第五章
一切为了数据挖掘的准备
5.决策树(decision tree)
- 决策树是一种基本的分类与回归方法,本章只涉及分类问题
- 通常有三个步骤:特征选择,决策树生成,决策树修剪
- 决策树的内部结点表示一个特征或属性,叶结点表示一个类
- 决策树可以表示给定特征条件下类的条件概率分布。
5.1特征选择标准
需要选取对训练数据具有分类能力的特征,提高决策树学习效率。选择准则通常是信息增益或信息增益比。
5.1.1 熵
- 熵:对随机变量不确定性的度量。或表示随机变量的混乱、离散程度。
- 表示:设Y是一个取有限个值的离散随机变量,概率分布为
,则随机变量Y熵的定义为:
通常对数以2为底或以e为底,这时熵的单位为比特或纳特。
- 经验熵:由样本集T得到熵的极大似然估计
其中 为Y取值 时的样本数;N为总样本数
- 如果Y为二值变量,
- 当Y为二值变量,Y的取值越确定时,熵 越小。例如p=0,或p=1时H(Y)=0,不确定性为0;当p=0.5时,H(Y)=1,不确定性最大。
5.1.2 条件熵
-
条件熵H(Y|X)在已知随机变量X的条件下,随机变量Y的不确定性。即利用特征X将数据分组,随机变量Y的混乱程度
-
表示:设随机变量X取值范围为 ,随机变量Y的取值范围为 ,条件熵定义为:
-
经验条件熵:由样本集T进行条件熵的极大似然估计
是X取值 时的样本数,N是总样本数, 是X取值 的样本中被分类为 的样本数
5.1.3 信息增益
-
:特征A对训练数据集D的信息增益.表示给定特征A后,将随机变量D的混乱程度降低了多少。
-
表示:定义为集合D的经验熵 与特征A给定条件下D的经验条件熵之差
-
信息增益大的特征具有更强的分类性
5.1.4信息增益比
- :特征A对训练数据集D的信息增益比
- 表示:
5.2决策树生成算法
决策树生成算法递归产生决策树,往往对训练数据集的分类准确,但泛化能力不强,容易过拟合。需要根据损失函数最小化进行剪枝,避免过拟合
5.2.1 ID3决策树生成算法
输入:训练数据集D,特征集A,阈值 ,输出:决策树
- 1.如果D中所有实例属于同一类 ,则T为单结点树,并将类 作为该点的类标记,返回T
- 2.如果特征集A为空,T为单结点树,把D中实例数最大的类 作为该点的类标记,返回T
- 4.否则计算A中各特征对D的信息增益,选择信息增益最大的特征
- 5.如果 对应的最大的信息增益小于阈值 ,T为单结点树,把D中实例数最大的类 作为该点的类标记,返回T(代表没有明显的特征可以将数据集分类)
- 6.否则将数据集D按照特征 分割成若干个子集,将子集中中实例数最大的类 作为该点的类标记,构建子结点,从而形成根结点及子结点,返回T
- 7.对第i个子结点,对该结点分割的子集,以 为特征集(即还未被用于分类的特征),递归调用1-6步骤,得到子树 ,返回子树
5.2.2C4.5生成算法
用信息增益比代替ID3中的信息增益,选择特征
5.3决策树的剪枝
- 剪枝:将已生成的树进行简化,从已生成的树上裁掉一些子树或叶结点,并将其父结点作为新的叶结点。
5.3.1 损失函数
设数的叶结点个数
,t是叶结点,该叶结点有
个样本点,其中k类的样本点有
个,
是叶结点t上的经验熵,
是参数,损失函数定义为:
- 表示模型复杂度,较大的 促使选择较简单的模型,较小的 促使选择较复杂的模型
- 当 确定时,选择损失函数最小的子树。
5.3.2树的剪枝算法
输入:生成算法产生的整个树T,参数 ;输出:修剪后的子树
- 计算每个结点的经验熵
- 递归的从树的叶结点向上回缩,计算损失函数,若损失函数降低,进行剪枝,将父结点变为新的叶结点。
- 重复上一步骤,直至不能继续,得到损失函数最小的子树
5.4CART算法(对于分类树)
- CART算法假设决策树是二叉树,每个结点特征取值为是/否,左分支为是,右分支为否。哪怕一个特征有3个以上取值,也只分为两部分,分为等于其中一个值、不等于这个值两部分。
5.4.1基尼指数
-
基尼指数,表示集合D的不确定性
-
在特征A条件下,D的基尼指数:表示经A分割后集合D的不确定性
5.4.2CART生成算法
输入:训练数据集D,停止计算的条件(结点中的样本数小于预设阈值,或样本的基尼指数小于预定阈值,或没有更多特征);输出:CART决策树(为二叉决策树)。
- 1.设训练数据集D,计算现有特征对该数据集的基尼指数。对于每个特征 ,对其每个可能的取值 ,计算其基尼指数
- 2.在所有可能的特征及所有可能的切分点中,选择基尼指数最小的特征及切分点,作为最优特征与最优切分点。根据此点(按照 )将数据集切分为两部分,构成两个子结点
- 3.对两个子结点递归调用1,2,但需要在 的特征中,选择所有的切分点进行基尼指数比较,选择基尼指数最小的切分点进行切分,直至满足停止条件。
5.5 几个离散程度指数的区别
方差
对于取值大小有意义的离散变量
熵
对于取值大小无意义的离散变量,计算取值的混乱程度
基尼指数
对于取值大小无意义的离散变量,计算取值的混乱程度
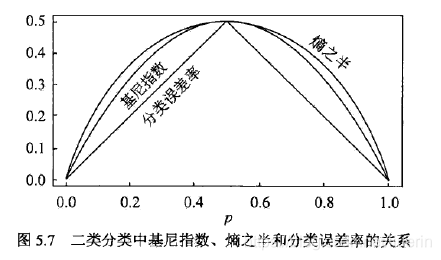
在二分类问题中,基尼指数 和熵之半 和分类误差率的关系。
- 我对分类误差率的理解:假如取值0的概率p=0.3,猜测取值为1,猜错的概率(分类误差率)就是0.3;加入取值0的概率p=0.8,猜测取值为0,猜错的概率就是0.3.
