1. RNN。
1.1RNN
循环神经网络,Recurrent Neural Network。神经网络是一种节点定向连接成环的人工神经网络。这种网络的内部状态可以展示动态时序行为。不同于前馈神经网络的是,RNN可以利用它内部的记忆来处理任意时序的输入序列,这让它可以更容易处理如不分段的手写识别、语音识别等。
参考:https://www.atyun.com/30234.html
RNN的工作原理是:第一个词被转换成机器可读的向量。然后RNN逐个处理向量序列。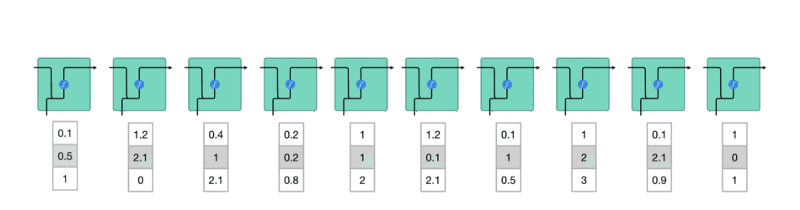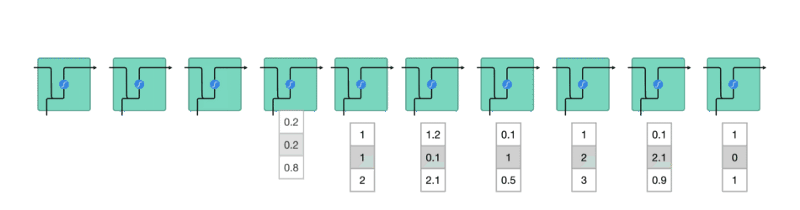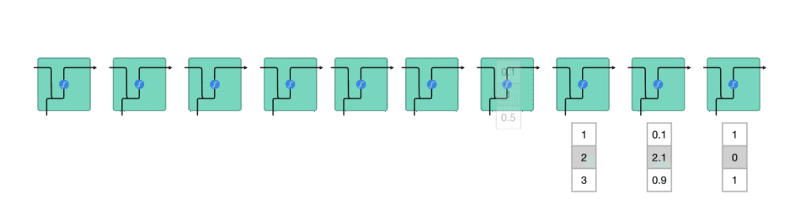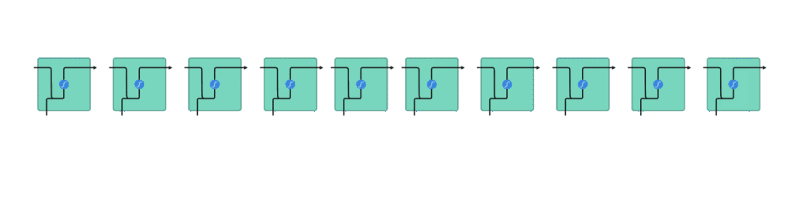
处理时,它将先前的隐藏状态传递给序列的下一步。隐藏状态充当神经网络的记忆。它保存着网络以前见过的数据信息
