自然语言处理(七)--简单神经网络
1.文本表示
1.1 one-hot编码
什么是one-hot编码?one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图:
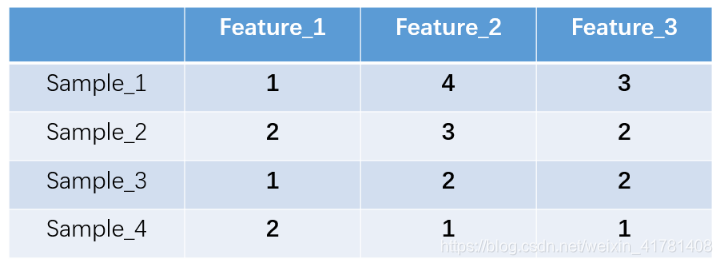
上图中我们已经对每个特征进行了普通的数字编码:我们的feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。那么one-hot编码是怎么搞的呢?我们再拿feature_2来说明:
这里feature_2 有4种取值(状态),我们就用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。

对于2种状态、三种状态、甚至更多状态都是这样表示,所以我们可以得到这些样本特征的新表示:
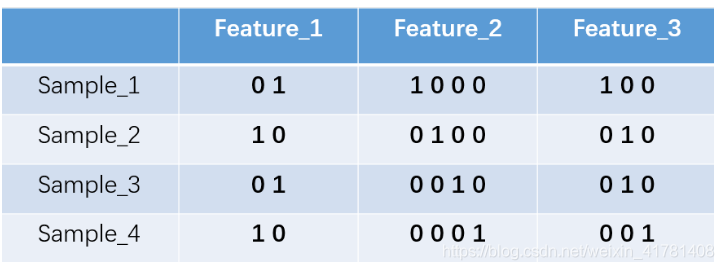
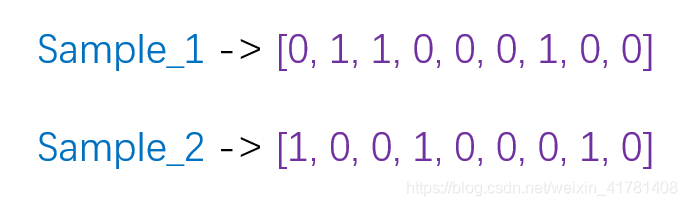
one-hot编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为
one hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
我们首先对预料库分离并获取其中所有的词,然后对每个此进行编号:
1 我; 2 爱; 3 爸爸; 4 妈妈;5 中国
然后使用one hot对每段话提取特征向量:
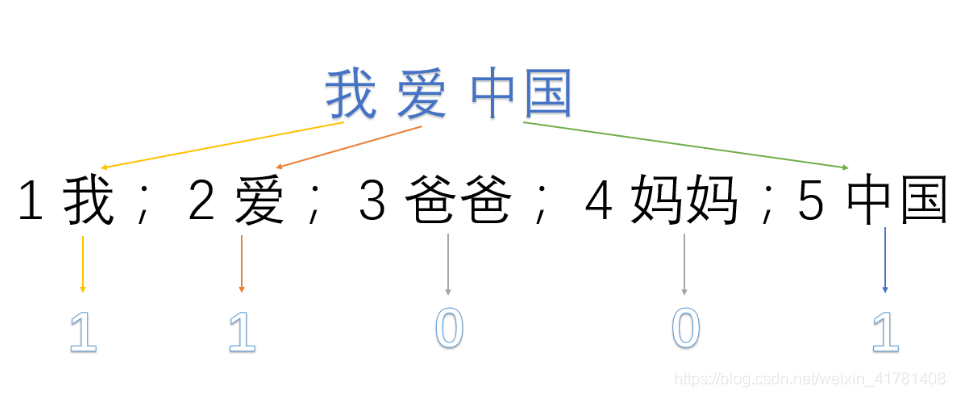
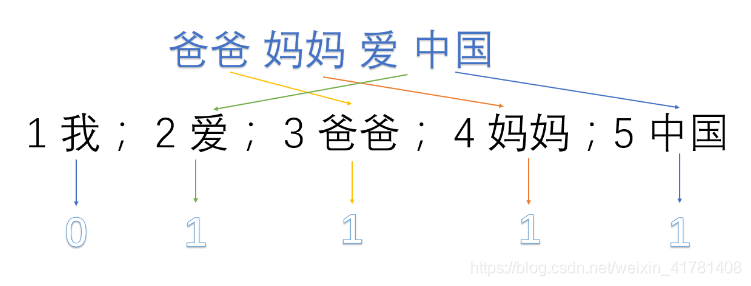
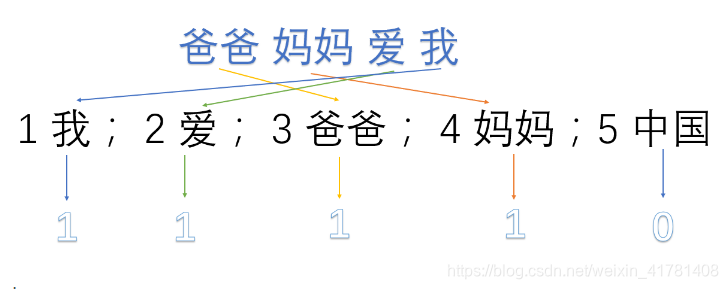
因此我们得到了最终的特征向量为
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 -> 1,1,1,1,0
爸爸妈妈爱中国 -> 0,1,1,1,1
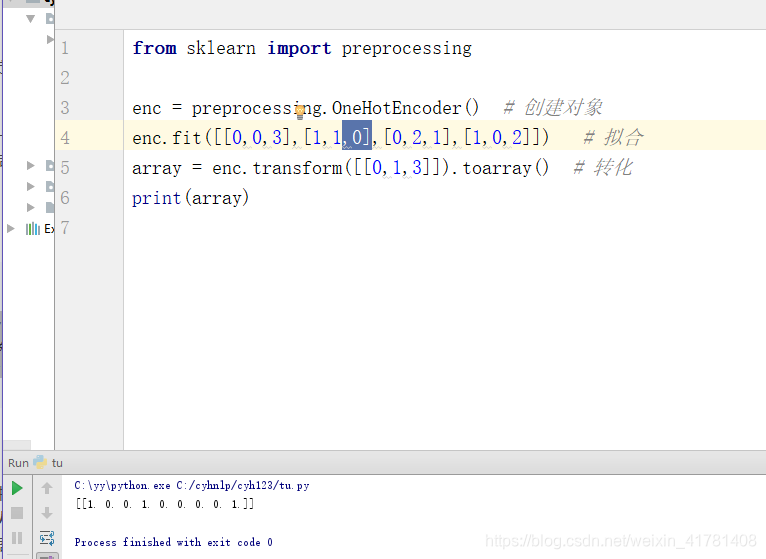
1.1.1sklearn实现one hot encode
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder() # 创建对象
enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]]) # 拟合
array = enc.transform([[0,1,3]]).toarray() # 转化
print(array)
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
1.2 word2vec得到词向量
