词袋法(Bag of Words)
-
前面只能够使用词袋法对文字进行处理和分析,也就是
from sklearn.feature_extraction.text import CountVectorizer count_vec = CountVectorizer() sentences = [sent1, sent2] # 以上表示两个句子 # 输出特征话向量化后地表示 print(count_vec.fit_transform(sentences).toarray()) # 输出向量各个维度的特征含义 print(count_vec.get_feature_names())
使用NLTK
-
对句子中的词汇形成与性质类属乃至词汇如何组成短语或者句子的规则,做更加细致的分析
import nltk # 对句子进行词汇分割和正则化,有些情况如aren't需要分割为are 和 n't等 tokens_1 = nltk.word_tokenize(sent1) print(tokens_1) tokens_2 = nltk.word_tokenize(sent2) print(tokens_2) # 整理两句的词表,并按照ASCII的排序输出 vocab_1 = sorted(set(tokens_1)) print(vocab_1) vocab_2 = sorted(set(tokens_2)) print(vocab_2) # 初始化stemmer寻找各个词汇最原始的词根 stemmer = nltk.stem.PorterStemmer() stem_1 = [stemmer.stem(t) for t in tokens_1] print(stem_1) stem_2 = [stemmer.stem(t) for t in tokens_2] print(stem_2) # 初始化词性标注器,对每个词汇进行标注 post_tag_1 = nltk.tag.pos_tag(tokens_1) print(post_tag_1) post_tag_2 = nltk.tag.pos_tag(tokens_2) print(post_tag_2)
词向量(Word2Vec)技术
-
词袋法可以视作对文本向量化的表示技术,通过这项技术可以对文本之间在内容的相似性进行一定程度的度量。但是对于相似的两段文本,词袋法并没有计算相似度的方法。
-
因此,为了寻找词汇之间的相似度关系,可以试图将词汇的表示向量化,这样就可以通过计算表示词汇的向量之间的相似度,来度量词汇之间的含义是否相似
-
理论依据(根据Yoshua教授)
-
首先,应该明确,句子中的连续词汇片段,也被称作上下文(Context),词汇之间的联系就是通过无数这样的上下文建立的
-
以一句英文为例:
- 如果是以上下文数量为4的连续词汇片段,那么就有 The cat is walking, cat is walking in, is walking in the 以及 walking in the bedroom。从语言模型的角度来讲,每个连续词汇片段的最后一个单词究竟有可能是什么,都是受到前面3个词汇的制约
-
因此这就形成了一个根据前面3个单词,预测最后一个单词的监督学习系统,从而获得每个词汇独特的向量表示
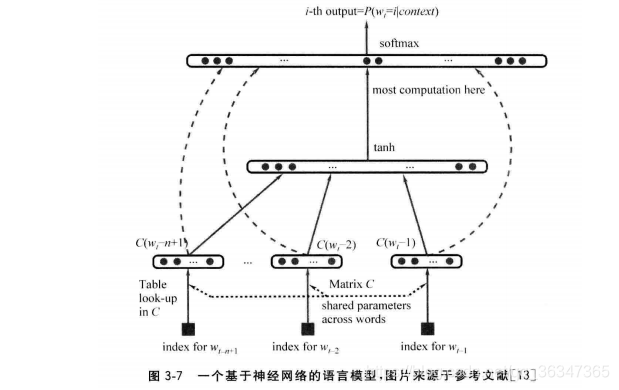
-
-
使用gensim工具包进行词向量训练
# 从sklearn.datasets 导入20类新闻文本抓取器 from sklearn.datasets import fetch_20newsgroups # 通过互联网下载数据 news = fetch_20newsgroups(subset='all') X, y = news.data, news.target # 从bs4 导入BeautifulSoup from bs4 import BeautifulSoup # 导入nltk和re工具包 from nltk, re # 定义一个函数名为news_to_sentences 将每条新闻中的句子逐一剥离出来,并返回一个句子的列表 def news_to_sentences(news): news_text = BeautifulSoup(news).get_text() tokenizer = nltk.data.load('tokenizers/punkt/english.pickle') raw_sentences = tokenizer.tokenize(news_text) sentences = [] for sent in raw_sentences: sentences.append(re.sub('[^a-zA-Z]', ' ', sent.lower(), strip()).split()) return sentences sentences = [] # 将长篇新闻文本中的句子剥离出来用于训练 for x in X: sentences += news_to_sentences(x) # 从gensim.models里导入word2vec from gensim.models import word2vec # 配置词向量的维度 num_features = 300 # 保证被考虑的词汇的频度 min_word_count = 20 # 设定并行化训练使用CPU计算核心的数量,多核可用 num_workers = 2 # 定义训练词向量的上下文窗口大小 context = 5 downsampling = 1e-3 # 训练词向量模型 model = word2vev.Word2Vec(sentences, workers=num_workers, \ size = num_features, min_count = min_word_count, \ window = context, sample = downsampling) # 这个设定代表当前训练好的词向量为最终版,也可以加快模型的训练速度 model.init_sims(replace=True) # 利用训练好的模型,寻找训练文本中与morning最相关的10个词汇 model.most_similar('morning') -
词向量的训练结果很大程度上受所提供的文本影响
XGBoost模型
-
使用XGBoost模型对泰坦尼克号的乘客是否生还的简单预测能力
# 导入pandas用于数据分析 import pandas as pd titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.text') # 选取pcalss、age、sex作为训练特征 X = titanic[['pcalss', 'age', 'sex']] y = titanic['survived'] # 对缺失的age信息采用平均值方法进行补全 X.age.fillna(X.age.mean(), inplace = True) # 对原始数据进行分割,随机采样25%作为测试集 from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state = 33) from sklearn.feature_extraction import DictVectorizer vec = DictVectorizer(sparse=False) # 对源数据进行特征向量化处理 X_train = vec.fit_transform(X_train.to_dict(orient='record')) X_test = vec.transform(X_test.to_dict(orient='record')) # 采用默认配置的XGBoost模型进行预测 from xgboost import XGBClassifier xgbc = XGBClassifier() xgbc.fit(X_train, y_train) print(f'accuarcy is {xgbc.score(X_test, y_test)}') -
一些有用的经验