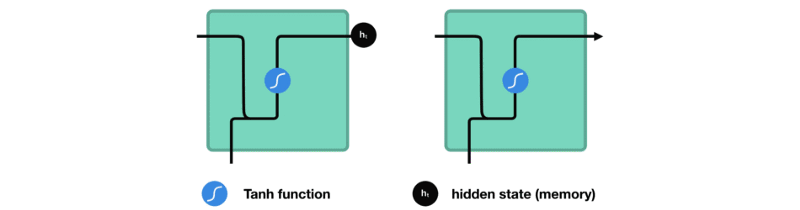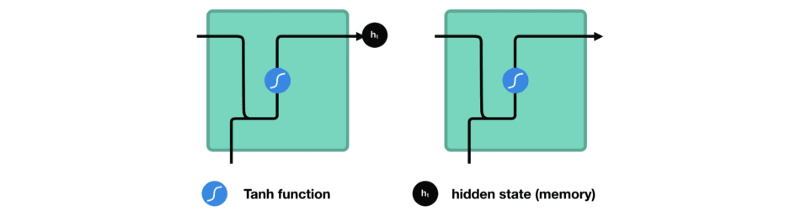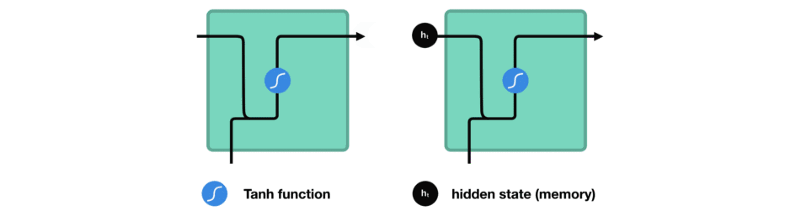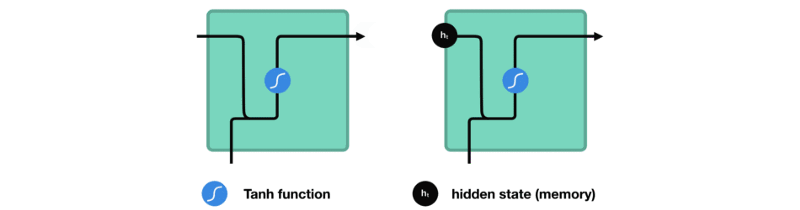
让我们观察RNN的一个单元格,看看如何计算隐藏状态。首先,将输入和先前隐藏状态组合成一个向量。这个向量现在含有当前输入和先前输入的信息。向量经过tanh激活,输出新的隐藏状态,或网络的记忆。
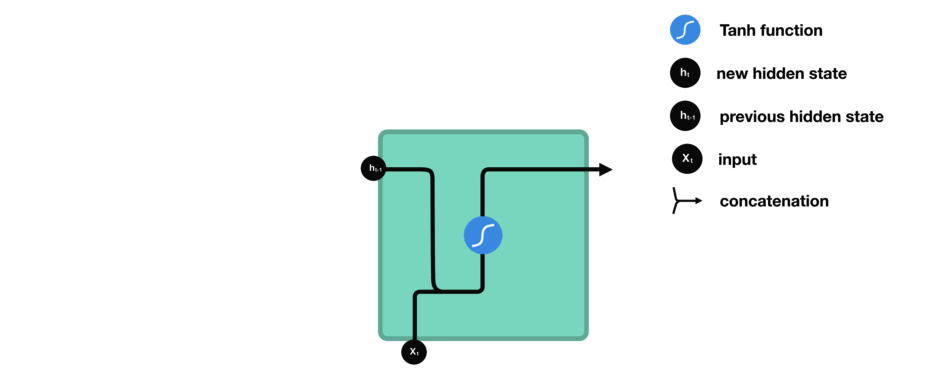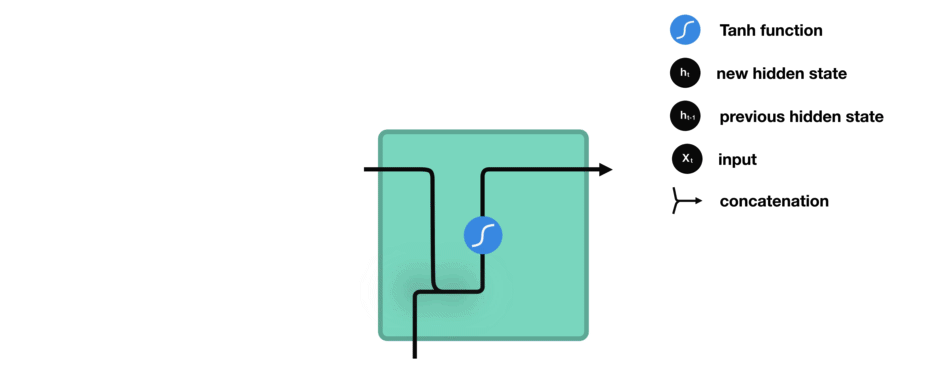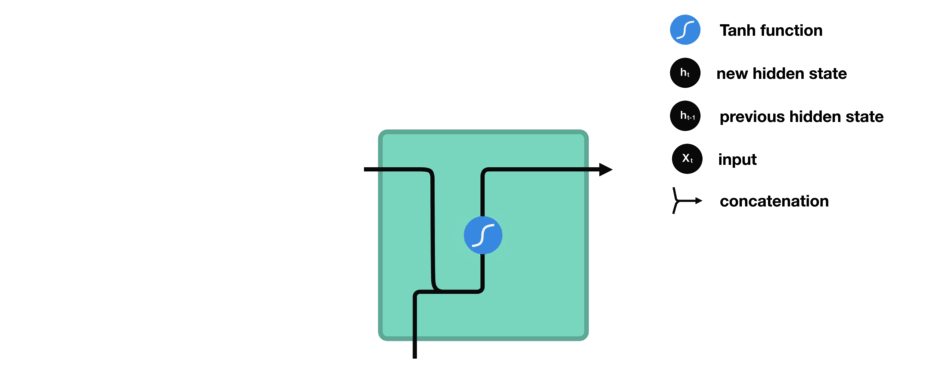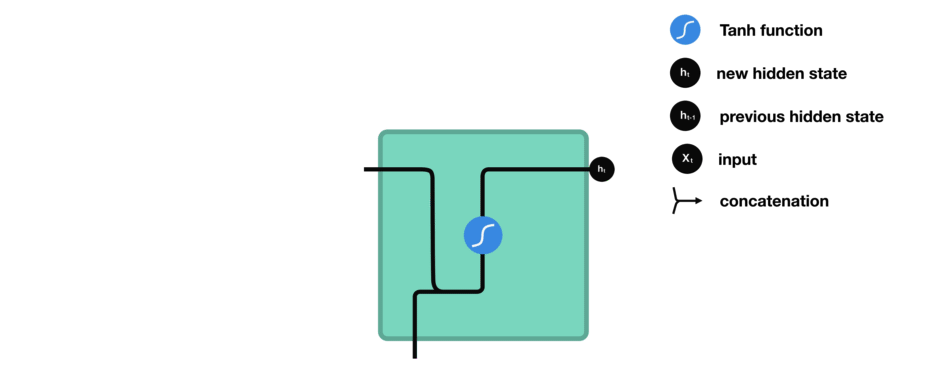
