1, pandas生成时间一般采用date_range操作,这个之前的博客已经详细的讲解过,这里就不在阐述
2, pandas的数据重采样
什么是数据重采样?
就好比原来一堆统计数据是按照天来进行统计的,持续一年;
那我们能不能看月整体变化的程度呢?
那这个时候就涉及到数据的重采样问题,按照上述的例子:由天变为月,那这个就是一个降采样的过程,那既然有降采样,那必定也有升采样。
那如何使用pandas完成将采样和升采样呢?
rng = pd.date_range('1/1/2011',periods=90, freq='D') ts = pd.Series(np.random.randn(len(rng)), index=rng) ts.head() # 降采样 ts.resample('M').sum() # pandas使用resample方法来进行重采样,统计的指标的sum,当然可以是mean ts.resample('3D').sum() # 当然也可以指定是一个周期 # 升采样 day3d.resample('D').safreq()) # 我们会发现,部分有了空值NAN但是出现NAN会影响我们的统计所以 # ffill 空值取前面的值 # bfill 空值取后面的值 # interpolate 线性取值 day3d.resample('D').ffill(1) # 对于空值取前面的一个数据进行一个值得填充 day3d.resample('D').interpolate('linear') # 对相邻的两个点之间取线性的值
3,pandas的滑动窗口

看一张图:假如我的时间数据是2016年到2017年的,我想看其中2月5日的情况
假如我只看2月5日的值就未免太过绝对,因此,我们取2月5日附近的均值,那这样就显得更加科学一点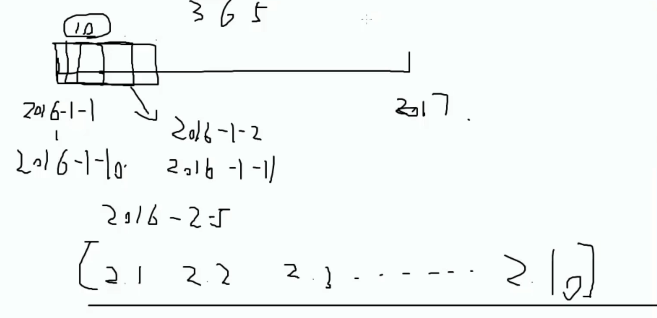
滑动窗口的意思就是取滑动的步长,由确定点的右侧一个步长到,点左侧的一个步长,求均值,这样统计出来的数据就会更加规范,那pandas怎么用滑动窗口呢?
df = pd.Series(np.random.randn(600), index=pd.date_range('7/1/2016', freq='D', periods=600)) df.head() r = df.rolling(window=10) # 可以设置center等,默认滑动是从左往右的 可以取得均值 r.mean()
import matplotlib.pyplot as plt plt.figure(figsize=(15,5)) df.plot(style='r--') df.rolling(window=10).mean().plot(style='b')
图如下:是不是变得平滑许多?

5,ARIMA模型
平稳性的要求序列的均值和方差不发生明显变化
如何处理让数据变得更加平稳呢?

何为差分法呢?
差分法就是用t2-t1, t3-t2依次类推得到的差值进行统计所的出的图像
那pandas怎么去实现差分法呢?