先有了文本语料库,你需要对语料库进行预处理,这个处理流程与你的语料库种类以及个人目的有关,比如,如果是英文语料库你可能需要大小写转换检查拼写错误等操作,如果是中文日语语料库你需要增加分词处理。这个过程其他的答案已经梳理过了不再赘述。得到你想要的processed corpus之后,将他们的one-hot向量作为word2vec的输入,通过word2vec训练低维词向量(word embedding)
,Word2Vec包含了两种词训练模型:CBOW模型和Skip-gram模型。
CBOW模型根据中心词W(t)周围的词来预测中心词
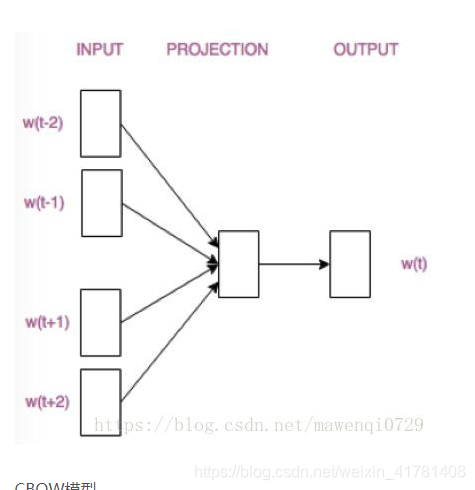
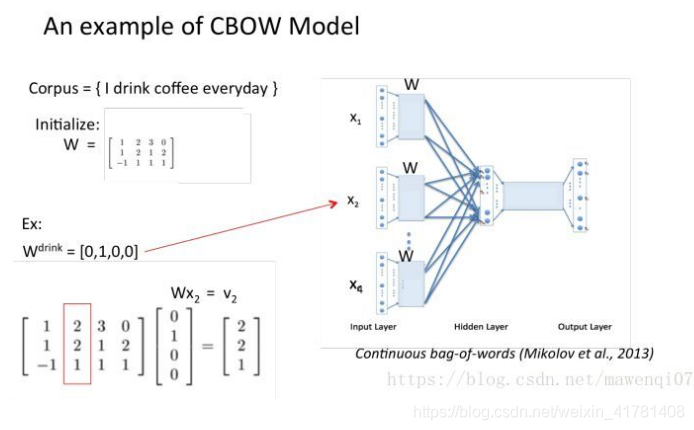
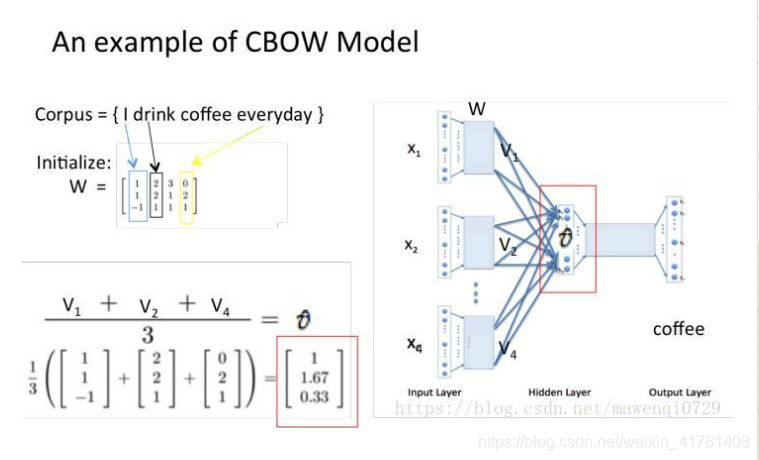
假设我们现在的Corpus是这一个简单的只有四个单词的document: {I drink coffee everyday}
我们选coffee作为中心词,window size设为2
也就是说,我们要根据单词”I”,”drink”和”everyday”来预测一个单词,并且我们希望这个单词是coffee。



Skip-gram模型则根据中心词W(t)来预测周围词
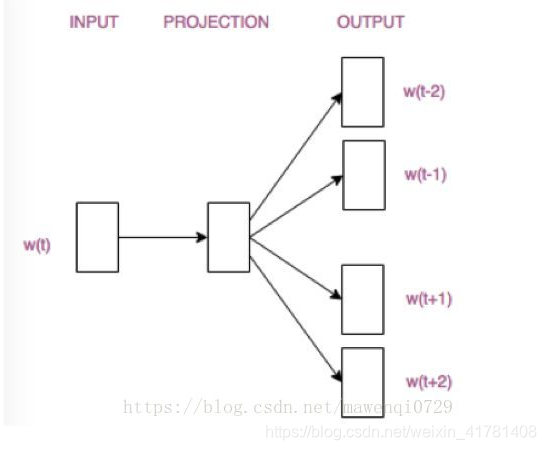
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。还是上面的例子,我们的上下文大小取值为2, 特定的这个词"go"是我们的输入,而这4个上下文词是我们的输出。
这样我们这个Skip-Gram的例子里,我们的输入是特定词, 输出是softmax概率排前4的4个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某1个词对应的最可能的4个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前4的softmax概率对应的神经元所对应的词即可。
1.2 word2vec实践,用来表示文本。
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')
import logging
import os.path
import sys
import multiprocessing
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__=="__main__":
program=os.path.basename(sys.argv[0])
logger=logging.getLogger(program)
logging.basicConfig(format="%(asctime)s:%(levelname)s:%(message)s")
logger.info("running %s "% " ".join(sys.argv))
if len(sys.argv)<4:
print(globals()['__doc__']%local())
sys.exit()
inp,outp1,outp2=sys.argv[1:4]