TANH激活
tanh激活用于帮助调节流经网络的值。tanh函数将值压缩在-1和1之间。
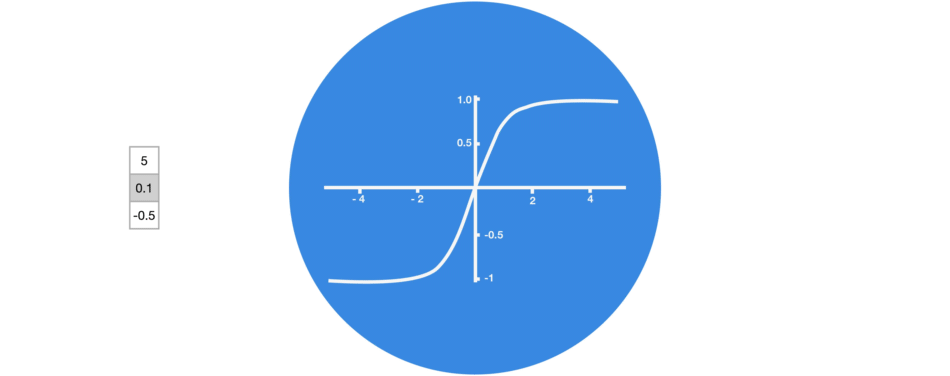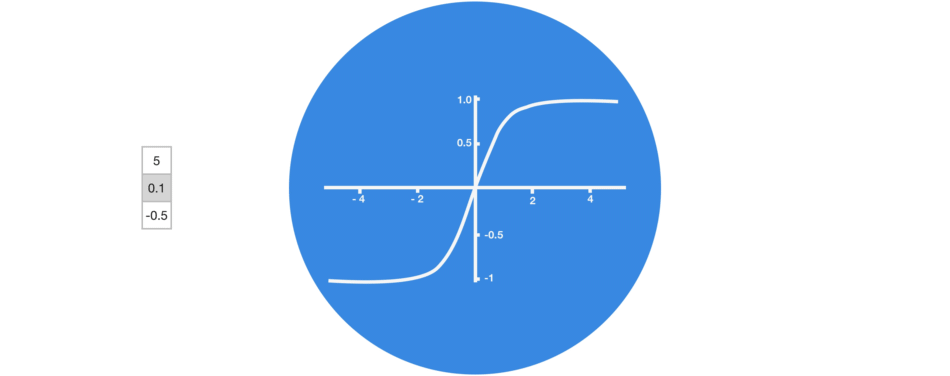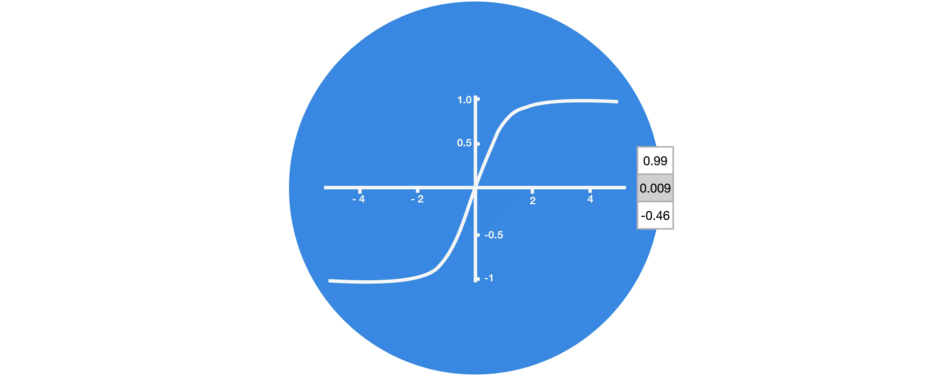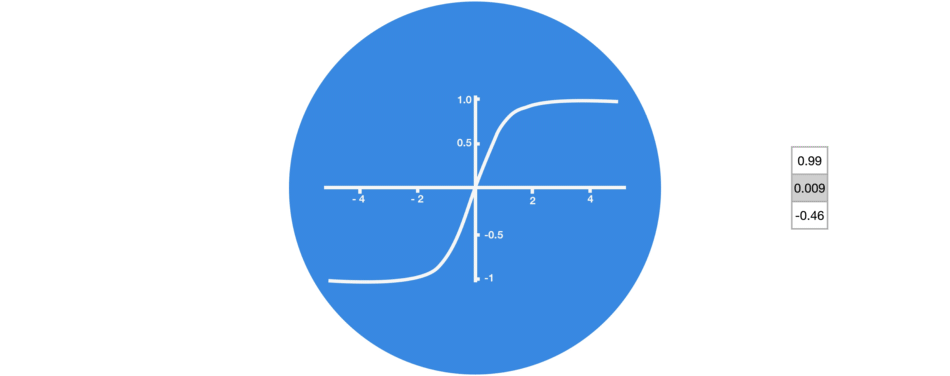
当向量流经神经网络时,由于各种数学运算,它经历了许多变换。假设一个值连续乘以3。你可以看到某些值如何爆炸增长的,导致其他值看起来微不足道。

tanh函数确保值在-1和1之间,从而调节神经网络的输出。你可以看到上面的相同值通过tanh函数保持界限之间。

这是一个RNN。它内部的操作很少,但在适当的情况下(如短序列)工作得很好。RNN使用的计算资源比它的进化变体LSTM和GRU要少得多.
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。如果 RNN 可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 “the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。
但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France… I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
在理论上,RNN 绝对可以处理这样的 长期依赖 问题。人们可以仔细挑选参数来解决这类问题中的最初级形式,但在实践中,RNN 肯定不能够成功学习到这些知识。如果序列过长会导致优化时出现梯度消散的问题。
然而,幸运的是,LSTM 并没有这个问题!