data = pd.read_csv('x.csv') data['diff_01] = data['values_colunm'].diff(1) # 相差一个时间间隔的点
但是这里有个注意点:二阶差分是在一阶差分的基础上进行一阶差分,才是二阶差分,不是在原始数据上直接diff(2)


自回归模型:
①描述当前值和历史值之间的关系,用变量的自身的历史数据对自身进行预测
②自回归模型必须满足平稳性的要求
③p阶自回归过程的公式定义: 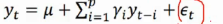
④
自回归模型的限制:
1,自回归模型是用自身的数据进行预测
2,必须具有平稳性
3,必须具有自相关性,如果自相关系数(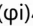 )小于0.5,则不宜采用
)小于0.5,则不宜采用
4,自回归只适用于预测和自身前期相关的现象
移动平均模型:
1,移动平均模型关注的是自回归模型中的误差项的累加
2,q阶自回归过程的公式定义:
3,移动平均法能够有效的消除预测中的随机波动
自回归移动平均模型(ARMA)
1,自回归与移动平均的结合
2,公式的定义:
(p是自回归模型的阶数,q是移动平均模型的阶数,d是查分的阶数(一般使用一阶差分即d=1))
ARIMA(p,d,q)模型全称为差分自回归移动平均模型
AR是自回归,p为自回归项;MA为移动平均,q为移动平均数,d为时间序列成为平稳时所作的差分次数
原理:将非平稳时间序列转化为平稳时间序列然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型
自相关函数ACF(帮助我们选择p值和q值得合适值)
1,有序的随机变量序列与其自身相比较,自相关函数反应了同一序列在不同时序取值之间的相关性
2,公式:
3,Pk的取值范围为[-1,1](相关性)
那ARIMA建模的流程:
①将序列平稳
②p和q阶数确定:ACF和PACF
③ARIMA(pdq)
#arima时序模型 import pandas as pd #参数初始化 discfile = 'data.xls' forecastnum = 5 #读取数据,指定日期列为指标,Pandas自动将“日期”列识别为Datetime格式 data = pd.read_excel(discfile, index_col = u'日期') #时序图 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 data.plot() plt.show() #自相关图 from statsmodels.graphics.tsaplots import plot_acf plot_acf(data).show() #平稳性检测 from statsmodels.tsa.stattools import adfuller as ADF print(u'原始序列的ADF检验结果为:', ADF(data[u'销量'])) #返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore #差分后的结果 D_data = data.diff().dropna() D_data.columns = [u'销量差分'] D_data.plot() #时序图 plt.show() plot_acf(D_data).show() #自相关图 from statsmodels.graphics.tsaplots import plot_pacf plot_pacf(D_data).show() #偏自相关图 print(u'差分序列的ADF检验结果为:', ADF(D_data[u'销量差分'])) #平稳性检测 #白噪声检验 from statsmodels.stats.diagnostic import acorr_ljungbox print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) #返回统计量和p值 from statsmodels.tsa.arima_model import ARIMA data[u'销量'] = data[u'销量'].astype(float) #定阶 pmax = int(len(D_data)/10) #一般阶数不超过length/10 qmax = int(len(D_data)/10) #一般阶数不超过length/10 bic_matrix = [] #bic矩阵 for p in range(pmax+1): tmp = [] for q in range(qmax+1): try: #存在部分报错,所以用try来跳过报错。 tmp.append(ARIMA(data, (p,1,q)).fit().bic) except: tmp.append(None) bic_matrix.append(tmp) #从中可以找出最小值 bic_matrix = pd.DataFrame(bic_matrix) #先用stack展平,然后用idxmin找出最小值位置。 p,q = bic_matrix.stack().idxmin() print(u'BIC最小的p值和q值为:%s、%s' %(p,q)) #建立ARIMA(0, 1, 1)模型 model = ARIMA(data, (p,1,q)).fit() #给出一份模型报告 print(model.summary2()) #作为期5天的预测,返回预测结果、标准误差、置信区间。 print(model.forecast(5)) # 结果如下: BIC最小的p值和q值为:0、1 Results: ARIMA ==================================================================== Model: ARIMA BIC: 422.5101 Dependent Variable: D.销量 Log-Likelihood: -205.88 Date: 2018-12-23 21:47 Scale: 1.0000 No. Observations: 36 Method: css-mle Df Model: 2 Sample: 01-02-2015 Df Residuals: 34 02-06-2015 Converged: 1.0000 S.D. of innovations: 73.086 AIC: 417.7595 HQIC: 419.418 ---------------------------------------------------------------------- Coef. Std.Err. t P>|t| [0.025 0.975] ---------------------------------------------------------------------- const 49.9555 20.1390 2.4805 0.0182 10.4838 89.4272 ma.L1.D.