5.6我的实现
import pandas as pd
from pandas import Series,DataFrame
import math
class DecissionTree:
def __init__(self,X,Y,featureclass):
self.data = DataFrame(X,columns = featureclass)
self.data['yvalue'] = Y
self.featureclass = featureclass
self.tree = self.createTree(self.data)
def createTree(self,data):
"""
data的列为X的特征和Y分类构成,最终构成的树为一个字典,字典的外层key是特征class名称,
value也是字典,key是这个特征取值,如果是叶节点,value是分类结果,如果是内部节点,
value仍然是个字典,代表子树
"""
#如果所有的实例同属一类
if data['yvalue'].nunique() == 1:
return data['yvalue'].unique()
#如果特征集为空,即没有特征可以拿来分类,选择样本最多的y值
if len(data.columns) == 1:
return data['yvalue'].value_counts().sort_values(ascending=False).index[0]
# 选择信息增益最大的特征进行分类
bestfeature = self.chooseBestFeature(data)
myTree = {bestfeature:{}}
#按照选择的特征分类后,对分类的数据集递归调用函数
for xvalue in data[bestfeature].unique():
#用剩余未被用于分类的特征数据生成子树
subdata = data.drop([bestfeature],axis=1)
subTree = self.createTree(subdata)
myTree[bestfeature][xvalue] = subTree
return myTree
def predict(self,x):
"""
输入x是一个列表,输出是一个类别
"""
x = Series(x,index = self.featureclass)
myTree = self.tree
while type(myTree).__name__=='dict':
for feature in myTree.keys():
myTree = myTree[feature][x[feature]]
return myTree
def calcEntropy(self,data):
"""
计算数据集的熵,熵 = -sum(plog(p)),输入为DataFrame,输出为float
"""
ydata = data['yvalue'].value_counts()/len(data)
entropy = ydata.apply(lambda x: -x*math.log(x,2)).sum()
return entropy
def chooseBestFeature(self,data):
"""
计算A中各特征对数据的信息增益,选择信息增益最大的特征,
信息增益: -sum plog(p) - sum px sum -pxylog pxy,
"""
bestfeature = ''
maxInfomationGain = 0.0
# 数据集的熵
entropy = self.calcEntropy(data)
#计算每个特征的条件熵
for feature in data.columns[:-1]:
pfeature = data.loc[:,feature].value_counts()/len(data)
conditionalEntropy = 0.0
for xvalue in pfeature.index:
conditionalEntropy += pfeature[xvalue]* self.calcEntropy(data[data.loc[:,feature]==xvalue])
#信息增益
infomationGain = entropy - conditionalEntropy
if maxInfomationGain < infomationGain:
maxInfomationGain = infomationGain
bestfeature = feature
#信息增益最大的特征
return bestfeature
X = [['青年','否','否','一般'],['青年','否','否','好'],['青年','是','否','好'],['青年','是','是','一般'],['青年','否','否','一般']
,['中年','否','否','一般'],['中年','否','否','好'],['中年','是','是','好'],['中年','否','是','非常好'],['中年','否','是','非常好']
,['老年','否','是','非常好'],['老年','否','是','好'],['老年','是','否','好'],['老年','是','否','非常好'],['老年','否','否','一般']]
Y = ['否','否','是','是','否','否','否','是','是','是','是','是','是','是','否']
dt = DecissionTree(X,Y,['年龄','是有工作','是否有房子','信贷情况'])
x=['青年','否','是','一般']
dt.predict(x)