《Subgradients》
Subderivate-wiki
Subgradient method-wiki
《Subgradient method》
Subgradient-Prof.S.Boyd,EE364b,StanfordUniversity
《Characterization of the Subdifferential of Some Matrix Norms 》
这篇文章主要参考:
《Characterization of the Subdifferential of Some Matrix Norms 》
引
矩阵
A∈Rm×n,
∥⋅∥为矩阵范数,注意这里我们并没有限定为何种范数。那么
∥A∥的次梯度可以用下式表示:
∂∥A∥={G∈Rm×n∣∥B∥>∥A∥+trace[(B−A)TG],allB∈Rm×n}
这个定义和之前提到的定义是相一致的,事实上,
trace(ATB)就相当于将
A和
B拉成俩个长向量作内积,比较实质就是对应元素相乘再相加。
G∈∂∥A∥等价于:

在我看的书里面,对偶范数一般用
∥⋅∥∗表示,且是如此定义的:
∥z∥∗=sup{zTx∣∥x∥≤1}
因为下面还有很多地方是采取截图的形式展示的,所以还是沿袭论文的符号比较好,这里只是简单提一下。
至于为什么等价,论文里面没有提,我只能证明,满足那俩点条件的
G是
∥A∥的次梯度,而不能证明所有次梯度都满足那俩个条件。
证明如下:
假设
G满足上面的条件,那么:
trace[(B−A)TG]=−∥A∥+trace(BTG)⇒∥A∥+trace[(B−A)TG]=trace(BTG)
又
trace(∥B∥BTG)≤1=∥B∥∥B∥
所以
∥B∥≥∥A∥+trace[(B−A)TG]
所以
G∈∂∥A∥’
不好意思,我想到怎么证明啦!下证,
G∈∂∥A∥必定满足上述的条件,我们先说明范数的一些性质:
齐次:
∥tA∥=∣t∣∥A∥
三角不等式:
∥A+B∥≤∥A∥+∥B∥
既然对所有
B∈Rm×n成立:
∥B∥≥∥A∥+trace[(B−A)TG]
令
B=1/2A,可得:
trace(ATG)≥∥A∥
又
∥A+B∥≤∥A∥+∥B∥≤∥A+B∥−trace[BTG]+∥B∥⇒trace(BTG)≤∥B∥
所以:
∥A∥≤trace(ATG)≤∥A∥⇒trace(ATG)=∥A∥
到此第一个条件得证。
又:
trace(BTG)≤∥B∥⇒trace(∥B∥BTG)=∥G∥∗≤1
第二个条件也得证。漂亮!
正交不变范数
正交不变范数定义如下:
∥UAV∥=∥A∥
其中
U,V为任意正交矩阵(原文是
∥UVA∥=∥A∥,我认为是作者的笔误)。
注意,如果范数
∥⋅∥是正交不变的,那么其对偶范数同样是正交不变的,证明如下:
既然:
∥Z∥∗=sup{trace(ZTX)∣∥X∥≤1}
∥UZV∥∗=sup{trace(VTZTUTX)∣∥X∥≤1}
令
UXV替代
X代入即可得:
∥UZV∥∗=sup{trace(VTZTUTX)∣∥X∥≤1}=sup{trace(VTZTUTUXV)∣∥UXV∥≤1}=sup{trace(ZTX)∣∥X∥≤1}=∥Z∥∗
最后第二个等式成立根据迹的性质和
∥⋅∥的题设。
我们假设矩阵
A的SVD分解为:
A=UΣVT
其中
Σ∈Rm×n为对角矩阵(那种歪歪的对角矩阵),
U和
V的列我们用
ui,vi来表示。
假设其奇异值:
σ1≤σ2≤…≤σn
降序排列。
所有这样的(正交不变?)范数都能用下式来定义:
∥A∥=ϕ(σ)
其中
σ=(σ1,…,σn)T,
ϕ是一个对称规范函数(symmetirc gague function),满足:

上面这个东西我也证明不了,不过至少谱范数和核函数的确是这样的。
ϕ的对偶可以用下式来表示:
ϕ∗=ϕ(y)=1maxxTy
而且其次梯度更矩阵范数又有相似的一个性质:

证明是类似的,不多赘述。
一种常见的正交不变范数可由下式定义:
∥A∥=∥σ∥p
比较经典的,
p=1对应核范数,
p=2对应F范数,
p=∞对应谱范数。
定理1

证明如下:
这一部分的证明需要注意,不要把
A当成题目中的
A,当成
A+rR可能更容易理解。

这部分的证明,主要是得出了
σi(γ)的一个泰勒展开,要想证明这个式子成立,可以利用上面的公式,也可以这么想。
σi(γ)是
A+γR的第
i个奇异值:
γ→0+limγσi(γ)−σi=γ→0+limγσi(A+γR)−σi=γ→0+limγui(γ)T(A+γR)vi(γ)−σi
即为:
γ→0+limγui(γ)TAvi(γ)−σi+uiTRvi
所以左边这项等于0?