1.2 双向RNN
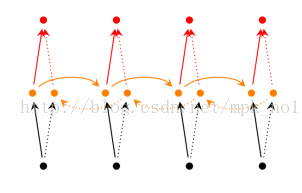
Bidirectional RNN(双向RNN)假设当前t的输出不仅仅和之前的序列有关,并且 还与之后的序列有关,例如:预测一个语句中缺失的词语那么需要根据上下文进 行预测;Bidirectional RNN是一个相对简单的RNNs,由两个RNNs上下叠加在 一起组成。输出由这两个RNNs的隐藏层的状态决定。
1.3 LSTM 网络
Long Short Term Memory 网络—— 一般就叫做 LSTM ——是一种特殊的 RNN 类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
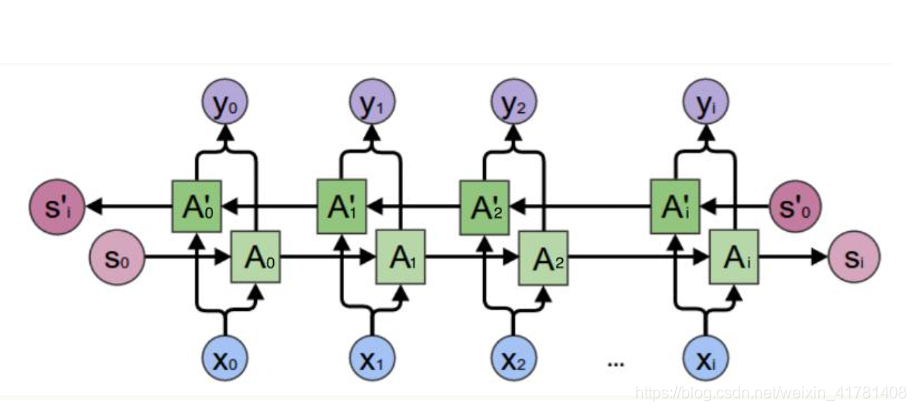
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。LSTM是一种拥有三个“门”结构的特殊网络结构。
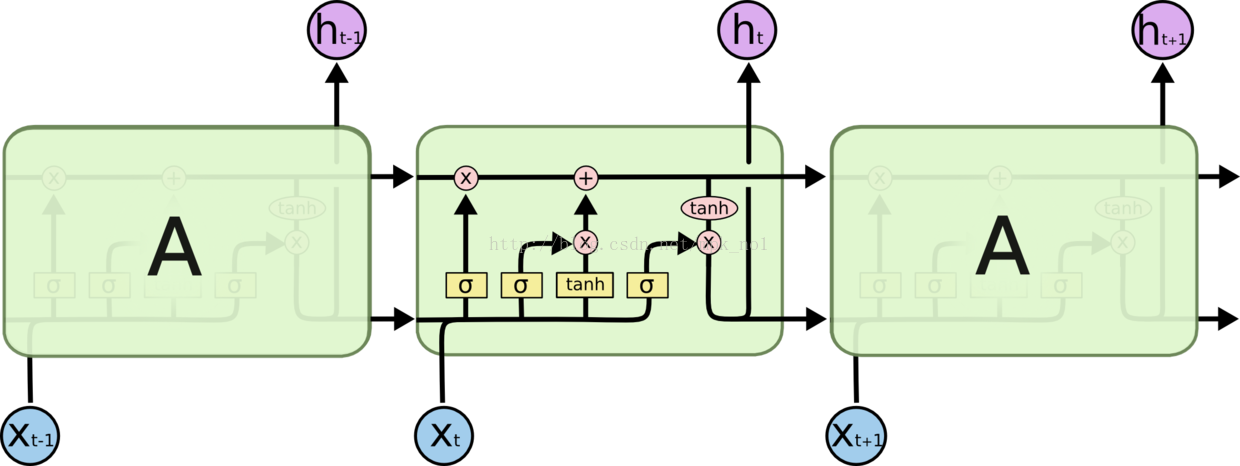
LSTM 靠一些“门”的结构让信息有选择性地影响RNN中每个时刻的状态。所谓“门”的结构就是一个使用sigmod神经网络和一个按位做乘法的操作,这两个操作合在一起就是一个“门”结构。之所以该结构叫做门是因为使用sigmod作为激活函数的全连接神经网络层会输出一个0到1之间的值,描述当前输入有多少信息量可以通过这个结构,于是这个结构的功能就类似于一扇门,当门打开时(sigmod输出为1时),全部信息都可以通过;当门关上时(sigmod输出为0),任何信息都无法通过
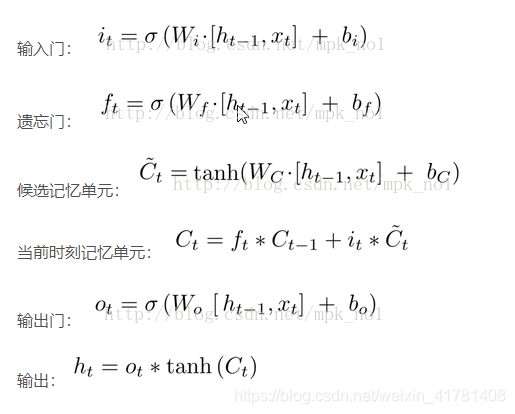
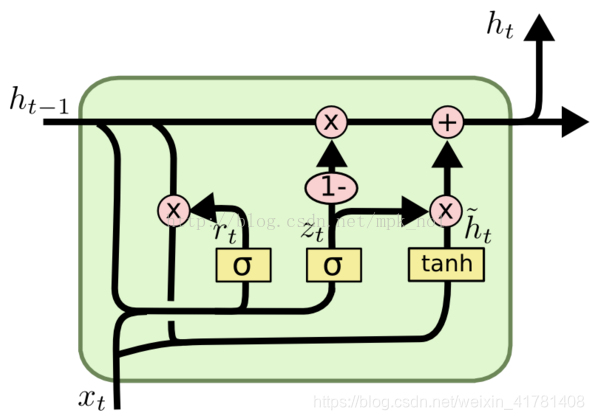
1.4、GRU的结构。