model=Word2Vec(LineSentence(inp),size=400,window=5,min_count=5,workers=multiprocessing.cpu_count())
model.save(outp1)
model.wv.save_word2vec_format(outp2,binary=False)
# cmd python day3word2vec.py fenci.txt 2800a.model 2800a.vector 命令行中运行
2. FastText
2.1 FastText的原理。
fastText是一种Facebook AI Research在16年开源的一个文本分类器。 其特点就是fast。相对于其它文本分类模型,如SVM,Logistic Regression和neural network等模型,fastText在保持分类效果的同时,大大缩短了训练时间。
fastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征。
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
第一部分:fastText的模型架构类似于CBOW,两种模型都是基于Hierarchical Softmax,都是三层架构:输入层、 隐藏层、输出层。
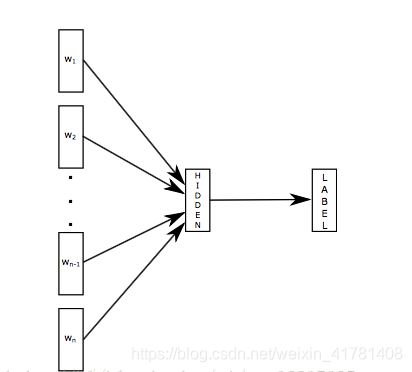
CBOW模型又基于N-gram模型和BOW模型,此模型将W(t−N+1)……W(t−1)W(t−N+1)……W(t−1)作为输入,去预测W(t)
fastText的模型则是将整个文本作为特征去预测文本的类别。
第二部分:层次之间的映射
将输入层中的词和词组构成特征向量,再将特征向量通过线性变换映射到隐藏层,隐藏层通过求解最大似然函数,然后根据每个类别的权重和模型参数构建Huffman树,将Huffman树作为输出。
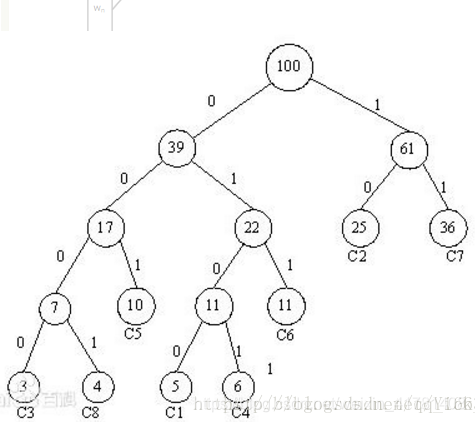
第三部分:fastText的N-gram特征
常用的特征是词袋模型(将输入数据转化为对应的Bow形式)。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。
“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。
如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然,为了提高效率,我们需要过滤掉低频的 N-gram。
在fastText 中一个低维度向量与每个单词都相关。隐藏表征在不同类别所有分类器中进行共享,使得文本信息在不同类别中能够共同使用。这类表征被称为词袋(bag of words)(此处忽视词序)。在 fastText中也使用向量表征单词 n-gram来将局部词序考虑在内,这对很多文本分类问题来说十分重要。
2.2 利用FastText模型进行文本分类
2.2.1fastText有监督学习分类