Tensorflow框架
- Tensorflow内部也有自己定义的常量、变量、数据操作等要素,不同的是,tensorflow使用图来表示计算任务,并使用会话(session)来执行图
- 利用 Tensorflow 搭建一个线性分类器,这与直接使用scikit-learn中已经编写好的LogiticRegression模型不同,Tensorflow允许使用者自由选取不同操作,并组织一个学习系统。
import tensorflow as tf
import numpy as np
import pandas as pd
train = pd.read_csv('../Datasets/Breast-Cancer/breast-cancer-train.csv')
test = pd.read_csv('../Datasets/Breast-Cancer/breast-cancer-test.csv')
# 分割特征与分类目标
X_train = np.float32(train[['Clump Thickness', 'Cell Size']].T)
y_train = np.float32(train['Type'].T)
X_test = np.float32(test[['Clump Thickness', 'Cell Size']].T)
y_test = np.float32(test['Type'].T)
# 定义一个tensorflow的变量b作为线性模型的截距,并设置初始值为1.0
b = tf.Variable(tf.zeros([1]))
# 定义一个tensorflow的变量w作为线性模型的系数,并设置初始值为-1.0到1.0之间均匀分布的随机数
W = tf.Variable(tf.random_uniform([1,2], -1.0, 1.0))
# 显式定义这个线性函数
y = tf.matmul(W, X_train) + b
# 使用tensorflow中的reduce_mean取得训练集上的均方误差
loss = tf.reduce_mean(tf.square(y - y_train))
# 使用梯度下降法估计参数W,b,并且设置迭代步长为0.01, 这个与scikit-learn中的SGBRegressor类似
optimizer = tf.train.GradientDescentOptimizer(0.01)
# 以最小二乘损失为优化目标
train = optimizer.minimize(loss)
# 初始化所有变量
init = tf.initialize_all_variables()
# 开启Tensorflow中的会话
sess = tf.Session()
# 执行变量初始化的操作
sess.run(init)
# 迭代1000轮次,训练参数
for step in xrange(0, 1000):
sess.run(train)
if step % 200 == 0:
print(step, sess.run(W), sess.run(b))
# 准备测试样本
test_negative = test.loc[test['Type'] == 0][['Clump Thickness', 'Cell Size']]
test_positive = test.loc[test['Type'] == 1][['Clump Thickness', 'Cell Size']]
# 以最终更新的参数作图
import matplotlib.pyplot as plt
plt.scatter(test_negative['Clump Thickness'], test_negative['Cell Size'], marker='o', s = 200, c = 'red')
plt.scatter(test_positive['Clump Thickness'], test_positive['Cell Size'], marker='x', s = 150, c = 'black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
lx = np.arrange(0, 12)
# 这里要强调一下,我们以0.5作为分界面,所以计算公式如下
ly = (0.5 - sess.run(b) - lx * sess.run(W)[0][0] / sess.run(W)[0][1])
plt.plot(lx, ly, color='green')
plt.show()
skflow
skflow非常适合于熟悉Scikit-learn编程接口(API)的使用者,而且利用Tensorflow的运算结构和模块封装了许多经典的机器学习模型,如线性回归器、深度全连接的神经网络(DNN)等。考虑到代码编写风格的一致性和可读性,推荐在今后的实践中使用skflow。尽管如此,skflow仍然支持使用Tensorflow的基础算子自定义学习流程,特别是用于搭建神经网络。
- 使用skflow中的深度神经网络(DNN)对“波士顿房价”进行回归预测,并且与集成回归模型进行性能差异的对比。
# 一次性导入sklearn中的多个模块
from sklearn import datasets, metrics, preprocessing, cross_validation
# 使用dataset.load_boston读取美国波士顿的房价数据
boston = datasets.load_boston()
# 获取房屋数据特征以及对应的房价
x, y = boston.data, boston.target
# 分割数据,随机采样25%作为测试样本
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size = 0.25, random_state = 33)
# 对数据特征进行标准化处理
scaler = preprocessing.StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 导入skflow
import skflow
# 使用skflow的LinearRegressor
tf_lr = skflow.TensorFlowLinearRegressor(steps=10000, learning_rate = 0.01, batch_size = 50)
tf_lr.fit(X_train, y_train)
tf_lr_y_predict = tf_lr.predict(X_test)
# 输出skflow中LinearRegressor模型的回归性能
print(metrics.mean_absolute_error(tf_lr_y_predict, y_test))
print(metrics.mean_squared_error(tf_lr_y_predict, y_test))
print(metrics.r2_score(tf_lr_y_predict, y_test))
# 使用skflow的DNNRegressor,并且注意其每个隐含层特征数量的配置
tf_dnn_regressor = skflow.TensorFlowDNNRegressor(hidden_units=[100, 40], steps=10000, learning_rate = 0.01, batch_size = 50)
tf_dnn_regressor.fit(X_train, y_train)
tf_dnn_regressor_y_predict = tf_dnn_regressor.predict(X_test)
# 重复输出
- 越是具备描述复杂数据的强力模型,越容易在训练时陷入过拟合,这一点在配置DNN的层数以及每层特征元的数量时要特别注意