串匹配问题
给定两个字符串S和T,在主串S中查找子串T的过程称之为串匹配(模式匹配),T称之为模式。这样一类的问题在实践中应用非常广泛。在文本处理系统、操作系统、编译系统、数据库系统以及Internet信息检索系统中,串匹配都是使用最频繁的操作。
一般来说,串匹配问题具有以下的特征:
- 问题输入规模很大,常常要在大量信息中进行匹配。因此,算法执行依次的时间也不可忽视
- 匹配操作经常被调用,执行频率很高,因此,算法改进的累积效益往往比表面看起来要高
解决串匹配问题可以使用蛮力法或者KMP模式匹配。
首先介绍一下BF算法(朴素的模式匹配算法):
从主串的S的第一个字符开始和模式T的第一个字符进行比较,若相等,则继续比较二者的后序字符;若不相等,则从主串S的第二个字符开始和模式T的第一个字符进行比较,重复上述过程,若T中的字符全部比较完毕,则说明本趟匹配成功;若S中的字符全部比较完毕,则匹配失败。这个算法称之为BF算法。

BF算法的基本思想如上图。
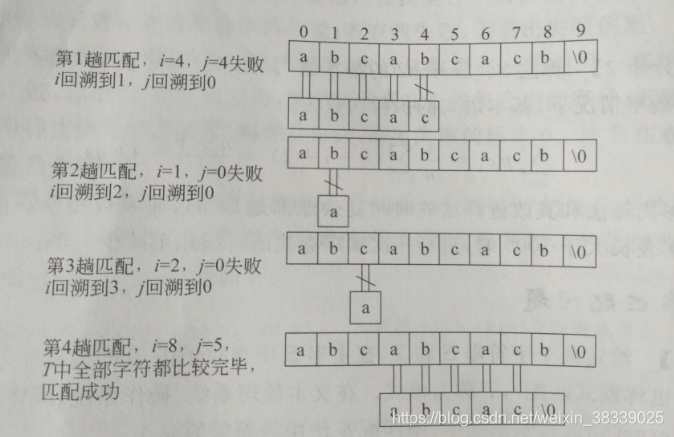
设有主串S=“abcabcacb”,模式T=“abcac”,则其匹配执行过程如下:
上述BF算法可描述为以下伪代码:
输入:主串S,模式T
输出:T在S中的位置
1. 初始化主串开始比较位置index=0
2. 在串S和串T中设置比较的起始下标i=0,j=0
3. 重复以下操作:直到其中一个串比较完毕
if S[i]==T[j]
i++;j++
else
index++;
i=index;j=0
4. 如果T中所有字符均比较完毕,则返回匹配的开始位置,否则返回0
其算法用C++语言描述如下:
int BF(char S[],char T[]){
int index=0; //主串从下标0开始第一趟匹配
int i=0,j=0; //设置比较的起始下标
while((S[i]!='\0')&&(T[j]!='\0')){
if(S[i]==T[j]){
i++;j++
}else{
index++;
i=index;j=0;
}
}
对BF算法分析:
BF算法在某趟匹配失败后,对于主串S要回溯到本趟匹配开始字符的下一个字符,模式T要回溯到第一个字符,这就造成了BF算法的效率低下,而这些显然是不必要的:
- 观察上图匹配过程,在第一趟匹配过程中,S[0]~S[3] 和T[0] ~ T[3]匹配成功 ,S[4]!=T[4]匹配失败,因此有了第二趟。因为第一趟中有S[1]=T[1],而T[0]!=T[1],故T[0]!=S[1],所以第二趟是不必要的,同理,第三趟也是不必要的,可以直接到第四趟。进一步分析第四趟中的第一对字符S[3]和T[0]的比较是多余的,因为第一趟中已经比较了S[3]和T[3],并且S[3]=T[3],而T[0]=T[3],因此必有是S[3]=T[0],因此第四趟比较可以从第二对字符S[4]和T[1]开始进行,也就是说,第一趟匹配失败后,下标i不回溯,而是将下标j回溯至第二个字符,从T[1]和S[4]开始进行比较.
而关键的问题在于S[i]和T[j]匹配失败后,下标i不回溯,下标j回溯至某个位置k,从T[k]和S[i]开始比较。这个其中的k是如何确定的?