下面的证明中,第一个不等式成立的原因是:
ϕ(σ)≥ϕ(σ(γ))+(σ−σ(γ))Td(γ)
又
σ(γ)Td(r)=ϕ(σ(r))

类似地,我们就可以得到下面的分析:

有一点点小问题是,没有体现出
max的,不过从(2.5)看,因为这个不等式是对所有
d∈∂ϕ(σ)都成立的,所以结果成立。怎么说呢,这个有点像是上确界的东西。
我们定义符号
conv{⋅},表示集合的凸包。
定理2
注意,我们的最终目的是找到
∂∥A∥利用前面的铺垫我们可以得到定理2:
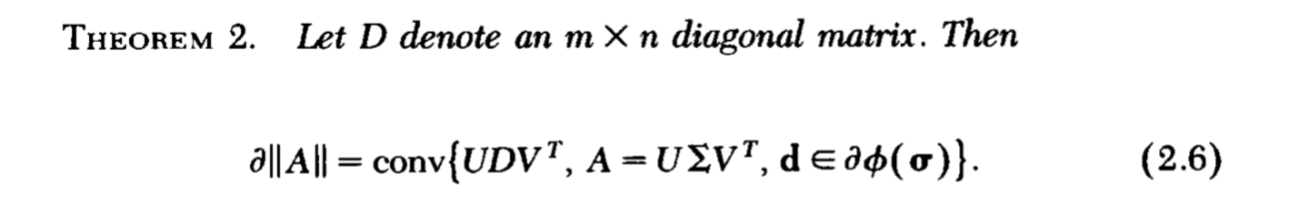
相当有趣的一个东西。
下面是证明:
证明总的是分俩大部分来证明的,首先得证明
G∈conv{S(A)}满足上面的俩个条件,即是次梯度,再证明,不存在一个次梯度不属于
conv{S(A)}。
其实下面这部分的证明,我觉得用
A=UiΣiViT表示比较好,作者的意思应该是奇异值分解可以用不同的序,毕竟我们不能要求凸包中的元素有合适的序。

下面这部分的证明,感觉没什么好讲的。

下面这部分证明,打问号的地方我有疑惑,以为我觉得只能知道
ϕ∗(di)≤1,而且在这个条件下,证明依旧。好吧,我明白了,因为:
ϕ∗(di)=ϕ(x)=1maxdiTx,又
di∈ϕ(σ),所以只需令
x=σ/∣ϕ(σ)即可得
ϕ∗(di)=1。

到此,俩个条件满足,第一部分证毕。
第二部分用到了一个理论,我没有去查阅。这部分证明的思想是,即便存在这么一个
G不属于
convS(A),
G依旧得满足
trace(RTG)≤d∈∂ϕ(σ)maxt=1∑ndiuiTRvi(要知道,后面这个部分是类似右导数的存在!!!),这个的原理是一种极限的思想,不好表述,但是真的真的蛮容易证明的。

例子:谱范数


凸包,凸包,切记切记。
例子:核范数

上面倒数第二行那个式子成立,要注意
∑iλi=1这个条件。

注意:这里出现
Y,Z的原因是
U(2),V(2)对应的奇异值为0,所以其顺序是任意的,并没有对应一说。
算子范数
让
∥⋅∥A和
∥⋅∥B分别表示定义在
Rm和
Rn上的范数,那么对于矩阵
A∈Rm×n上的算子范数,可以如下定义:
∥A∥=∥x∥B=1max∥Ax∥A
注意,矩阵范数,向量范数都满足引里的那个等价条件(实际上,只需满足正定性和三角不等式即可,就能推出那个等价条件)。
定义
Φ(A):
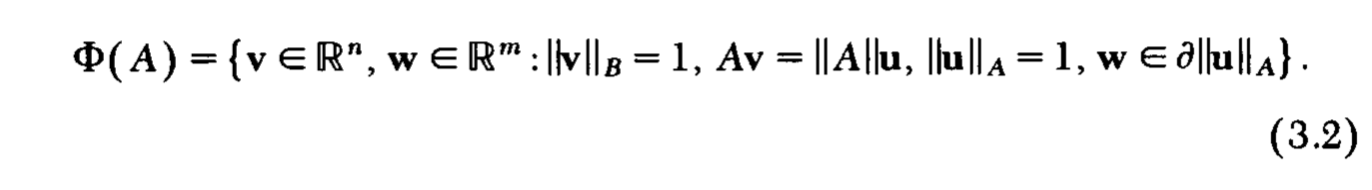
定理3
类似的,我们有定理3:

这部分的推导是类似的:


下面这部分和之前的是不同的,这么大费周章,就是为了证明最后收敛的结果在
Φ(A)中,之间没有这部分的证明,是因为凸函数次梯度的集合是闭凸的?


定理4
这个定理,就是为了导出
∥A∥的次梯度。

这部分首先利用迹的性质,再利用
Avi=∥A∥ui

wiTRvi≤∥R∥的原因是
∥wi∥A∗≤1,
又
∥R∥∥Rvi∥A=∥v∥_B=1max∥Rv∥A∥Rvi∥A≤1(至少
∥Rvi∥A=1),所以有上面的结果。

到此,我们证明了,
S(A)中的元素均为次梯度,下证凡是次梯度,必属于
S(A)。
这部分证明没有需要特别说明的。

例子
ℓ2
