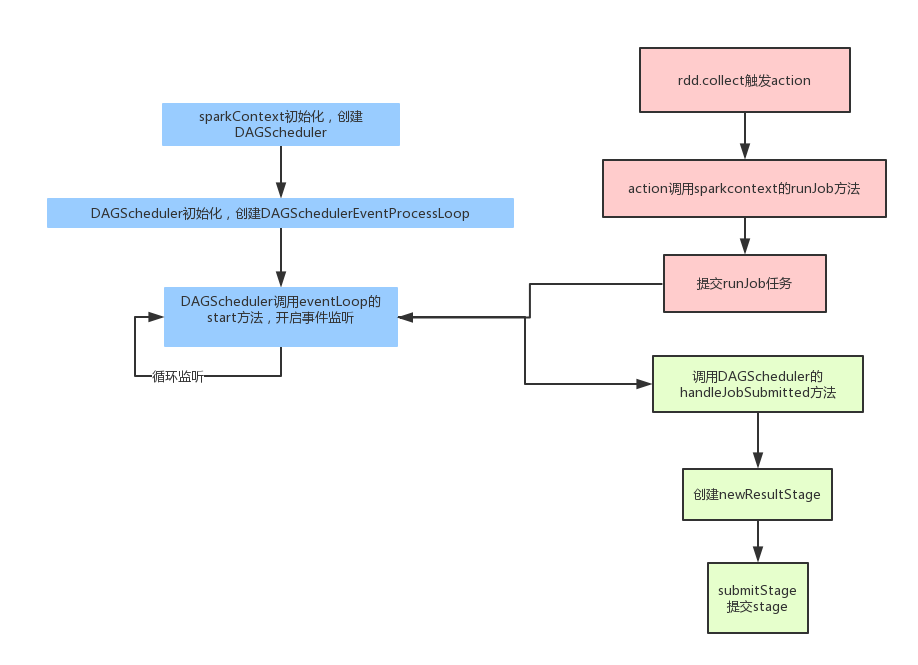
1.先由sparkcontext初始化,创建一个DAGshcheduler,启动一个监听器,监听spark任务,spark拆分的所有任务都会发给这个监听器;
2.客户端这边,当我们调用action时,则action会向sparkcontext启动一个runjob,即是将action任务(一个job)提交给DAGshcheduler的监听器;
3.接到job的DAGscheduler 会将任务交给handleJobSubmitted 来处理;
4. 未来待续。。。。