fastText做文本分类要求文本是如下的存储形式
__label__2 , birchas chaim , yeshiva birchas chaim is a orthodox jewish mesivta high school in lakewood township new jersey . it was founded by rabbi shmuel zalmen stein in 2001 after his father rabbi chaim stein asked him to open a branch of telshe yeshiva in lakewood . as of the 2009-10 school year the school had an enrollment of 76 students and 6 . 6 classroom teachers ( on a fte basis ) for a student–teacher ratio of 11 . 5 1 .
__label__6 , motor torpedo boat pt-41 , motor torpedo boat pt-41 was a pt-20-class motor torpedo boat of the united states navy built by the electric launch company of bayonne new jersey . the boat was laid down as motor boat submarine chaser ptc-21 but was reclassified as pt-41 prior to its launch on 8 july 1941 and was completed on 23 july 1941 .
__label__11 , passiflora picturata , passiflora picturata is a species of passion flower in the passifloraceae family .
__label__13 , naya din nai raat , naya din nai raat is a 1974 bollywood drama film directed by a . bhimsingh . the film is famous as sanjeev kumar reprised the nine-role epic performance by sivaji ganesan in navarathri ( 1964 ) which was also previously reprised by akkineni nageswara rao in navarathri ( telugu 1966 ) . this film had enhanced his status and reputation as an actor in hindi cinema .