GRU可以看成是LSTM的变种,GRU把LSTM中的遗忘门和输入们用更新门来替代。 把cell state和隐状态ht进行合并,在计算当前时刻新信息的方法和LSTM有所不同。 下图是GRU更新ht的过程:
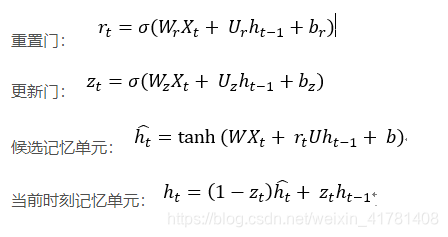
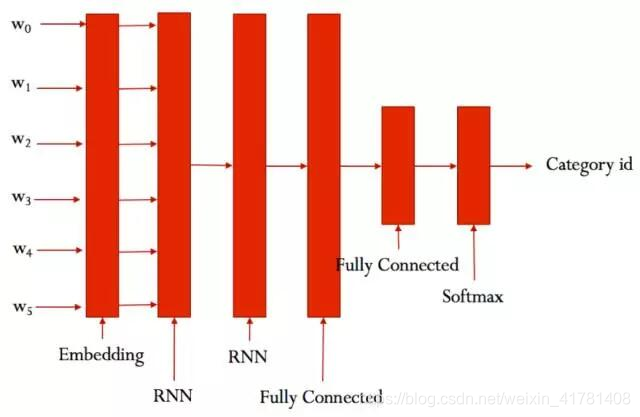
2 利用Text-RNN模型来进行文本分类。
结构:降维—>双向lstm —> concat输出—>平均 -----> softmax
配置项
RNN可配置的参数如下所示,在rnn_model.py中。
class TRNNConfig(object): """RNN配置参数"""
# 模型参数
embedding_dim = 64 # 词向量维度
seq_length = 600 # 序列长度
num_classes = 10 # 类别数
vocab_size = 5000 # 词汇表达小
num_layers= 2 # 隐藏层层数
hidden_dim = 128 # 隐藏层神经元
rnn = 'gru' # lstm 或 gru
dropout_keep_prob = 0.8 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 128 # 每批训练大小
num_epochs = 10 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
RNN模型
具体参看rnn_model.py的实现。
大致结构如下:
运行 python run_rnn.py train,可以开始训练。
Configuring RNN model...
Configuring TensorBoard and Saver...
Loading training and validation data...