下面我们观察部分匹配成功时的特征,某趟在S[i]和T[j]匹配失败后,下一趟比较从S[i]和T[k]开始,则有T[0]~T[k-1] =S[i-k] ~S[i-1]成立,如下图a所示;在部分匹配成功时,有T[j-k] ~T[j-1]=S[i-k] ~S[i-1]成立。如图b所示。
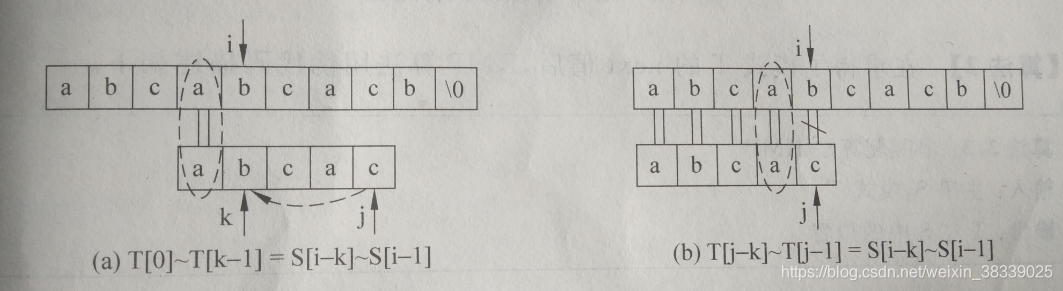
所以可得:T[0]~T[k-1]= T[j-k] ~T[j-1]。
这说明:模式中每个字符都对应一个k值,而且该k值仅依赖于模式本身,于主串无关。
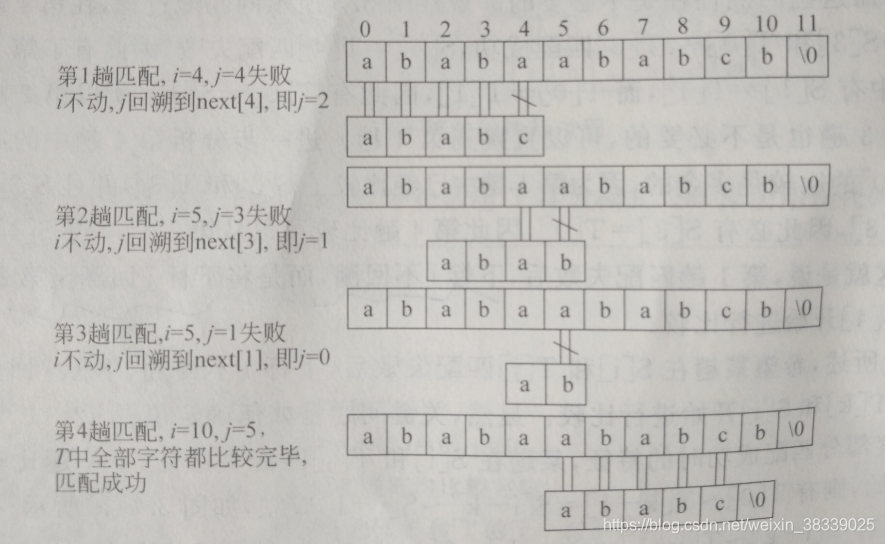
例如主串S=“ababaababcb”,模式T=“ababc”,其模式T的next值为{-1,0,0,1,2}。而其对应的KMP(改进的串匹配)算法过程如下:
该KMP算法匹配的伪代码如下:
输入:主串S,模式T
输出:T在S中的位置
1. 初始化主串开始比较位置index=0
2. 在串S和串T中设置比较的起始下标i=0,j=0
3. 重复以下操作:直到其中一个串比较完毕
if S[i]==T[j]
i++;j++
else
j=next[j] //将下标j回溯到next[j]的位置
if j=-1
i++;j++ 准备下一趟比较
4. 如果T中所有字符均比较完毕,则返回匹配的开始位置,否则返回0
KMP算法的C++代码实现:
/**
在求得模式T的next值后,KMP算法只需将主串扫描一遍。所以其时间复杂度为O(n).
**/
void getNext(char T[],char S[]){
int len=-1,i,j;
next[0]=-1;
for(j=1;T[j]!='\0';j++){ //依次求next[j]
for(len=j-1;len>=1;len--){ //相等子串的最大长度为j-1
for(int i=0;i<len;i++) //依次比较T[0]~T[len-1]与T[j-len]~T[j-1]
if(T[i]!=T[j-len+i])break;
if(i==len){
next[j]=len;break;
}
}
if(len<1)next[j]=0; //其他情况,无子串相等
}
}
int KMP(char S[],char T[]){
int i=0,j=0;
int next[80]; //假定模式最长为80个字符
GetNext(T,next);
while(S[i]!='\0'&&T[j]!='\0'){
if(S[i]==T[j]){
i++;j++;
}
else{
j=next[j];
if(j==-1){i++;j++}
}
}
if(T[j]=='\0') return (i-strlen(T)+1); //返回本趟匹配的开始位置
else return 0;
}