销量 0.6710 0.1648 4.0712 0.0003 0.3480 0.9941 ----------------------------------------------------------------------------- Real Imaginary Modulus Frequency ----------------------------------------------------------------------------- MA.1 -1.4902 0.0000 1.4902 0.5000 ==================================================================== (array([4873.96625288, 4923.92173955, 4973.87722621, 5023.83271288, 5073.78819955]), array([ 73.08574135, 142.32683622, 187.54287785, 223.8028904 , 254.95712673]), array([[4730.72083205, 5017.2116737 ], [4644.96626651, 5202.87721258], [4606.29994008, 5341.45451235], [4585.18710806, 5462.4783177 ], [4574.08141355, 5573.49498555]]))
python主要时序模式算法:
Python实现时序模式主要的库是StatsModels,算法主要是ARIMA模型,在使用该模型进行建模时需要进行一系列的判别操作,主要包含平稳性检测,白噪声检测,是否差分,AIC和BIC指标值,模型定阶,最后在做预测
时序模式算法函数列表如下:
| 函数名 | 函数功能 | 所属工具箱 |
| acf() | 计算自相关系数 | statsmodels.tsa.stattools |
| plot_acf() | 绘制自相关系数图 | statsmodels.graphics.tsaplots |
| pacf() | 计算偏相关系数 | statsmodels.tsa.stattools |
| plot_pacf() | 绘制偏相关系数图 | statsmodels.graphics.tsaplots |
| adfuller() | 对观测值序列进行单位根检验 | statsmodels.tsa.stattools |
| diff() | 对观测值序列进行差分计算 | Pandas方法 |
| ARIMA() | 创建一个ARIMA的时序模型 | statsmodels.tsa.arima_model |
| summary()或summary2 | 给出一份ARIMA模型报告 | ARIMA模型自带方法 |
| aic/bic/hqic | 计算ARIMA模型的AIC/BIC/HQIC指标值 | ARIMA模型自带方法 |
| forecast() | 应用构建的时序模型进行预测 | ARIMA模型自带方法 |
| accor_ljungbox() | Ljung-Box检验,检验是否为白噪声 | statsmodels.stats.diagnostic |
1,acf()
功能:计算自相关系数
使用方法:
autoaorr = acf(data, unbiased=False,nlags=40,qstat=False,fft=False,alpha=None)
输入的data为观测值序列(即时间序列,可以是DataFrame或者是Series),返回参数autocorr为观测值序列自相关函数。其余为可选参数,如qstat=True时同时返回Q统计量和对应的p值
2,plot_acf()
功能:绘制自相关系数图
使用方法:
p = plot_acf(data)
返回matplotlib对象,调用show()方法显示
3,pacf()/plot_pacf()与上面两个一致
4,adfuller()
功能:对时间序列进行单位根检验(ADF test)
使用方法:
h=adfuller(Series, maxlag=None,regression='c',autolag='AIC',store=False,regresults=False)
输入参数Series为一维观测值序列,返回值依次为:adf,pvalue,uselag,nobs,critical values,icbest,regresults,resstore
5,diff()
功能:对时间序列进行差分计算
使用方法:
D.diff() D可以是DataFrame或者是Series
6,arima
功能:设置时序模式的建模参数,创建ARIMA时序模型
使用方法:
arima = ARIMA(data,(p,l,q)).fit()
data参数为输入的时间序列,p,q是对应的阶,d为差分次数
7,summary()/summary2()
功能:生成已有模型的报告
使用方法:
arima.summary()或arima.summary2()
其中arima为已经建好的ARIMA模型,返回一份格式化的模型报告,包含模型的系数,标准误差,p值,AIC和BIC等详细指标
8,aic/bic/hqic
功能:计算ARIMA模型的AIC/BIC/HQIC指标值
使用方法:
arima.aic
其中arima为已经建立好的ARIMA,返回值是Model时序模型得到的AIC,BIC和HQIC值
9,forecast()
功能:用得到的时序模型进行预测
使用方法:
a,b,c = arima.forecast(num)
输入参数num为要预测的天数,arima为已经建立好的ARIMA模型。a为返回天数的预测值,b为预测的误差,c为预测的置信区间
10,acorr_ljungbox()
功能:检测是否为白噪声序列
使用方法:
acorr_ljungbox(data, lags=1)
输入参数data为时间序列数据,lags为滞后数,返回统计量和p值