其中前面的label是前缀,也可以自己定义,label后接的为类别.
# -*- coding:utf-8 -*-
import pandas as pd
import random
import fasttext
import jieba
from sklearn.model_selection import train_test_split
cate_dic = {'technology': 1, 'car': 2, 'entertainment': 3, 'military': 4, 'sports': 5}
"""
函数说明:加载数据
"""
def loadData():
#利用pandas把数据读进来
df_technology = pd.read_csv("./data/technology_news.csv",encoding ="utf-8")
df_technology=df_technology.dropna() #去空行处理
df_car = pd.read_csv("./data/car_news.csv",encoding ="utf-8")
df_car=df_car.dropna()
df_entertainment = pd.read_csv("./data/entertainment_news.csv",encoding ="utf-8")
df_entertainment=df_entertainment.dropna()
df_military = pd.read_csv("./data/military_news.csv",encoding ="utf-8")
df_military=df_military.dropna()
df_sports = pd.read_csv("./data/sports_news.csv",encoding ="utf-8")
df_sports=df_sports.dropna()
technology=df_technology.content.values.tolist()[1000:21000]
car=df_car.content.values.tolist()[1000:21000]
entertainment=df_entertainment.content.values.tolist()[:20000]
military=df_military.content.values.tolist()[:20000]
sports=df_sports.content.values.tolist()[:20000]
return technology,car,entertainment,military,sports
"""
函数说明:停用词
参数说明:
datapath:停用词路径
返回值:
stopwords:停用词
"""
def getStopWords(datapath):
stopwords=pd.read_csv(datapath,index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8')
stopwords=stopwords["stopword"].values
return stopwords
"""
函数说明:去停用词
参数:
content_line:文本数据
sentences:存储的数据
category:文本类别
"""
def preprocess_text(content_line,sentences,category,stopwords):
for line in content_line:
try:
segs=jieba.lcut(line) #利用结巴分词进行中文分词
segs=filter(lambda x:len(x)>1,segs) #去掉长度小于1的词
segs=filter(lambda x:x not in stopwords,segs) #去掉停用词
sentences.append("__lable__"+str(category)+" , "+" ".join(segs)) #把当前的文本和对应的类别拼接起来,组合成fasttext的文本格式
except Exception as e:
print (line)
continue
"""
函数说明:把处理好的写入到文件中,备用
参数说明:
"""
def writeData(sentences,fileName):
print("writing data to fasttext format...")
out=open(fileName,'w')
for sentence in sentences:
out.write(sentence.encode('utf8')+"\n")
print("done!")
"""
函数说明:数据处理
"""
def preprocessData(stopwords,saveDataFile):
technology,car,entertainment,military,sports=loadData()
#去停用词,生成数据集
sentences=[]
preprocess_text(technology,sentences,cate_dic["technology"],stopwords)
preprocess_text(car,sentences,cate_dic["car"],stopwords)
preprocess_text(entertainment,sentences,cate_dic["entertainment"],stopwords)
preprocess_text(military,sentences,cate_dic["military"],stopwords)
preprocess_text(sports,sentences,cate_dic["sports"],stopwords)
random.shuffle(sentences) #做乱序处理,使得同类别的样本不至于扎堆
writeData(sentences,saveDataFile)
if __name__=="__main__":
stopwordsFile=r"./data/stopwords.txt"
stopwords=getStopWords(stopwordsFile)
saveDataFile=r'train_data.txt'
preprocessData(stopwords,saveDataFile)
#fasttext.supervised():有监督的学习
classifier=fasttext.supervised(saveDataFile,'classifier.model',lable_prefix='__lable__')
result = classifier.test(saveDataFile)
print("P@1:",result.precision) #准确率
print("R@2:",result.recall) #召回率
print("Number of examples:",result.nexamples) #预测错的例子
#实际预测
lable_to_cate={1:'technology'.1:'car',3:'entertainment',4:'military',5:'sports'}
texts=['中新网 日电 2018 预赛 亚洲区 强赛 中国队 韩国队 较量 比赛 上半场 分钟 主场 作战 中国队 率先 打破 场上 僵局 利用 角球 机会 大宝 前点 攻门 得手 中国队 领先']