Time usage: 0:00:14
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 2.3, Train Acc: 8.59%, Val Loss: 2.3, Val Acc: 11.96%, Time: 0:00:08 *
Iter: 100, Train Loss: 0.95, Train Acc: 64.06%, Val Loss: 1.3, Val Acc: 53.06%, Time: 0:01:15 *
Iter: 200, Train Loss: 0.61, Train Acc: 79.69%, Val Loss: 0.94, Val Acc: 69.88%, Time: 0:02:22 *
Iter: 300, Train Loss: 0.49, Train Acc: 85.16%, Val Loss: 0.63, Val Acc: 81.44%, Time: 0:03:29 *
Epoch: 2
Iter: 400, Train Loss: 0.23, Train Acc: 92.97%, Val Loss: 0.6, Val Acc: 82.86%, Time: 0:04:36 *
Iter: 500, Train Loss: 0.27, Train Acc: 92.97%, Val Loss: 0.47, Val Acc: 86.72%, Time: 0:05:43 *
Iter: 600, Train Loss: 0.13, Train Acc: 98.44%, Val Loss: 0.43, Val Acc: 87.46%, Time: 0:06:50 *
Iter: 700, Train Loss: 0.24, Train Acc: 91.41%, Val Loss: 0.46, Val Acc: 87.12%, Time: 0:07:57
Epoch: 3
Iter: 800, Train Loss: 0.11, Train Acc: 96.09%, Val Loss: 0.49, Val Acc: 87.02%, Time: 0:09:03
Iter: 900, Train Loss: 0.15, Train Acc: 96.09%, Val Loss: 0.55, Val Acc: 85.86%, Time: 0:10:10
Iter: 1000, Train Loss: 0.17, Train Acc: 96.09%, Val Loss: 0.43, Val Acc: 89.44%, Time: 0:11:18 *
Iter: 1100, Train Loss: 0.25, Train Acc: 93.75%, Val Loss: 0.42, Val Acc: 88.98%, Time: 0:12:25
Epoch: 4
Iter: 1200, Train Loss: 0.14, Train Acc: 96.09%, Val Loss: 0.39, Val Acc: 89.82%, Time: 0:13:32 *
Iter: 1300, Train Loss: 0.2, Train Acc: 96.09%, Val Loss: 0.43, Val Acc: 88.68%, Time: 0:14:38
Iter: 1400, Train Loss: 0.012, Train Acc: 100.00%, Val Loss: 0.37, Val Acc: 90.58%, Time: 0:15:45 *
Iter: 1500, Train Loss: 0.15, Train Acc: 96.88%, Val Loss: 0.39, Val Acc: 90.58%, Time: 0:16:52
Epoch: 5
Iter: 1600, Train Loss: 0.075, Train Acc: 97.66%, Val Loss: 0.41, Val Acc: 89.90%, Time: 0:17:59
Iter: 1700, Train Loss: 0.042, Train Acc: 98.44%, Val Loss: 0.41, Val Acc: 90.08%, Time: 0:19:06
Iter: 1800, Train Loss: 0.08, Train Acc: 97.66%, Val Loss: 0.38, Val Acc: 91.36%, Time: 0:20:13 *
Iter: 1900, Train Loss: 0.089, Train Acc: 98.44%, Val Loss: 0.39, Val Acc: 90.18%, Time: 0:21:20
Epoch: 6
Iter: 2000, Train Loss: 0.092, Train Acc: 96.88%, Val Loss: 0.36, Val Acc: 91.42%, Time: 0:22:27 *
Iter: 2100, Train Loss: 0.062, Train Acc: 98.44%, Val Loss: 0.39, Val Acc: 90.56%, Time: 0:23:34
Iter: 2200, Train Loss: 0.053, Train Acc: 98.44%, Val Loss: 0.39, Val Acc: 90.02%, Time: 0:24:41
Iter: 2300, Train Loss: 0.12, Train Acc: 96.09%, Val Loss: 0.37, Val Acc: 90.84%, Time: 0:25:48
Epoch: 7
Iter: 2400, Train Loss: 0.014, Train Acc: 100.00%, Val Loss: 0.41, Val Acc: 90.38%, Time: 0:26:55
Iter: 2500, Train Loss: 0.14, Train Acc: 96.88%, Val Loss: 0.37, Val Acc: 91.22%, Time: 0:28:01
Iter: 2600, Train Loss: 0.11, Train Acc: 96.88%, Val Loss: 0.43, Val Acc: 89.76%, Time: 0:29:08
Iter: 2700, Train Loss: 0.089, Train Acc: 97.66%, Val Loss: 0.37, Val Acc: 91.18%, Time: 0:30:15
Epoch: 8
Iter: 2800, Train Loss: 0.0081, Train Acc: 100.00%, Val Loss: 0.44, Val Acc: 90.66%, Time: 0:31:22
Iter: 2900, Train Loss: 0.017, Train Acc: 100.00%, Val Loss: 0.44, Val Acc: 89.62%, Time: 0:32:29
Iter: 3000, Train Loss: 0.061, Train Acc: 96.88%, Val Loss: 0.43, Val Acc: 90.04%, Time: 0:33:36
No optimization for a long time, auto-stopping...
在验证集上的最佳效果为91.42%,经过了8轮迭代停止,速度相比CNN慢很多。
代码参考:https://github.com/gaussic/text-classification-cnn-rnn
- Recurrent Convolutional Neural Networks(RCNN)原理。