Python scrapy 框架之爬取腾讯和360
如遇到什么问题请联系:3440037784这个qq,当然也可以要下视频源码笔记
本章所讲内容:
1、Python scrapy 安装以及必要过的坑
2、Python scrapy 使用规范,让开发效率更好
3、Python scrapy 必会的爬取技巧
实战:利用爬虫框架scrapy ,爬取JavaScript动态加载网页,分析json文件格式内容,并将360图片下载到本地文件夹下
实战:利用scrapy爬取,腾讯招聘网站职业信息,保存到本地路径下

1、Python scrapy 介绍
1.1 Python scrapy 介绍 爬虫框架
爬虫(spider,网络蜘蛛):爬虫(spider,网络蜘蛛):模拟浏览器获取服务器资源的脚本。网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据。
框架:对同一类型的项目共性代码的封装
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
让我们来看下它的基本结构:

Scrapy主要包括了以下组件:

1、引擎,用来处理整个系统的数据流处理,触发事务。
2、调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
3、下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
4、蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
5、项目管道,负责处理有蜘蛛从网页中抽取的项目,它的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6、下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7、蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
8、调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
注:Scrapy 官方网站:http://scrapy.org/
1.2 Scrapy 安装
Pip install scrapy==1.5.1
Pywin32
Twisted
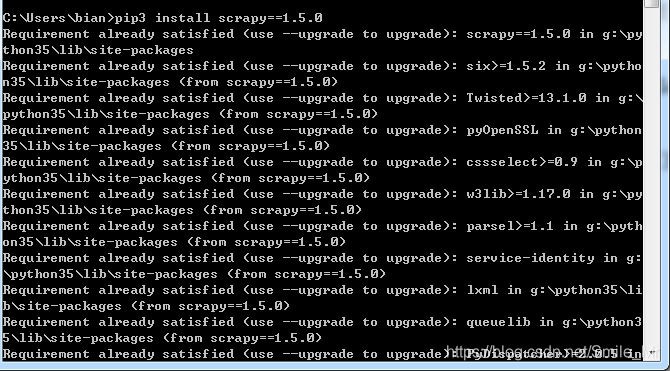
假如报关于Vc++ 14.0 。。。。。。的错误

因为你当前的Python和系统的vc版本比较低
更新vc
安装twisted.whl包
pip install wheel
pip install twisted.whl
假如错误入学
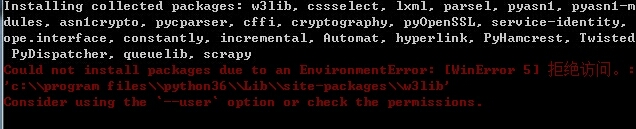
网络是不是完好
我们可以用pip install scrapy –i 国内源
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
2、Python scrapy 使用
安装成功: 直接在cmd下执行命令 scrapy version

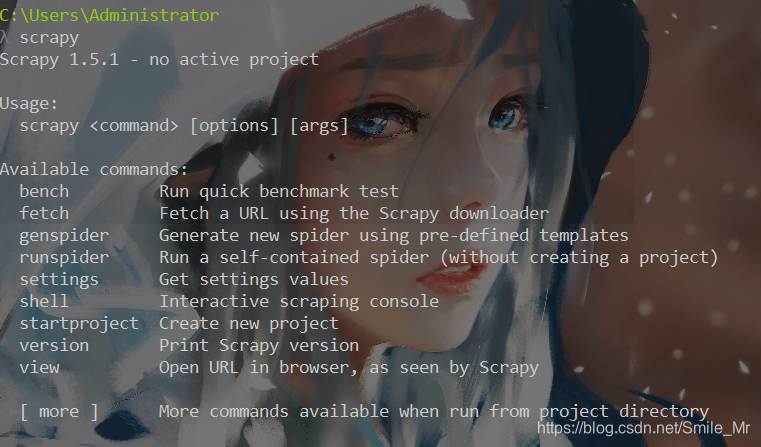
3、scrapy 爬取实战
实战:利用爬虫框架scrapy ,爬取JavaScript动态加载网页,将图片下载到本地。
第一步: 创建项目
第二步: 配置文件settings.py,关闭robots协议
第三步: 编写Item.py文件
第四步: spider的编写
第五步: 执行scrapy
第一步:
Scrapy startproject so_image
cd so_image
Scrapy genspider images image.so.com
第二步:
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
# 'so_images.pipelines.SoImagesPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1,
}
IMAGES_STORE='downlaod_iamges'
第三步:
class SoImagesItem(scrapy.Item):
# define the fields for your item here like:
image_urls = scrapy.Field()
pass
第四步:
spiders.py中编写
# -*- coding: utf-8 -*-
import scrapy
import json
from so_images.items import SoImagesItem
class ImagesSpider(scrapy.Spider):
BASE_URL = 'http://image.so.com/zj?ch=art&sn=%s&listtype=new&temp=1'
name = 'images'
start_index = 0
allowed_domains = ['image.so.com']
start_urls = ['http://image.so.com/zj?ch=art&sn=0&listtype=new&temp=1']
MAX_DOWNLOAD_NUM = 1000
def parse(self, response):
infos = json.loads(response.body.decode('utf-8'))
# images = SoImagesItem()
images_list = []
# images['image_urls'] =
yield {'image_urls':[info['qhimg_url']for info in infos['list']]}
self.start_index += infos['count']
if infos['count'] > 0 and self.start_index < self.MAX_DOWNLOAD_NUM:
yield scrapy.Request(self.BASE_URL%self.start_index)
第五步:

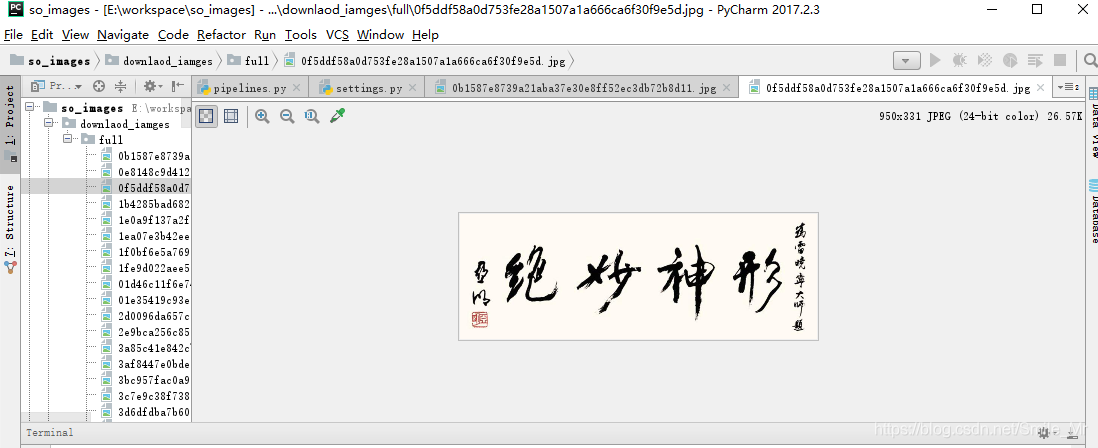
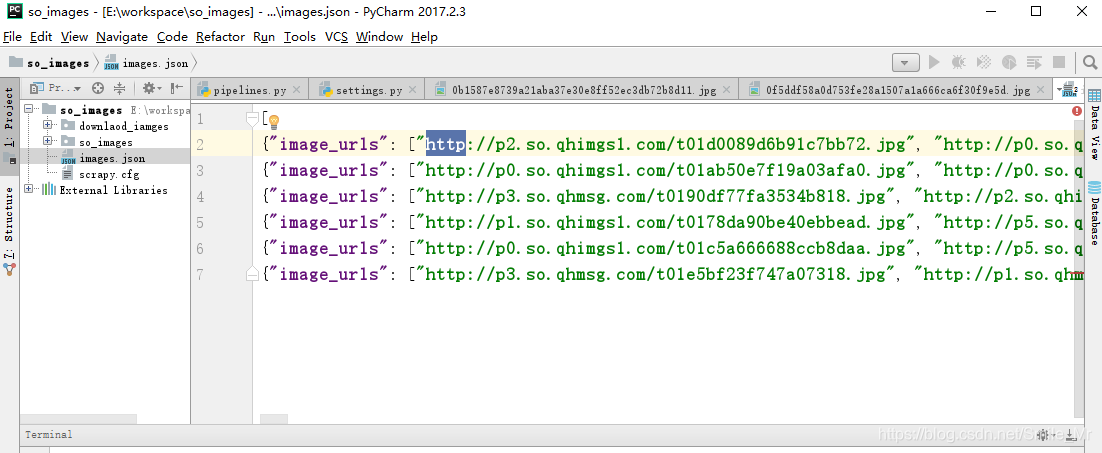
实战:爬取腾讯招聘网站
得到url:URL= https://hr.tencent.com/position.php?&start=10
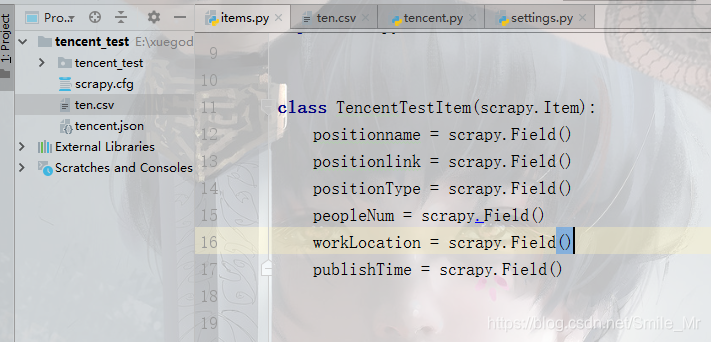
编写item
class TencentTestItem(scrapy.Item):
positionname = scrapy.Field()
positionlink = scrapy.Field()
positionType = scrapy.Field()
peopleNum = scrapy.Field()
workLocation = scrapy.Field()
publishTime = scrapy.Field()
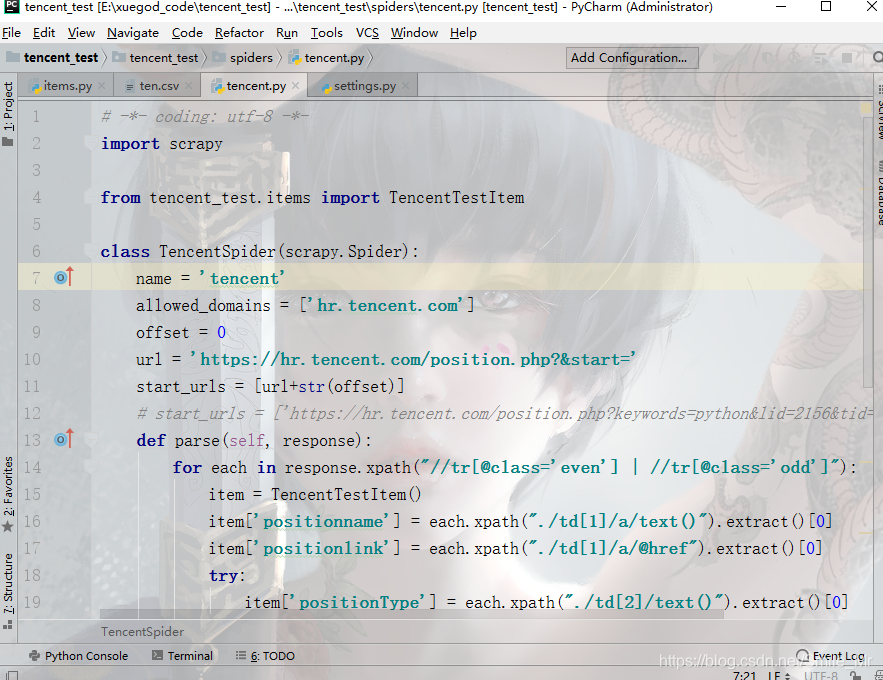
编写tencent
# -*- coding: utf-8 -*-
import scrapy
from tencent_test.items import TencentTestItem
class TencentSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['hr.tencent.com']
offset = 0
url = 'https://hr.tencent.com/position.php?&start='
start_urls = [url+str(offset)]
# start_urls = ['https://hr.tencent.com/position.php?keywords=python&lid=2156&tid=0&start=\d+']
def parse(self, response):
for each in response.xpath("//tr[@class='even'] | //tr[@class='odd']"):
item = TencentTestItem()
item['positionname'] = each.xpath("./td[1]/a/text()").extract()[0]
item['positionlink'] = each.xpath("./td[1]/a/@href").extract()[0]
try:
item['positionType'] = each.xpath("./td[2]/text()").extract()[0]
except IndexError:
pass
item['peopleNum'] = each.xpath("./td[3]/text()").extract()[0]
item['workLocation'] = each.xpath("./td[4]/text()").extract()[0]
item['publishTime'] = each.xpath("./td[5]/text()").extract()[0]
# 将数据交给pipeline
yield item
if self.offset < 1000:
self.offset += 10
yield scrapy.Request(self.url+str(self.offset),callback=self.parse)
编写settings.py
ROBOTSTXT_OBEY = False


下载延迟

然后项目运行 :