lables=classifier.predict(texts)
print(lables)
print(lable_to_cate[int(lables[0][0])])
#还可以得到类别+概率
lables=classifier.predict_proba(texts)
print(lables)
#还可以得到前k个类别
lables=classifier.predict(texts,k=3)
print(lables)
#还可以得到前k个类别+概率
lables=classifier.predict_proba(texts,k=3)
print(lables)
fastText有监督学习分类
# -*- coding:utf-8 -*-
import pandas as pd
import random
import fasttext
import jieba
from sklearn.model_selection import train_test_split
cate_dic = {'technology': 1, 'car': 2, 'entertainment': 3, 'military': 4, 'sports': 5}
"""
函数说明:加载数据
"""
def loadData():
#利用pandas把数据读进来
df_technology = pd.read_csv("./data/technology_news.csv",encoding ="utf-8")
df_technology=df_technology.dropna() #去空行处理
df_car = pd.read_csv("./data/car_news.csv",encoding ="utf-8")
df_car=df_car.dropna()
df_entertainment = pd.read_csv("./data/entertainment_news.csv",encoding ="utf-8")
df_entertainment=df_entertainment.dropna()
df_military = pd.read_csv("./data/military_news.csv",encoding ="utf-8")
df_military=df_military.dropna()
df_sports = pd.read_csv("./data/sports_news.csv",encoding ="utf-8")
df_sports=df_sports.dropna()
technology=df_technology.content.values.tolist()[1000:21000]
car=df_car.content.values.tolist()[1000:21000]
entertainment=df_entertainment.content.values.tolist()[:20000]
military=df_military.content.values.tolist()[:20000]
sports=df_sports.content.values.tolist()[:20000]
return technology,car,entertainment,military,sports
"""
函数说明:停用词
参数说明:
datapath:停用词路径
返回值:
stopwords:停用词
"""
def getStopWords(datapath):
stopwords=pd.read_csv(datapath,index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8')
stopwords=stopwords["stopword"].values
return stopwords
"""
函数说明:去停用词
参数:
content_line:文本数据
sentences:存储的数据
category:文本类别
"""
def preprocess_text(content_line,sentences,stopwords):
for line in content_line:
try:
segs=jieba.lcut(line) #利用结巴分词进行中文分词
segs=filter(lambda x:len(x)>1,segs) #去掉长度小于1的词
segs=filter(lambda x:x not in stopwords,segs) #去掉停用词
sentences.append(" ".join(segs))
except Exception as e:
print (line)
continue
"""
函数说明:把处理好的写入到文件中,备用
参数说明:
"""
def writeData(sentences,fileName):
print("writing data to fasttext format...")
out=open(fileName,'w')
for sentence in sentences:
out.write(sentence.encode('utf8')+"\n")
print("done!")
"""
函数说明:数据处理
"""
def preprocessData(stopwords,saveDataFile):
technology,car,entertainment,military,sports=loadData()
#去停用词,生成数据集
sentences=[]
preprocess_text(technology,sentences,stopwords)
preprocess_text(car,sentences,stopwords)
preprocess_text(entertainment,sentences,stopwords)
preprocess_text(military,sentences,stopwords)
preprocess_text(sports,sentences,stopwords)
random.shuffle(sentences) #做乱序处理,使得同类别的样本不至于扎堆
writeData(sentences,saveDataFile)
if __name__=="__main__":
stopwordsFile=r"./data/stopwords.txt"
stopwords=getStopWords(stopwordsFile)
saveDataFile=r'unsupervised_train_data.txt'
preprocessData(stopwords,saveDataFile)
#fasttext.load_model:不管是有监督还是无监督的,都是载入一个模型
#fasttext.skipgram(),fasttext.cbow()都是无监督的,用来训练词向量的
model=fasttext.skipgram('unsupervised_train_data.txt','model')
print(model.words) #打印词向量
#cbow model
model=fasttext.cbow('unsupervised_train_data.txt','model')
print(model.words) #打印词向量
参考
1.https://blog.csdn.net/qq_16633405/article/details/8057843
2.https://blog.csdn.net/john_bh/article/details/79268850